

基于特征点的SfM在弱纹理场景下的表现
描述
SfM是指给定一组无序图像,恢复出相机位姿以及场景点云。通用场景下的SfM效果已经很好,而且COLMAP这类框架也很好用。但是弱纹理和无纹理场景下的SfM却很麻烦,主要目前主流的SfM框架都是先提取图像中的特征点,然后进行特征匹配。但是在无纹理条件下,很难提取稳定且重复的特征点,这就导致SfM恢复出的位姿和三维点云非常杂乱。
很直接的一个想法就是,如果不提取特征点,直接进行匹配呢?
最近,浙江大学就基于这种思想提出了一种弱纹理场景下的SfM框架,主要流程是首先基于LoFTR这类Detector-Free图像匹配算法获得粗糙位姿和点云,然后使用Transformer多视图匹配算法优化特征点坐标,利用BA和TA进一步优化位姿和点云。这个算法获得了2023 IMC的冠军,整体性能很好。今天笔者就将带领大家一起阅读一下这项工作,当然笔者水平有限,如果有理解不当的地方欢迎大家一起讨论。
1. 效果展示
先来看一下传统基于特征点的SfM在弱纹理场景下的表现:
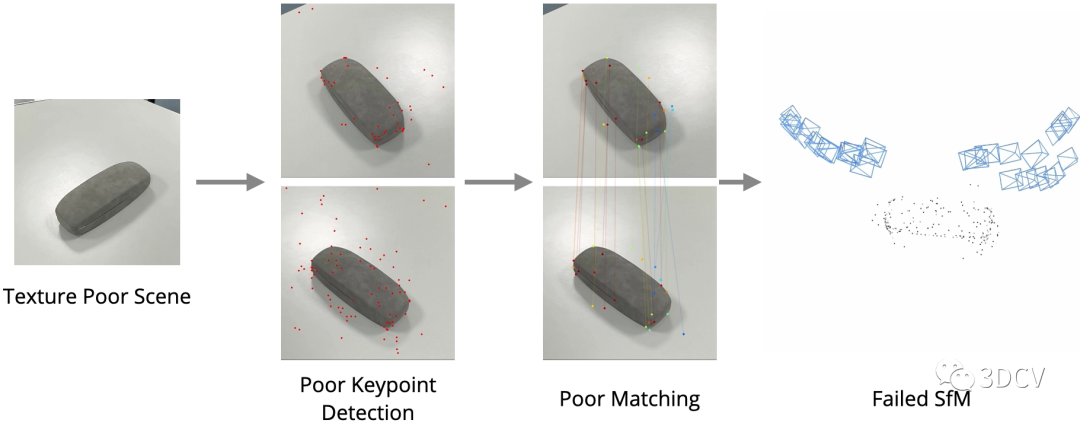
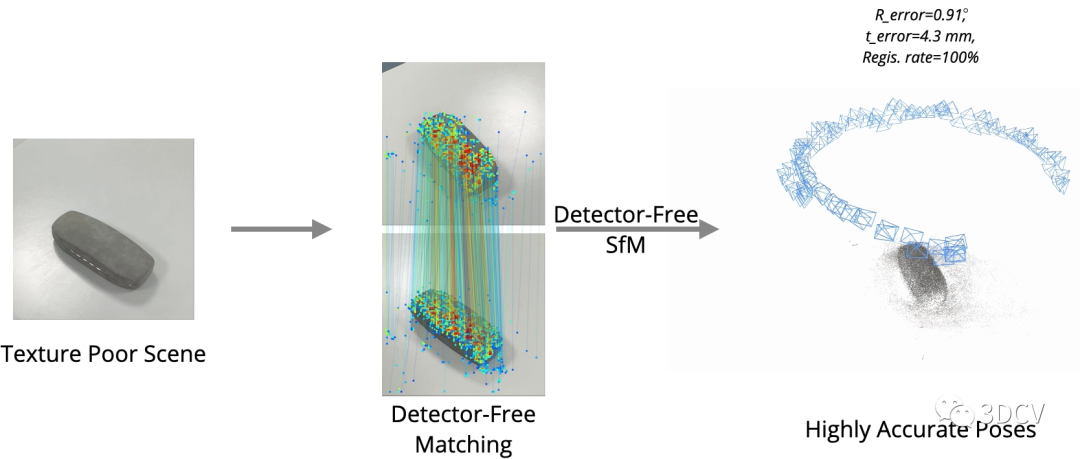
可以发现由于特征点提取的重复性差,匹配性能不好,进一步导致位姿和点云估计的结果很差。那么再来看看Detector-Free SfM这项工作,其主要目的是实现弱纹理场景下的SfM,可以发现在典型场景下运行良好,甚至海底、月球表面这种场景都可以进行定位和重建!推荐学习3D视觉工坊近期开设的课程:国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程

有了精确的位姿和点云,就可以进行很多SfM的下游任务,例如新视点合成和稠密重建:
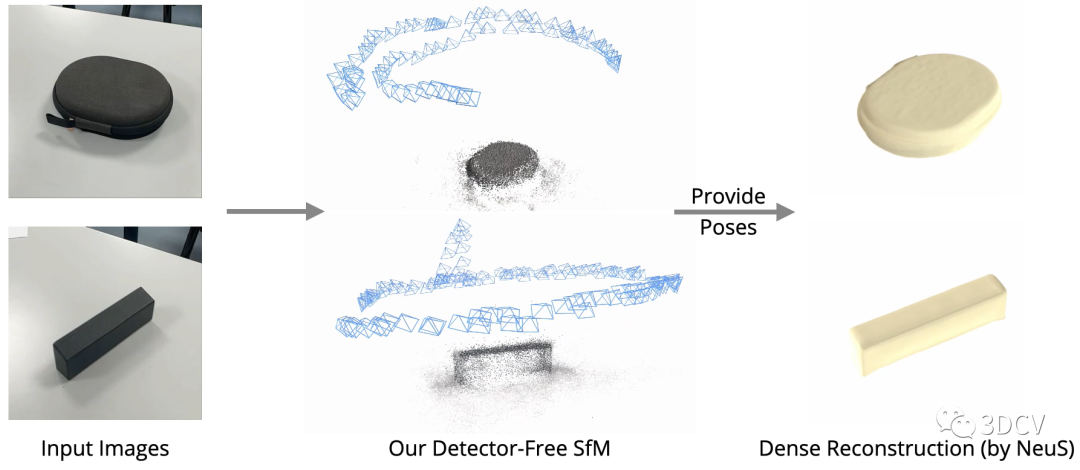
不幸的是,这个算法暂时还没有开源,感兴趣的小伙伴可以追踪一下Github。下面来看一下论文的具体信息。
我们提出了一个新的SfM框架来从无序的图像中恢复精确的相机姿态和点云。传统的SfM系统通常依赖于跨多个视图的可重复特征点的成功检测,这对于弱纹理的场景来说是困难的,并且较差的特征点检测可能会破坏整个SfM系统。受益于最近无检测器匹配器的成功,我们提出了一种新的无检测器SfM框架,避免了早期特征点的确定,同时解决了无检测器匹配器的多视图不一致问题。具体来说,我们的框架首先从量化的无检测器匹配中重建一个粗略的SfM模型。然后,它通过一个新颖的迭代优化管道对模型进行细化,该管道在基于注意力的多视图匹配模块和几何优化模块之间进行迭代,以提高重建精度。实验表明,所提框架在通用基准数据集上优于现有的基于检测器的SfM系统。我们还收集了一个弱纹理的SfM数据集,以展示我们的框架重建弱纹理场景的能力。
2. 算法解析
算法的Pipeline非常直观,输入是一组无序图像,输出是相机位姿、内参和点云。具体的流程是一个两阶段由粗到精的策略,首先使用一个Detector-Free的特征匹配器(LoFTR)来直接进行图像对的稠密匹配,以此来消除特征点的低重复性带来的影响。然后量化特征位置到粗网格来提高一致性,并重建粗SfM模型,为后续优化提供初始的相机位姿和场景结构。之后,使用轨迹优化和几何优化交替进行的联合迭代优化pipeline,以提高位姿和点云精度。
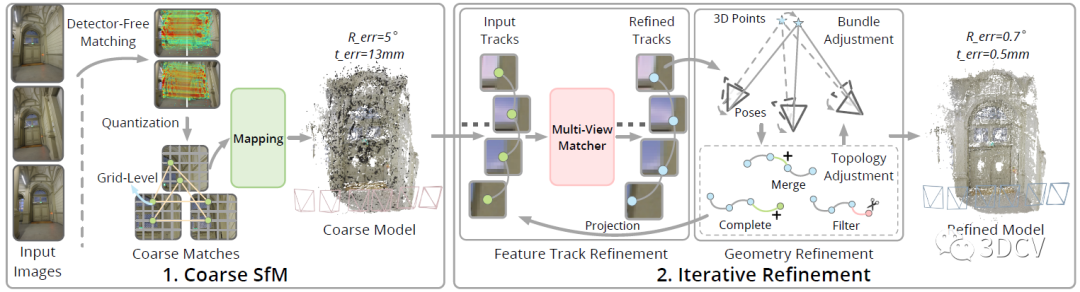
Detector-Free匹配器一般也都采用由粗到精的策略,首先在下采样特征图的粗网格上进行稠密匹配,然后在一幅图像上固定粗匹配的特征位置,而在另一幅图像上用精细的特征图搜索它们的亚像素对应关系。理论上这种思想是可以直接应用到SfM上的,但这里有个问题,也就是在一幅图像中产生的特征位置依赖于另一幅图像,这样在多个视图进行匹配时,特征轨迹就很容易中断!
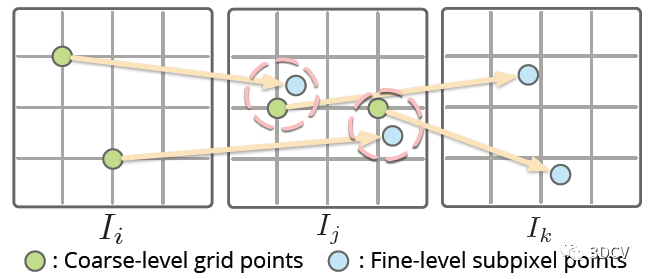
作者的具体做法是,将匹配的2D位置量化为一个网格⌊x / r⌉(r是网格大小),直接令多个相近的子像素合并为同一网格节点。实际上是以牺牲精度为代价,换取了一致性。
后续的迭代优化过程很有意思,优化的对象就是匹配点的2D坐标,主要思想还是对所有视图中的特征点位置进行局部调整,使其特征之间的相关性最大化。
怎么做呢?直接计算所有的关联视图吗?那样计算量就太大了。
作者这里用了一个trick,就是选择一个参考视图,提取参考视图中特征点处的特征,并将其与其他视图(查询视图)中特征点周围大小为p × p的局部特征图进行关联,得到一组p × p的热图,相当于特征点位置的分布。另一方面,还要计算每个热图上的期望和方差,方差之和也就是优化的目标函数。
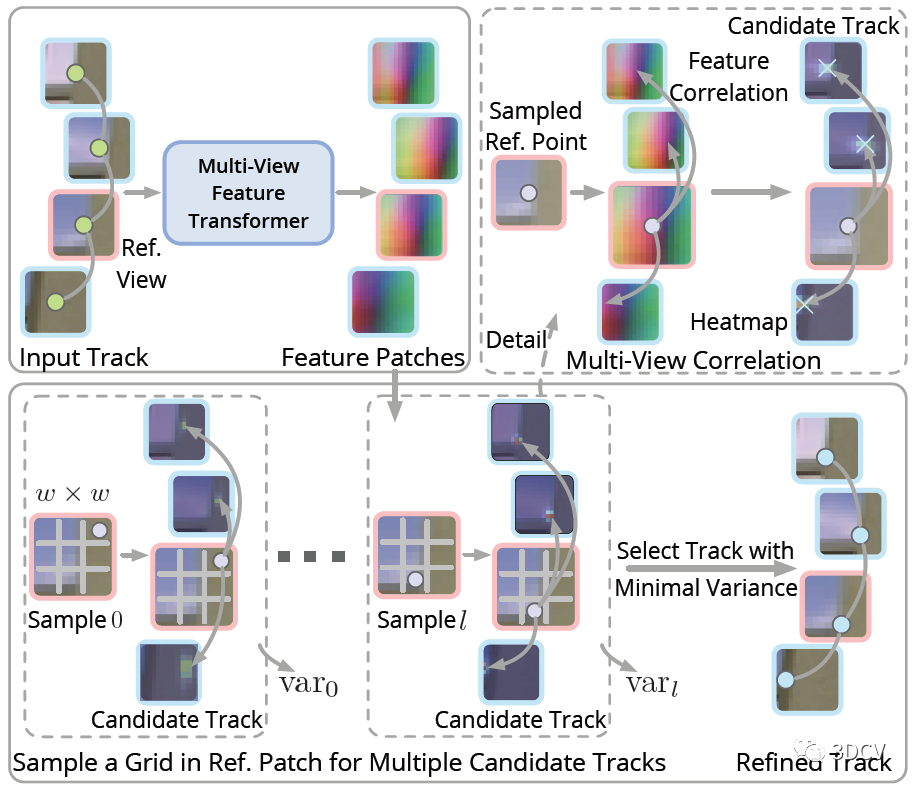
还有个问题,就是这个参考视图怎么选择呢?这里的准则其实是最小化参考视图和查询视图之间的特征点尺度差异。具体来说,就是根据当前恢复的位姿和点云计算特征点的深度值,然后选择中位数做为参考视图。
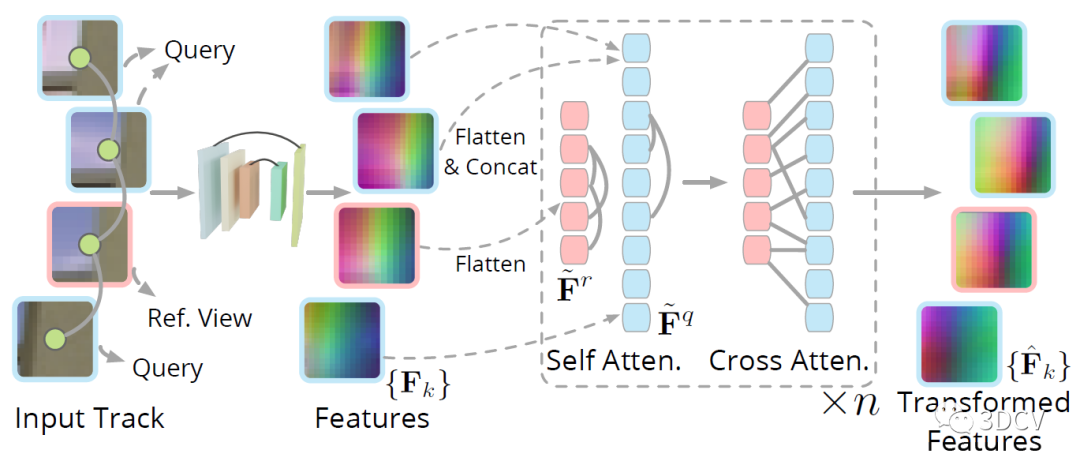
还有个细节,就是如何提取以2D特征点为中心的局部特征块?这里是将以每个关键点为中心的p × p个图像块输入到CNN中,得到一组特征块,然后再利用Transformer的自注意力和交叉注意力得到最终的特征图。
最后还有一个级联的BA和TA(Topology Adjustment)优化的过程,来细化位姿和点云。由于经过了Transformer优化和BA,这时候整体的场景已经比较准确了,因此TA优化过程中还加入了之前未能配准的2D点。整个优化过程,也就是不停的交替进行BA和TA,再把优化后的点云投影到图像上来更新2D位置,再进行下一次迭代优化。
3. 实验
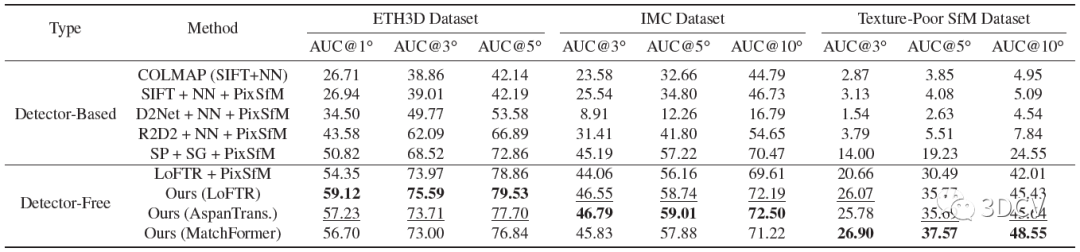
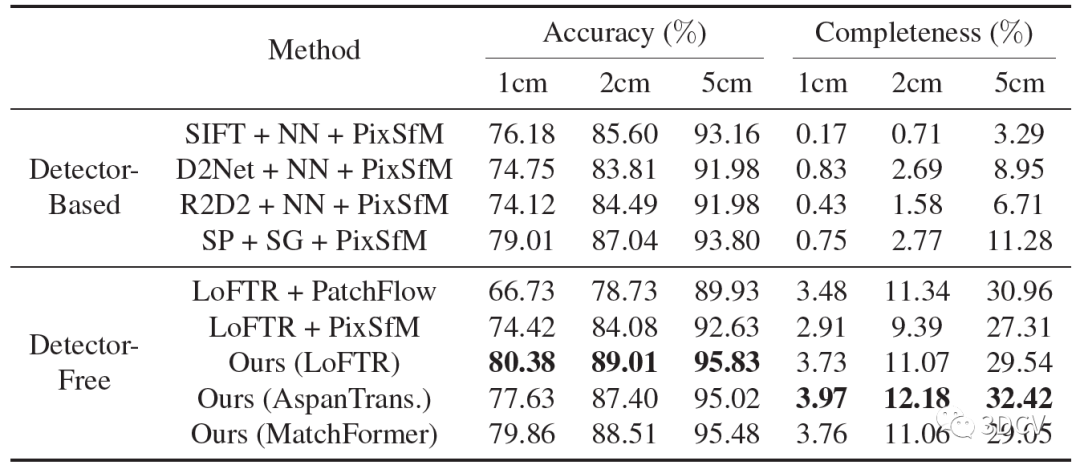
整个模型需要训练的地方就是Detector-Free匹配器还有多视图特征提取Transformer,训练是再MegaDepth数据集进行,训练思路就是最小化优化轨迹和真实轨迹之间特征点位置上的平均l2损失。对比方案还是挺全的,有SIFT这种手工特征点,也有R2D2、SuperPoint这类深度学习特征点,数据方面使用了Image Matching Challenge (IMC)、ETH3D还有他们自己采集的Texture-Poor SfM数据集。
结果显示,这个算法搭配LoFTR可以实现比较好的性能(读者也可尝试和其他的匹配算法结合)。值得注意的是,SuperPoint + SuperGlue + PixSfM这个组合的性能也非常棒,也说明SP+SG在很多情况下都是通用的。
定性的对比就更直观了,红框代表Ground Truth,显然在低纹理场景下这篇文章提出的算法性能更优,甚至好几个场合SP+SG的组合直接挂掉了。
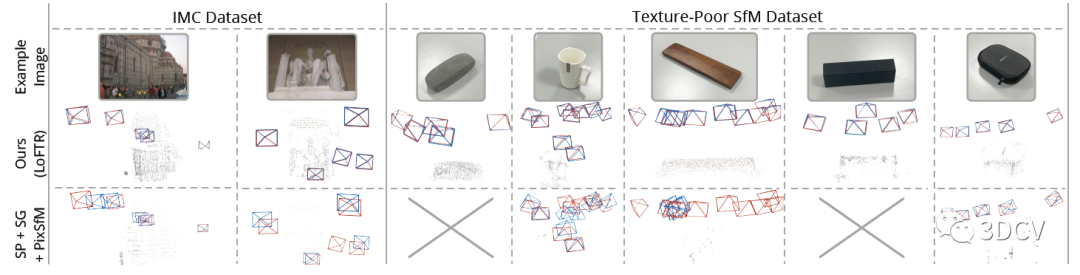
再来看看三角化的结果,可以进一步证明位姿和内参估计的准确性。同样是基于LoFTR的组合取得了更高的精度,这里AspanTrans的配置牺牲了一点精度,但是完整性更好。
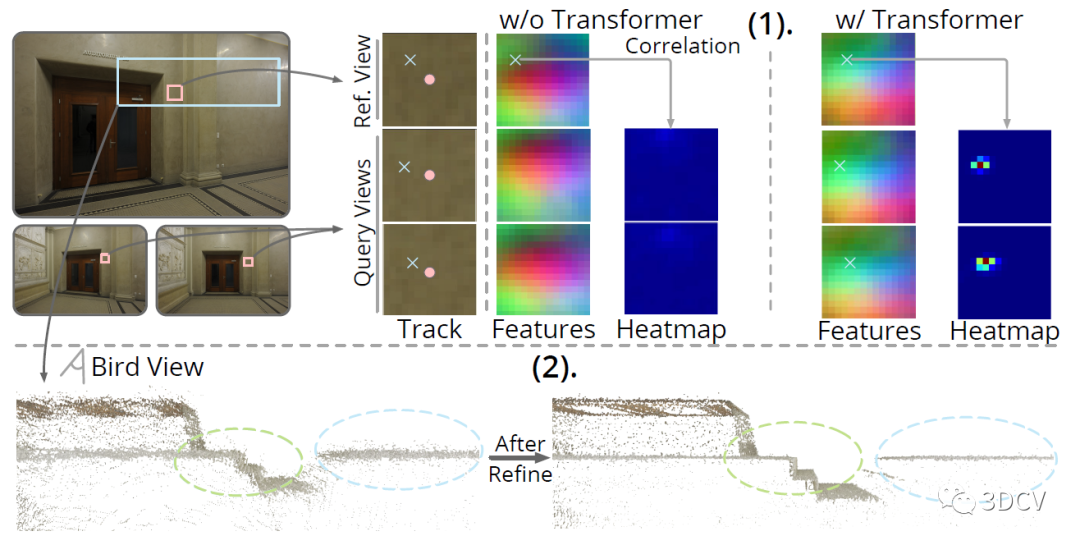
下面是一个验证优化模块影响的实验,做的是热力图的比较,O和X分别表示粗糙和精细的特征点位置。结果显示引入优化后,热力图的对比更明显。而且优化后的点云也更精确。
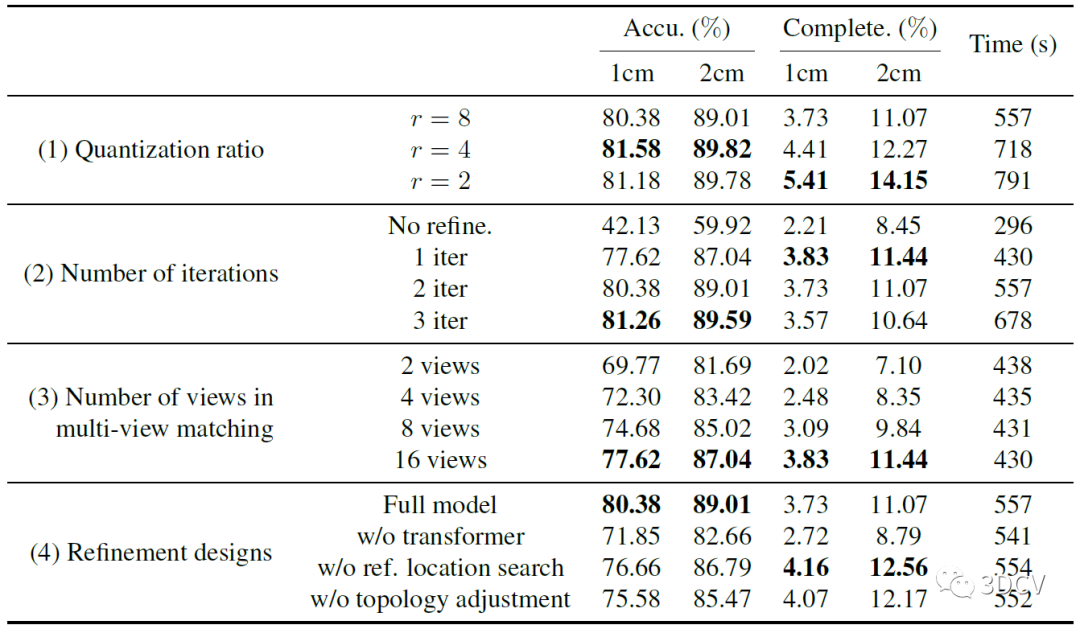
然后是一个消融实验,分别测试的量化比值、迭代次数、视图数量以及各部分模块的消融实验。主要还是通过这组实验确定模型和迭代的最优参数。推荐学习3D视觉工坊近期开设的课程:国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程
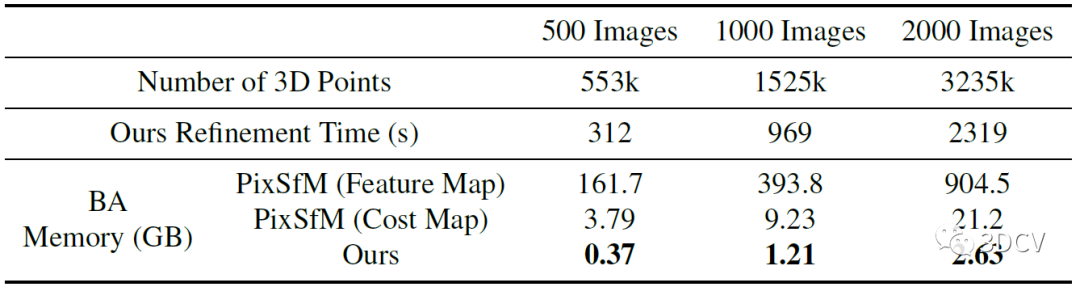
想必大家一定很关心运行的效率和耗时,作者最后做了一个在处理大规模场景时,模型的3D点数、优化时间、内存开销的一个对比。内存占用没有多大,这是因为算法是先进行多视图匹配,再进行几何优化,因此BA不需要像PixSfM那样存储每个2D点的特征块或代价图。
4. 总结
这项工作是针对弱纹理这一特定场景设计的,整体的设计思路很通顺,效果也非常棒。如果要说问题,那就是计算效率了,毕竟LoFTR匹配本身就非常耗时。但本身SfM就不像SLAM那样追求实时性,所以计算效率倒也不是什么大问题,可以尝试通过一些并行BA的方法来优化。另一方面,作者提到可以和深度图、IMU等多模态数据进行融合,也是很不错的研究方向。
审核编辑:彭菁
-
图像纹理的特征与分类2019-04-30 0
-
纹理图像的特征是什么?2021-06-02 0
-
讨论纹理分析在图像分类中的重要性及其在深度学习中使用纹理分析2022-10-26 0
-
虚幻引擎的纹理最佳实践2023-08-28 0
-
基于Contourlet特征修正的纹理图像识别算法2009-04-09 449
-
基于兴趣点颜色及纹理特征的图像检索算法2009-04-23 681
-
纹理特征分析及特征量计算2009-03-01 1977
-
纹理特征提取方法2012-02-22 700
-
基于LBP纹理特征的随机游走图像分割2017-01-07 687
-
一种对野值鲁棒的纹理特征提取方法2017-11-02 759
-
基于纹理特征匹配的快速目标分割方法2017-12-07 702
-
结合颜色和纹理特征的图像检索算法2017-12-18 665
-
一种激光雷达增强的SfM流程2021-01-07 2610
-
Global SfM和ncremental SfM知识讲解2022-12-30 1140
-
分享一种基于深度图像梯度的线特征提取算法download2023-01-08 899
全部0条评论

快来发表一下你的评论吧 !
