

INT8量子化PyTorch x86处理器
电子说
描述
依英特尔
概览概览
INT8 量子化是加速在x86 CPU平台上进行深层学习推断的有力技术。 通过将模型的重量和活化的精确度从32位浮点(FP32)降低到8位整数(INT8 ) , INT8 量子化可以显著提高推论速度,降低内存要求,同时又不牺牲准确性。
我们将讨论PyTorrch公司x86 CPU 的INT8 量化的最新进展, 重点是新的x86 量化后端。 我们还将简要审视与 PyTorrch 2. 0 Export (PT2E) 和TrchInducor公司(TrchInducor) 的新的量化路径。
X86 量化后端
PyTorrch目前建议的量化方式是:FX在 PyTorrch 2. 0 之前,x86 CPU 的默认量化后端(a.k.a.a. QEngine)是FBGEMM,它利用FBGEM 性能库实现性能加速。在PyTorch 2.0 版中,引入了名为 X86 的新量化后端,以取代FBGEMM。x86 量化后端提供与FBGEM 原始后端相比,通过利用FBGEM和F英特尔-一ANAPI 深神经网络图书馆( oneDNN)内核图书馆。
X86 后端的性能收益
为了衡量新的X86后端后端的绩效效益,我们根据69个流行的深深学习模式(见图1-3(以下) 使用第4 Genen Intelé Xeon可缩放处理器。结果显示,与FP32 的推论性能相比,地平面性能加速2.97X,而FBGEMM后端的加速度为1.43X。下图显示,与x86 后端和FBGEMM后端相比,每个模型性能加速度是每模型性能加速度。
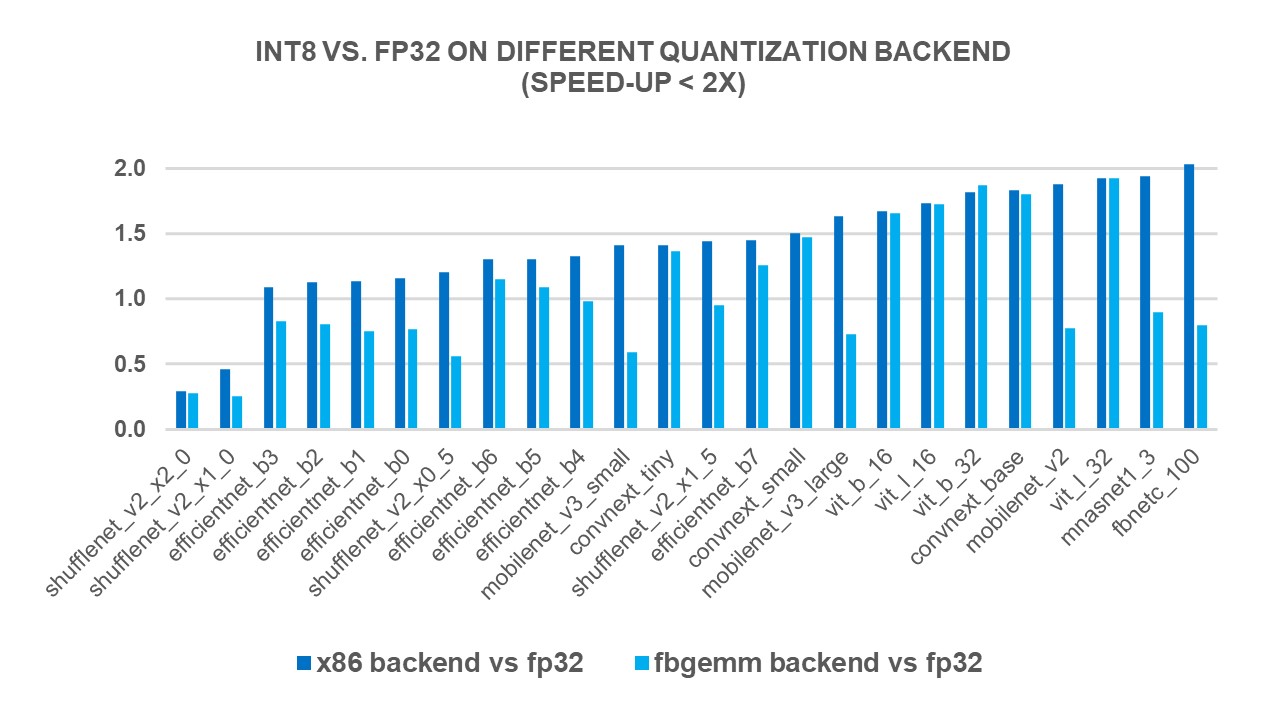
图1 图1: 使用 x86 后端1 的不小于 2x 的性能促进模型1
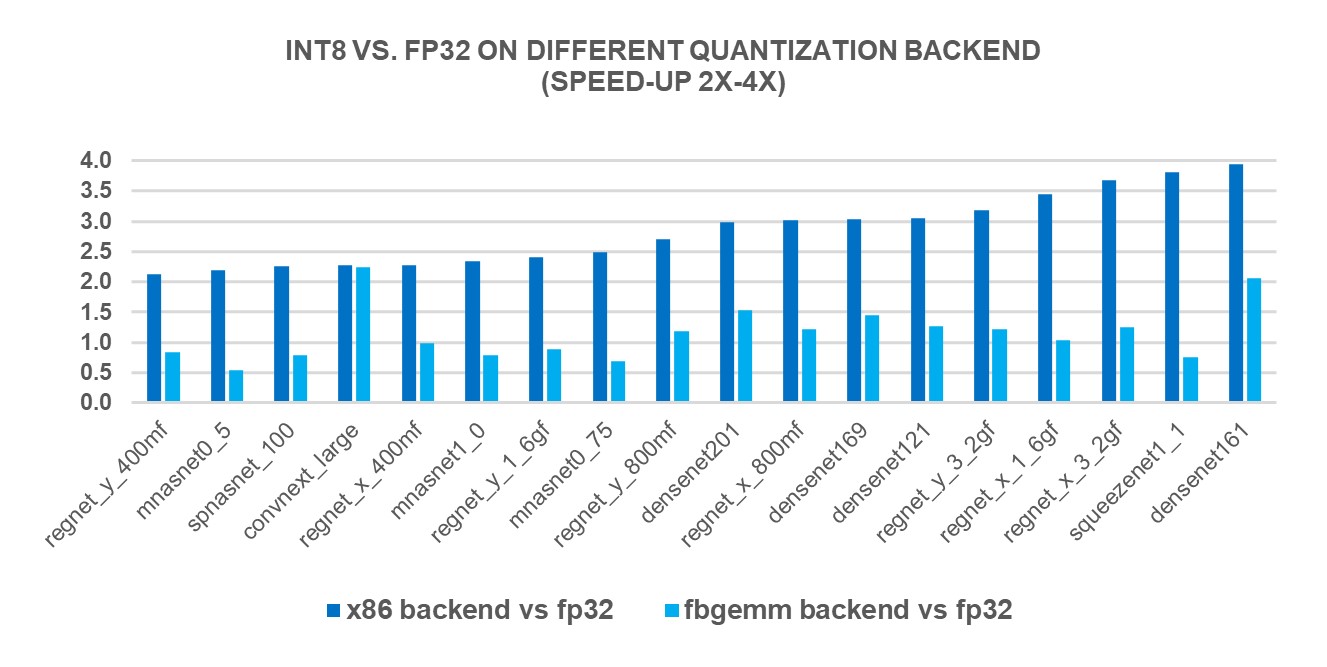
图2 图2: 2x-4x 286 后端1 的 2x-4x 性能助推模型
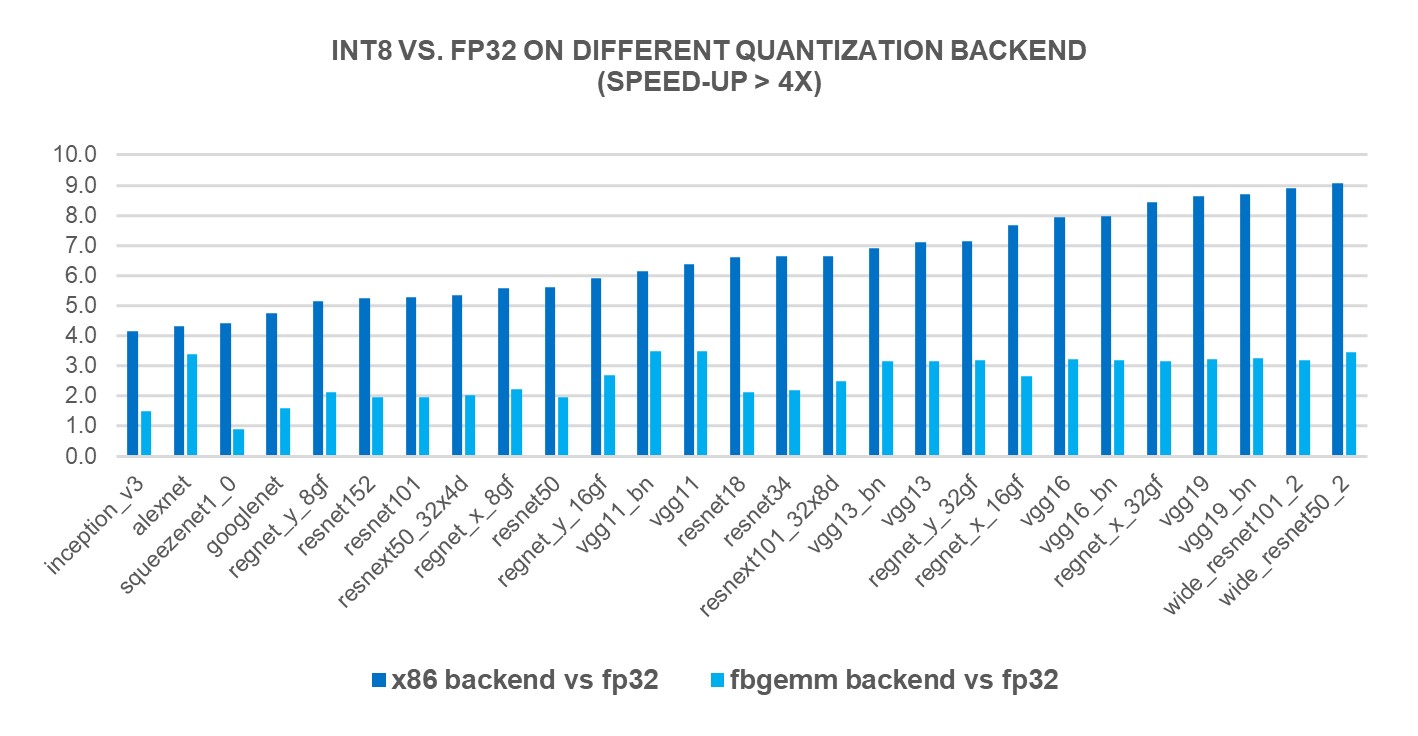
图3 图3: 具有 x86 后端1 的大于 4x 性能助推的模型1
x86 后端的使用
默认值为 2.0 时, x86 平台上的用户将使用 x86 的量化后端, 而使用默认后端时他们的 PyTorrch 程序将保持不变。 或者, 用户可以指定 x86 为明确的量化后端 。
下面是PyTorrch 静态训练后量化的代码片段, 带有 x86 量化后端 。
从 cherch.ao. quantization 导入的点火炬 获取 _ default_ qconfig_ 映射来自 rch. quantization. quantize_ fx 导入准备_ fx, 转换_ fx qconfig_mapping = get_ default_ qconfig_mapping ()
x86 后端技术细节
我们根据我们基准模型的性能数字设计了超速发送规则,以决定是否援引一个DNN 或FBGEMM 性能图书馆来实施演进或矩阵乘法操作。这些规则是操作种类、形状、CPU架构信息等组合。在这里关于更多的设计和技术讨论,请参看以下文件:征求评论意见.
下一个步骤, 带有新的量化路径 PyTorch 2. 0 导出
新的量化路径,即PyTorrch 2. 0 Export (PT2E),虽然还远未最后确定,但还处于早期设计和PoC阶段。新的方法将在未来取代FX量化路径。它以TrchDymona Export 的能力为基础,这是PyTorrch 2.0 发布FX 图形时引入的一个特性。这个图随后被量化并降为不同的后端。TrchIngentor,即新的DL PyTorrch 编译器,在FP32 加速x86 CPU的速度方面已经显示出有希望的结果。我们正积极努力使它成为PT2E 的量化后端之一。我们认为,新的路径将导致INT8 推论性表现的进一步改善,因为不同层次的熔化更加灵活。
结语
PyTorrch 2.0 版中引入的x86 后端显示,在x86 CPU平台上INT8 的推断速度有了显著改善。 与原始的FBGEMM后端相比,它提供了1.43X的加速速度,同时保持了后向兼容性。 这一增强可以使终端用户受益,而其程序只需略微修改或不作任何修改。 此外,目前正在开发一个新的量化路径,即PT2E, 正在开发之中, 并有望在未来提供更多的可能性 。
承认
特别感谢Nikita Sulga、Vasiliy Kuznetsov、Supriya Rao和Jongsoo公园。 我们一起在改善PyToch CPU生态系统的道路上又向前迈出了一步。
配置
1AWS EC2 r 7iz. metal-16xl situ (Intel(R) Xeon(R) Gold 6455B, 32-core/64-thread, Turbo Boft On, 超导, 内存: 8x64GB, 储存: 192GB); OS: Ubuntu 22.04.1 LTS; Kernel: 5.1.50-1028-aws; 批量大小:1; 核心每例: 4; PyTorch 2.0 RC3; 火炬Vision 0.1.0 cpu, Intel于 3/77/2023 进行测试, 5月没有反映所有公开的安全最新情况。
审核编辑:汤梓红
-
基于Cortex-A8处理器的嵌入式wince工控机2012-04-06 0
-
分享:中国造ARM架构处理器:完胜英特尔x86处理器?2015-11-19 0
-
从移动到桌面—ARM挑战X862016-08-31 0
-
arm还是x86?未来在工业SBC数字谁可以脱颖而出2019-04-23 0
-
Intel 64处理器的基本运行环境2019-05-22 0
-
Intel 64x86_64IA-32x86处理器的64位执行环境2019-06-06 0
-
适用于x86架构的快速启动步骤是什么?2020-03-20 0
-
请问14纳米的ARM 处理器和14纳米的X86移动处理器那个更省电?2020-07-14 0
-
32位处理器的开发与8位处理器的开发有哪些明显的不同?2021-04-19 0
-
Cortex-M3处理器是什么2021-07-16 0
-
Powerpc架构与X86架构的区别2021-07-26 0
-
相较于x86架构,华为鲲鹏处理器的优势有哪些2021-10-25 0
-
STM32的核心Cortex-M3处理器的标准化是什么意思2021-12-06 0
-
RK3399处理器与AR9201处理器有哪些不同之处呢2022-02-21 0
-
Arm Cortex-R82处理器技术参考手册2023-08-17 0
全部0条评论

快来发表一下你的评论吧 !
