

英伟达A100和V100参数对比
电子说
1.2w人已加入
描述
英伟达A100这个AI芯片怎么样?英伟达A100是一款基于英伟达Ampere架构的高性能计算卡,主要面向数据中心和高性能计算领域。其拥有高达6912个CUDA核心和432个Turing Tensor核心,可以实现高达19.5 TFLOPS的FP32浮点性能和156 TFLOPS的深度学习性能。此外,它还支持NVIDIA GPU Boost技术和32GB HBM2显存,能够提供卓越的计算性能和内存宽带。英伟达A100还配备了英伟达的第三代NVLink互连技术和第二代NVSwitch交换机,可以实现高带宽、低延迟的GPU-GPU通信,提升集群中的计算效率。
英伟达A100和V100参数对比
以下是英伟达A100和V100的主要参数对比:
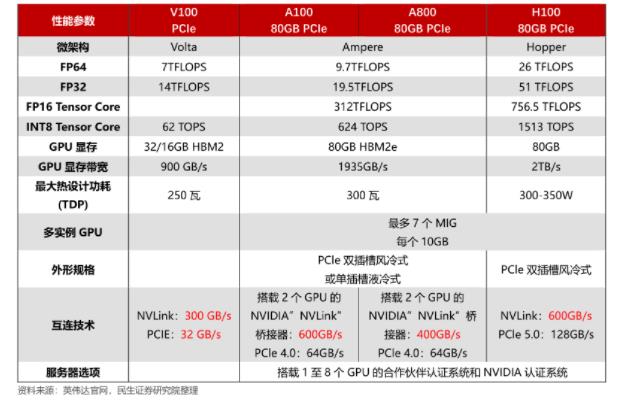
| 参数 | 英伟达 A100 | 英伟达 V100 |
| 架构 | Ampere | Volta |
| 制程 | 7 纳米 | 12 纳米 |
| CUDA 核心数 | 6912 | 5120 |
| Tensor 核心数 | 432 | 640 |
| RTX 加速器数 | 112 | 0 |
| Boost 时钟频率 | 1.41 GHz | 1.38 GHz |
| FP32 性能 | 19.5 TFLOPS | 15.7 TFLOPS |
| FP64 性能 | 9.7 TFLOPS | 7.8 TFLOPS |
| Tensor 性能 | 624.6 TFLOPS | 125 TFLOPS |
| 内存容量 | 40 GB HBM2 | 16 GB HBM2 |
| 内存带宽 | 1.6 TB/s | 900 GB/s |
| TDP | 400 W | 300 W |
| 支持的 PCIe 版本 | PCIe 4.0 | PCIe 3.0 |
| 相关软件支持 | CUDA, cuDNN, TensorRT, NCCL, NVLink, NVSwitch, Docker, Kubernetes | CUDA, cuDNN, TensorRT, NCCL, NVLink, Docker, Kubernetes |
,英伟达 A100 在架构、制程和性能上都有显著的提升,同时内存容量和带宽也大幅提高。另外,A100 支持 RTX 加速器,可以实现实时光线追踪渲染等功能,而 V100 则不支持。不过,A100 的功耗也相应增加,需要更好的散热解决方案。
适用领域 | AI、机器学习、高性能计算 | 虚拟桌面、虚拟应用、多媒体等。
打开APP阅读更多精彩内容
英伟达A100和V100参数对比
以下是英伟达A100和V100的主要参数对比:
| 参数 | 英伟达 A100 | 英伟达 V100 |
| 架构 | Ampere | Volta |
| 制程 | 7 纳米 | 12 纳米 |
| CUDA 核心数 | 6912 | 5120 |
| Tensor 核心数 | 432 | 640 |
| RTX 加速器数 | 112 | 0 |
| Boost 时钟频率 | 1.41 GHz | 1.38 GHz |
| FP32 性能 | 19.5 TFLOPS | 15.7 TFLOPS |
| FP64 性能 | 9.7 TFLOPS | 7.8 TFLOPS |
| Tensor 性能 | 624.6 TFLOPS | 125 TFLOPS |
| 内存容量 | 40 GB HBM2 | 16 GB HBM2 |
| 内存带宽 | 1.6 TB/s | 900 GB/s |
| TDP | 400 W | 300 W |
| 支持的 PCIe 版本 | PCIe 4.0 | PCIe 3.0 |
| 相关软件支持 | CUDA, cuDNN, TensorRT, NCCL, NVLink, NVSwitch, Docker, Kubernetes | CUDA, cuDNN, TensorRT, NCCL, NVLink, Docker, Kubernetes |
,英伟达 A100 在架构、制程和性能上都有显著的提升,同时内存容量和带宽也大幅提高。另外,A100 支持 RTX 加速器,可以实现实时光线追踪渲染等功能,而 V100 则不支持。不过,A100 的功耗也相应增加,需要更好的散热解决方案。
适用领域 | AI、机器学习、高性能计算 | 虚拟桌面、虚拟应用、多媒体等。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
谷歌TPU2和英伟达V100的性能详细对比2018-05-04 10249
-
英伟达a100和h100哪个强?2023-08-07 11555
-
英伟达a100显卡算力介绍2023-08-07 6142
-
英伟达a100和a800参数对比2023-08-07 10629
-
英伟达A100和H100的区别2023-08-07 24483
-
英伟达A100和4090的区别2023-08-08 25330
-
英伟达A100和A40的对比2023-08-08 13536
-
英伟达A100是什么系列?2023-08-08 2344
-
英伟达A100的简介2023-08-08 7746
-
英伟达A100的优势分析2023-08-08 2726
-
英伟达A100的算力是多少?2023-08-08 25535
-
英伟达a100有国产替代吗?2023-08-08 3750
-
英伟达h800和a100参数对比2023-08-08 25579
-
英伟达a100和h100哪个强?英伟达A100和H100的区别2023-08-09 36648
-
英伟达v100与A100的差距有哪些?2023-08-22 16131
全部0条评论

快来发表一下你的评论吧 !
