

RISC-V 跑大模型(二):LLaMA零基础移植教程
描述
这是RISC-V跑大模型系列的第二篇文章,主要教大家如何将LLaMA移植到RISC-V环境里。
1. 环境准备
1)最新版Python
2)确保机器有足够的内存加载完整模型(7B模型需要13~15G)
3)下载原版LLaMA模型和扩展了的中文模型
LLaMA原版模型:
https://ipfs.io/ipfs/Qmb9y5GCkTG7ZzbBWMu2BXwMkzyCKcUjtEKPpgdZ7GEFKm/
2. 模型下载
从LLaMA原版模型地址上下载下述文件(我们使用的是7B):

最后文件下载完成后的结果如下:
3. 加载并启动
1)这一步需要下载llama.cpp,请输入以下命令进行下载和编译:
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make
2)将第二步下载的文件移到llama.cpp/models/下,使用命令:
python3 convert-pth-to-ggml.py models/7B/ 0
3)将.pth模型权重转换为ggml的FP32格式,生成文件路径为models/7B/ggml-model-f32.bin。
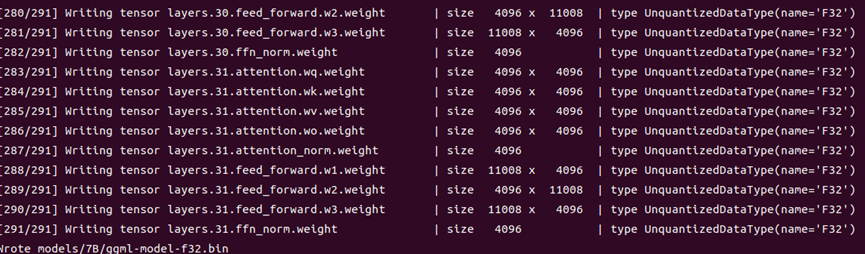
4)运行./main二进制文件,-m命令指定Q4量化模型(也可加载ggml-FP16的模型)。以下是解码参数:
./main models/7B/ggml-model-f32.bin --color -f prompts/alpaca.txt -ins -c 256 --temp 0.2 -n 128 --repeat_penalty 1.3
参数解释:
| -ins | 启动类ChatGPT对话交流的运行模式 |
| -f | 指定prompt模板,alpaca模型请加载prompts/alpaca.txt |
| -c | 控制上下文的长度,值越大越能参考更长的对话历史(默认:512) |
| -n | 控制回复生成的最大长度(默认:128) |
| -t | 控制batch size(默认:8),可适当增加 |
| --repeat_penalty | 控制线程数量(默认:4),可适当增加 |
| --temp | 控制线程数量(默认:4),可适当增加 |
| --top_p, top_k |
控制解码采样的相关数据 |
4.结束
本篇教程到这里就结束了。是不是觉得LLaMA的速度比较慢而且不支持中文,没关系,在下一期中,我们会为LLaMA扩充中文,并优化加速LLaMA,记得继续关注我们哦。
另外,RISC -V跑大模型系列文章计划分为四期:
1. RISC -V跑大模型(一)
2. RISC-V 跑大模型(二):LLaMA零基础移植教程(本篇)
3. LLaMA扩充中文+优化加速(计划)
4. 更多性能优化策略。(计划)
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
为什么选择RISC-V?2020-07-27 0
-
RISC-V跑大模型(二):LLaMA零基础移植教程2023-07-10 798
-
什么是RISC-V2024-02-02 0
-
有用risc-v芯片跑系统的吗?2024-03-29 0
-
移植RISC-V CH32V103R BSP的教程2022-03-14 0
-
如何实现一个RISC-V内核架构的芯片移植工作2022-03-25 0
-
从零开始写RISC-V处理器之一 二 前言 绪论2022-08-22 0
-
每日推荐 | HarmonyOS 从入门到大神资料,从零开始写RISC-V处理器经验连载2022-08-23 0
-
目前国内RISC-V架构的MCU从程序从arm移植到RISC-V难度大吗?2023-03-09 0
-
我了解的RISC-V2023-03-19 0
-
有RISC-V跑uCLinux或者NO MMU的Linux的项目吗?2023-04-03 0
-
赛昉科技成立RISC-V Multimedia SIG,推动openKylin on RISC-V生态发展2023-04-03 0
-
开源risc-v2023-05-06 0
-
安卓上RISC-V,移植成最大阻碍2021-10-14 5451
-
RISC-V 跑大模型(三):LLaMA中文扩展2023-07-17 553
全部0条评论

快来发表一下你的评论吧 !
