

NVIDIA 携手腾讯开发和优化 Spark UCX 实现性能跃升
描述
什么是 Spark 平台?
TDW-Spark 是腾讯公司级数据平台,是腾讯海量数据处理平台中最核心的模块,支持百 PB 级的数据存储和计算,业务涉及公司各个 BG,为腾讯公司提供海量、高效、稳定的大数据平台支撑和决策支持,是腾讯公司最大的离线数据处理平台。
Spark 业务所面临的挑战
Spark 网络目前的现状包括大规模部署 QP 连接数不够用,使用 RDMA DC 解决连接数过多的问题;Spark 不同应用场景需要不同的 EP 个数、RPC 调用次数、Spark UCX 线程数、Block 大小等,需要联合调配;RDMA 和 TCP 混合部署,需要兼容和故障逃生;以及网络带宽低,需要提升带宽,降低延时。
Spark 原始的业务问题包括:
-
通信耗时占比高:Spark Shuffle 时间占 Spark 运行总时间的 30% - 40%,造成 Spark 任务完成时间长。
-
业务需求:网络 IO 和磁盘 IO 是 Spark Shuffle 的瓶颈,需要提高通信效 率,提高计算效率。
-
降本增效:五万张已经部署的 NVIDIA ConnectX-5 网卡需要提高性能利用率,切换到 RDMA,提高业务带宽。
为了应对上述问题及挑战,腾讯进行了 Spark RDMA 大规模部署网络的工作,主要从两个方面着手:Spark RDMA 网络部署和优化,以及 Spark UCX / UCX 性能优化。
Spark RDMA 网络部署和调优
具体部署调优步骤:
-
搭建 37 节点 NVIDIA ConnectX-5 网卡和 26 节点 NVIDIA ConnectX-6 网卡 Spark 环境,部署 Spark、Spark UCX、UCX 代码进行长稳调优。
-
基于 GroupByTest 和现网 Spark 业务流量,在 UCX、Spark UCX、Spark 三个层次调优对比 DC、RC 和 TCP 效果。
-
优化 Spark UCX、UCX 代码,根据 Spark 业务调优网卡和交换机配置。
-
通过在 NVIDIA ConnectX-5 和 NVIDIA ConnectX-6 Dx bond 引入 DCT,提升 Spark 业务带宽利用率。
-
RDMA 和 TCP 网络共存的情况下,保障长稳运行和 RDMA 故障逃生。
图 1:37 节点的 ConnectX-5 机群与 26 节点的 ConnectX-6 机群
RDMA 部署优化完成情况:
-
大规模:使用 DCT 技术共享 QP 连接,解决了大规模 QP 不够用 的问题。大规模仿真下 Spark 应用 RDMA 网络满足预期。
-
Spark 应用和网络联合调优:实现了最优的网卡和交换机配置,以 及 Spark 任务配置,降低了 15% - 20% 左右的读完成时间。
-
故障逃生:Spark UCX 和 UCX 代码层面实现了 RDMA 和 TCP 通道备份。确保 RDMA 故障逃生 TCP,保证稳定运行。
-
稳定性保证:开发了驱动版本检测、网卡配置和检测、自动化安装升级检测功能。开发了测试网络性能模块,保证 Spark RDMA 各层带宽和延时满足预期。
Spark UCX 性能优化
1. 参数调优:通过调整 maxReqsInFlight、numListenerThreads 等 Spark / Spark UCX 参数,提升任务执行效率,获得最好传输速率,发挥最大系统效能。
2. CPU 利用率优化:启用 sleep / wakeup 特性,替代 busy waiting 模式。让出 CPU 给 Spark 计算任务,减少了 CPU 浪费,体现了 RDMA 的优势。
3. 网路 IO 优化:网路 IO 由阻塞模型改为非阻塞模型,数据接收由同步等待改为异步通知。避免了因为网路 IO 等待而 阻塞计算任务执行,提高了每个线程的任务吞吐量,提升了收发效率和带宽。
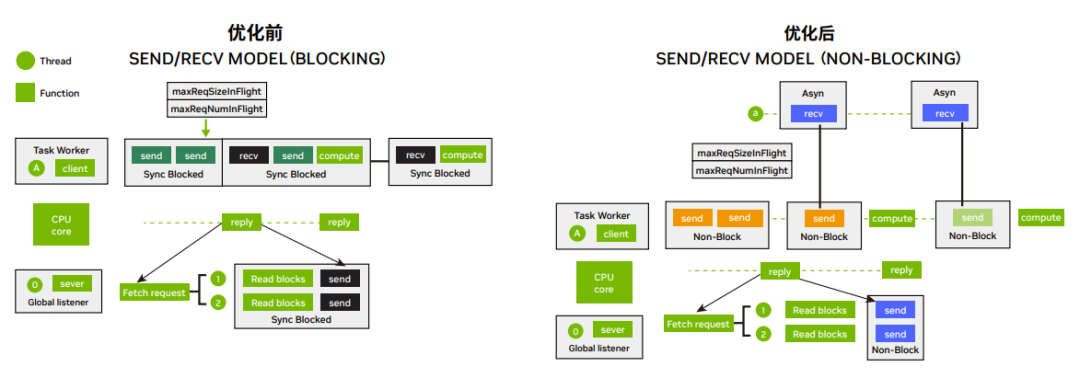
图 2:网络 IO 优化
4. 调度优化:worker 的调度方式改用全局 round-robin (RR) 调度模式,替代原有的按照 thread id 选择 worker 的 方式。避免了 thread id 不连续引起的多个线程选择同一 worker 的问题。
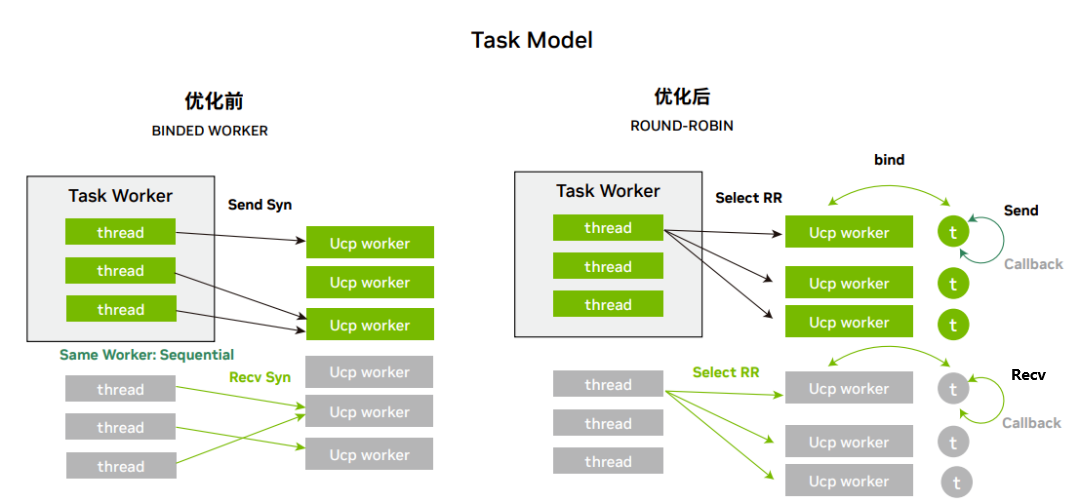
图 3:调度优化
5. 数据竞争优化:将 send / receive / progress 方法打包至独立线程运行,保证每个 worker 资源仅被单个线程 访问 / 修改,避免了数据竞争,提升了线程运行效率。
UCX 性能优化
1. 参数调优:使用 DC 替换 RC 模式,提升传输带宽,减少系统 CPU、内存资源消耗。开启 CQE zipping 和 PCI relax ordering 减少 PCI 负载。调整 UCX_ZCOPY_THRESH、UCX_RNDV_THRESH 和 UCX_RND_SCHEME,获得稳定高速的传输带宽。
2. 网络负载均衡优化:随机化 UDP 源端口取值,减轻由于固定端口,交换机对 5 元组哈希得到相同出端口而引起的 负载不均衡问题,优化网络传输带宽。
“Spark UCX 是 Apache Spark 的高性能 Shuffle Manager 插件,它使用 UCX 支持的 RDMA 和其他高性能传输来加速 Spark 作业中的 Shuffle 数据传输。RDMA DC(动态连接)是一种传输服务,旨在解决大型系统在使用可靠连接时的可扩展性问题。使用 DC,用户可以打开有限数量的资源,无论集群大小如何。这一优势对于 Spark 如此大规模的应用程序来说非常有好处,并且可以提高性能。”
—— Amit Krig
SVP, Software Engineering & Israel R&D Site Leader, NVIDIA
部署调优后性能提升明显
经过部署调优,NVIDIA ConnectX-6 环境 RDMA 传输性能比 TCP 平均有 18% 的提升;NVIDIA ConnectX-5 环境大部分场景 RDMA 传输性能比 TCP 平均有 16% 的提升。考虑到 Spark 任务有计算和本地 write,所以对 Spark 任务整体完成时间大概有 8% 的性能提升。
NVIDIA ConnetX-6 环境 RDMA 性能提升明显(RDMA read 通信 18% 左右提升,整体完成时间 8% 左右提升),可以大规模灰度部署 Spark 业务真实流量。NVIDIA ConnectX-5 环境大部分场景性能平均提升(RDMA read 通信 16% 左右提升,整体完成时间 6% 左右提升),部分场景 RDMA 性能较差还需要调测优化,可以灰度部署 Spark 业务,继续优化还有提升空间。
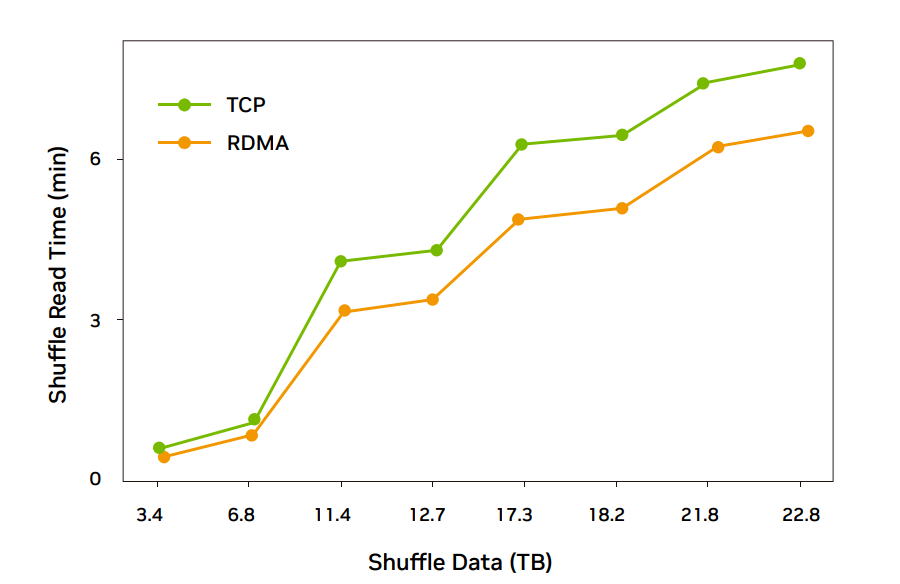
图 4:ConnectX-6 网卡 26 台规模 RDMA 完成时间比 TCP 低 20% 左右
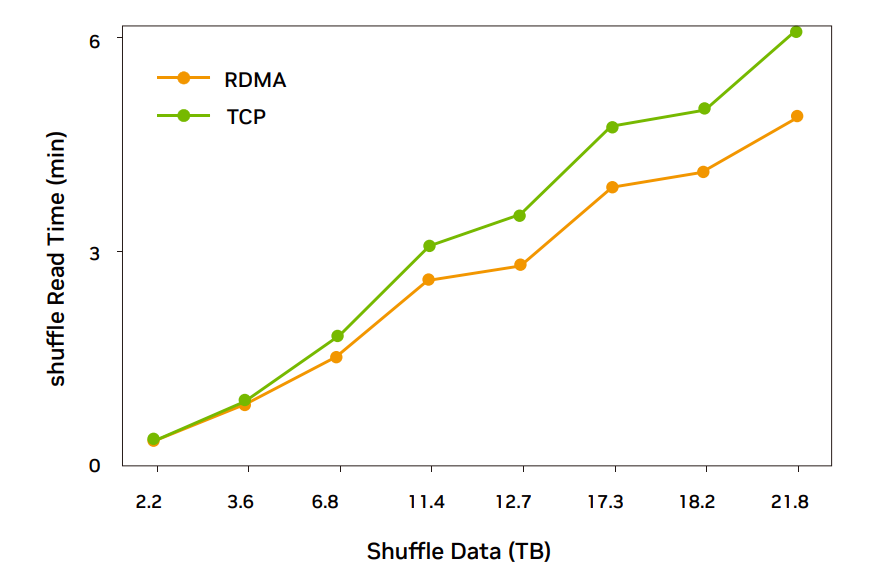
图 5:ConnectX-5 网卡 37 台规模 RDMA 完成时间比 TCP 低 18% 左右

图 6:20 台规模 Spark 业务灰度测试,RDMA read 平均降低 20% 左右
后期计划
Spark 项目通过远程直接内存访问(RDMA)技术解决网络传输中服务器数据处理延迟问题,为腾讯 Spark 大数据平台业务提供高带宽、低延时的通信。该技术已在二十多台腾讯 Spark 大数据平台服务器完成灰度测试,运行稳定且 Spark Shuffle(数据读取速率)时间平均降低 15% - 18% 左右,减少了 Spark 任务完成时间(大约 8% 左右),节约了服务器资源。计划逐步部署到数千台 Spark 服务器。
点击 “阅读原文” 或扫描下方海报二维码,注册 NVIDIA DOCA 应用代码分享活动,为新一代 AI 驱动的数据中心、高性能计算及云计算基础设施带来前所未有的创新。
原文标题:NVIDIA 携手腾讯开发和优化 Spark UCX 实现性能跃升
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 英伟达
-
NVIDIA火热招聘GPU高性能计算架构师2017-09-01 0
-
大数据开发之spark应用场景2018-04-10 0
-
如何在vGPU环境中优化GPU性能2018-09-29 0
-
Spark SQL的工作原理和性能优化2019-06-12 0
-
基于RDMA技术的Spark Shuffle性能提升2019-10-28 0
-
基于Spark的BIRCH算法并行化的设计与实现2017-11-23 837
-
基于Spark的ItemBased推荐算法性能优化2017-11-30 410
-
基于Spark的并行蚁群优化算法2018-01-02 618
-
Spark优化:小文件合并的步骤2020-08-13 7140
-
广和通携手腾讯云共同挖掘物联网中速率市场新风口2021-03-10 189
-
NVIDIA RDMA网络方案助力远端计算和存储网络优化2022-01-04 1330
-
NVIDIA RDMA 网络方案赋能数据库业务持续发展2022-01-04 1299
-
NVIDIA携手腾讯云共同打造高性能的音视频解决方案2022-09-01 552
-
SPARK语言可否取代 C语言?2022-11-23 720
-
NVIDIA 助力 DeepRec 为 vivo 推荐业务实现高性能 GPU 推理优化2023-01-18 585
全部0条评论

快来发表一下你的评论吧 !
