

Linux内核代码60%都是驱动?
描述
一、前言
为什么Linux内核代码60%都是驱动? 如果每支持新的设备就加入驱动,内核会不会变得越来越臃肿?
要先搞明白这个问题,我们首先要明确(区分)两个概念:内核代码和内核,这是两个完全不一样的概念,我们通过 git clone 命令从网上拉取下来的代码叫做内核代码,如果增加新的设备内核代码确实会变得越来越臃肿,这点是肯定的,但是内核并不会变得臃肿,具体原因我们接下里会进行讨论。说了那么多内核代码,那内核是什么呢?为什么内核代码变多了内核却不会变大?
内核 是我们通过交叉编译之后真正烧录到板子里跑起来的代码,而交叉编译的时候,是有选择的进行编译,这里面有顶尖的大神们的智慧结晶,与你硬件相关的才编译,不相关的代码则不会被编译到内核里,所以不是说内核里提交了一个设备的驱动你的内核就会变大,这要看你的硬件有没有用到这个驱动。
二、Linux中避免内核臃肿的措施
我们上面知道了内核是经过我们交叉编译裁剪之后的代码,会有选择性的将对我们有用的代码编译进内核中,不需要的将被舍弃,这是Linux内核开发者智慧的结晶,也是保证内核不会变得臃肿的原因。那除了交叉编译之外还有没有其他的措施来保证内核不会变的越来越大呢?下面就给大家分享几个用来保证内核不臃肿的措施。
2.1 交叉编译及SDK包的裁剪
(这部分稍微有些啰嗦,主要为了让初学者更好的理解,老工程师可以直接跳过啦!)交叉编译是指在一种平台上编译生成在另一种不同平台上运行的可执行程序。在Linux中,常见的情况是在PC主机(Ubuntu系统)上编译生成适用于嵌入式设备或其他架构的目标程序。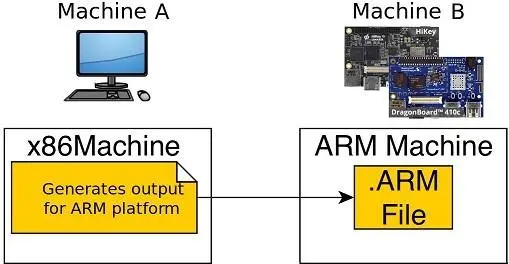
通过上面的介绍我们已经知道了内核代码是会通过交叉编译来进行选择性的将对我们有用的代码编译进内核的,但是交叉编译到底是如何工作的呢?我们应该怎么去配置交叉编译以让我们的内核能过够在稳定运行的基础上尽量小巧呢?
做过嵌入式Linux的应该都清楚,我这里的介绍也主要针对嵌入式Linux来讲解,一般嵌入式Linux的交叉编译工具链都是由SDK包提供商(一般是芯片厂)提供,所以一般不需要我们进行编写和设计,只需要针对自己开发板的实际情况进行裁剪即可。
其实Linux代码到你烧录到板子中的内核代码是经过了下面的过程:
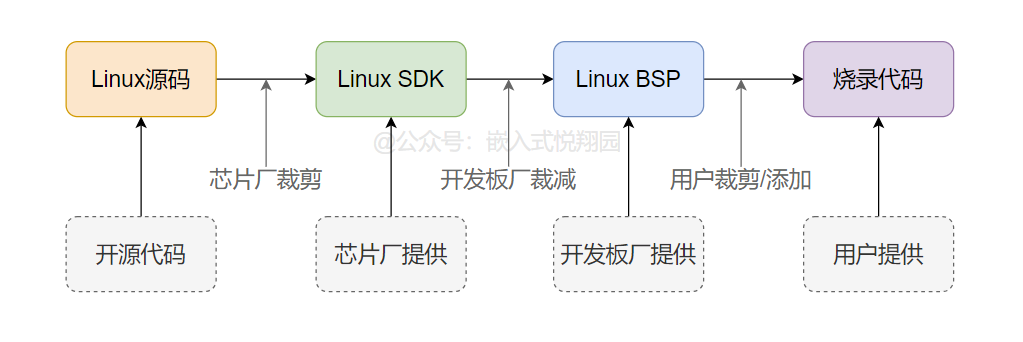
上面的图是我对于一套代码从Linux开源代码一步一步的被裁剪和适配后最终到达用户手中过程的理解,当然不同的厂商这个过程可能有所不同。
所以回到我们的问题,看完上面图片中的过程,你觉得Linux内核中提交了新设备的驱动代码会被烧录到最终烧录到板子中吗?
这里分几种情况来讨论:
如果这个新设备在该款芯片上完全不会用到,那么芯片厂提供的SDK包中就不会包含这个驱动;
如果这个新设备芯片是支持的,但是我这款开发板不支持,那么板厂就不会同步这个设备的驱动;
如果这个新设备在开发板上也是支持的,但是作为用户完全不会用到该设备,那么该设备的驱动也会被裁剪;
所以不是说Linux内核代码中新提交一个设备驱动,该设备驱动就会最终到开发板中,中间是会经过很多筛选的,只有真正对用户有用的代码才会被同步编译和烧录。
这里用户可能会有疑问,讲了半天代码包的裁剪,代码裁剪和交叉编译有什么关系呢?这里还要明确一点,代码的裁剪并不是你想象的直接把代码从代码包中删除了,更多时候是把代码从编译中删除掉,即该设备的驱动并不会被编译到内核中,但是源代码你还是可以看到的。
2.2 设备树
设备树的由来想必大家应该都有所耳闻:
“
ARM社区一贯充斥的大量垃圾代码导致Linus盛怒,因此社区在2011年到2012年进行了大量的工作。ARM Linux开始围绕Device Tree展开,Device Tree有自己的独立的语法,它的源文件为.dts,编译后得到.dtb,Bootloader在引导Linux内核的时候会将.dtb地址告知内核。之后内核会展开Device Tree并创建和注册相关的设备,因此arch/arm/mach-xxx和arch/arm/plat-xxx中大量的用于注册platform、I2C、SPI板级信息的代码被删除,而驱动也以新的方式和.dts中定义的设备结点进行匹配。
”
在设备树出现之前,内核代码中包含了大量与硬件设备相关的配置信息和初始化操作。随着硬件数量和多样性的增加,内核代码变得越来越复杂,难以管理和维护。设备树将硬件描述从内核代码中分离出来,使得内核代码更加清晰简洁,并且与具体硬件解耦。
使用设备树可以在运行时动态地配置硬件设备,而无需修改内核源代码。这点对于代码的调试非常方便,我们自需要重新编译设备树文件放到开发板中即可,而不用重新烧录整个内核。设备树中的硬件描述信息可以根据实际硬件配置进行自由组合和调整,从而达到更好的兼容性和灵活性。
2.3 模块化
Linux内核采用的是模块化设计,通过将功能划分为独立的模块,可以提高代码的可复用性和灵活性。内核模块是一段可以被动态加载到内核中并扩展其功能的代码。它相对独立于内核的其他部分,在需要时可以加载或卸载。
除了动态的加载将通用的功能封装成独立的模块,可以被多个子系统或驱动程序共享和复用,避免了重复编写相同的代码,提高了开发效率。如果看过I2C驱动的话大家应该清楚I2C驱动分为设备驱动和核心驱动,Linux内核已经将I2C驱动的公用代码封装到核心代码中了,其实I2C设备驱动代码只需要简单的调用I2C核心驱动中的接口即可,而不用从0开始完成一个I2C的驱动代码,这样代码的复用率会变高,内核驱动的代码量和代码复杂度也会变小。
2.4 硬件抽象层
硬件抽象层(Hardware Abstraction Layer,HAL)是一种软件层,用于将底层硬件设备的详细实现细节与上层应用程序隔离开来,提供一组统一的接口和功能,以简化对硬件的访问和操作。
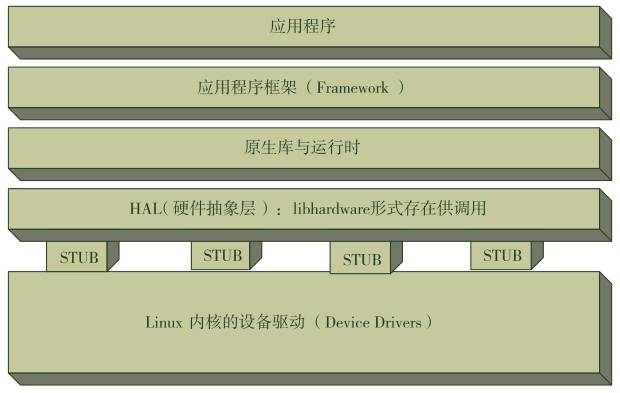
硬件抽象层起到了在不同硬件平台之间建立标准化接口的作用,使得应用程序可以以相似的方式进行硬件访问和控制,而无需关心具体硬件的细节。通过使用硬件抽象层,开发人员可以更加方便地编写跨平台或可移植的应用程序,而不需要针对每个具体硬件设备进行独立的编程。
总的来说硬件抽象层提供了一种中间层的软件抽象,将底层硬件设备的具体实现细节与上层应用程序解耦,为开发人员提供简化的硬件访问接口和功能,以提高应用程序的可移植性和跨平台性。
三、嵌入式Linux的裁剪
其实本文默认说的Linux内核都是说的嵌入式Linux,因为对于像Ubuntu这种系统我也不太清楚。对于嵌入式Linux的裁剪我们上面已经介绍了整个代码包的流程,想必大家已经明白了我们烧录进去的内核是已经通过交叉编译精简过的,所以理论上来说烧录进去的已经是最精简的了。
其实内核裁剪不是我们想象的那么简单,只有道行深的工程师才敢进行内核的裁剪。Linux内核裁剪我也没有做过,所以这部分我留给大佬来补充吧!
四、总结
所以回归最开始的问题,Linux内核代码60%都是驱动?驱动代码不会造成内核臃肿吗?我认为答案是不会,如果你认为会变得越来越臃,可以一起交流一下哦!
审核编辑:刘清
-
如何向Linux内核提交驱动2015-09-08 0
-
Linux内核源代码2010-02-09 501
-
Linux内核源代码漫游2010-02-09 1133
-
Linux 内核源代码2010-02-10 357
-
LINUX内核驱动第三版(中文)2010-03-11 385
-
嵌入式LINUX内核网络栈(源代码)2011-05-12 612
-
基于Linux内核输入子系统的驱动研究2012-09-12 605
-
Linux内核代码感悟2017-09-11 630
-
怎样去读Linux内核源代码2017-10-25 667
-
《Linux设备驱动开发详解》第4章、Linux内核模块2017-10-27 976
-
Linux内核输入子系统的驱动研究2017-10-31 683
-
Linux内核与Android的关系2018-09-09 4408
-
关于Linux的内核代码风格2021-04-25 1559
-
linux内核源代码详解2023-09-06 206
-
Linux内核如何使用结构体和函数指针?2023-09-06 571
全部0条评论

快来发表一下你的评论吧 !
