

使用PyTorch加速图像分割
电子说
描述
依英特尔
使用 Intel 扩展 PyTorrch 来提升图像处理性能
PyTorrch提供了巨大的CPU性能,并且随着PyTorrch的Intel扩展而可以进一步加速。 我用PyTorrch 1.13.1(与ResNet34 Ulet 结构)培训了一个AI图像分割模型,以便从卫星图象中确定道路和速度限制,所有这些都在第四Gen Intelé Xeon可缩放处理器上进行。
我会带你们走走这些步骤 与一个称为SpaceNet5的卫星图像数据集合作 以及如何优化代码 使CPU的深层学习工作量
在我们开始之前,一些家务...
本条所附的代码可在下列文件的示例文件夹中查阅:PyTorrch 仓库的 Intel 扩展. 我从从卫星图像(CRESI)储存库中抽取城市规模道路。 我对它进行了改造, 以适应第四 Gentel Xeon 处理器, 以及PyTorrch 优化和PyTorch 的 Intel 扩展名优化。 特别是,我能够利用这里的笔记本.
你可以找到我给你的随同谈话在YouTube上.
我强烈建议这些文章详细解释如何开始使用SpaceNet5数据:
空间网5基线——第1部分:图像和标签准备
空间网5基线——第2部分:培训公路速度分割模式
空间网5基线——第3部分:从卫星图像中提取公路速度矢量
SpaceNet 5 SpaceNet 5 赢赢模型发布模式:道路的终点
我引用了Julien Simon的两个Hugging Face博客,金属-16xl:
使用 Intel Sapphire Rapids 的加速火炉变速器, 第1部分
使用 Intel Sapphire Rapids 的加速火炬变速器,第2部分
使用 CPU 实例而不是在主要云服务供应商( CSP) 使用 GPU 实例可能节省大量成本。 最新的处理器仍在向 CSP 推出, 所以我正在使用 INTel Xeon 第四次 Gente Intel Xeon 处理器, 该处理器设在 Intel 开发者云上( 您可以在此报名 ) :. 云信息 com).
在 AWS 上,您可以从列 约*在你之后的EC2实例此处预览的标记(图1)在编写本报告时,新的AI加速发动机Intel 高级母体扩展装置(Intel AMX)仅供光金属使用,但不久将在虚拟机器上启用。
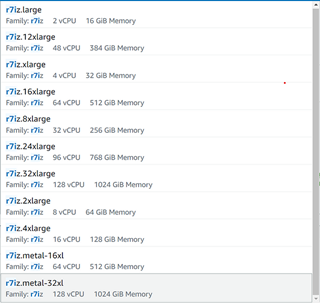
图1 图1AWS EC2(作者图像)上的第四次Gen Xeon实例清单
在 Google Cloud* 平台上,您可以从第四 Gen Xeon 可缩放处理器 C3 VMs(图2)中选择。
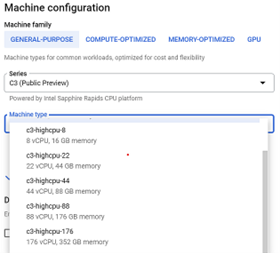
图2 图2. Google Cloud平台上的第四 Gen Intel Xeon 可缩放处理器实例列表(作者图像)
硬件介绍和优化
2023年1月释放了第四 Gen Intel Xeon 处理器,我使用的光金属实例有两个插座(每个插座有56个物理核心),504GB内存和英特尔 AMX 加速。 我在后端安装了几个关键库,以控制和监测我在CPU上使用的插座、内存和核心:
numactl(与sudo APT- Get 安装 numactl)
伊利维埃米耶马洛茨(与安装 libjemalloc 的 sudo appet- get)
intel- openmp(与conda 安装 intel- openmp)
gperftotototool 的 gperfftotototo 工具, gperfftototo 工具工具(与conda 安装 gperftotototool 的 gperfftotototo 工具, gperfftototo 工具工具 - c conda- forge 的 gperftotototool 的 gperfftotototo 工具, gperfftototo 工具工具 - c conda- forge)
PyTorrch PyTorch 和 Intel 扩展的 PyTerch 都有辅助脚本, 因而不需要明确使用intel- openmp和numactl,但是它们确实需要安装在后端。如果您想要设置它们用于其他工作,这就是我用来用于 OpenMP * 的内容。
导出 缩写(_num) 缩写(_N)=36 导出 KMP_AFFIY=granciality=fine, compact, 1,0 导出 kmp_ 阻塞时间=1
. 何处缩写(_num) 缩写(_N)是分配给该任务的线条数,kmp- 亲度影响线条亲和设置(包括相互接近的包装线、钉线状态),以及kmp_ 阻塞时间以毫秒设定时间, 空线在睡觉前应该等待时间 。
以下是我用来做的东西numactl …
numactl - C 0-35 - membind=0 train.
在那里... ... 在那里...-C指定要使用和-- memembind -- membind指示程序只使用一个套接字( 在这种情况下, 套接字为 0 ) 。
空间网数据
我用的是卫星图像数据空间网5挑战不同城市可免费下载AWS S3桶:
aws s3是 s3://spacenet-dataset/spacenet/SN5_roads/tarballs/ -- -- 人类可读
2019-09-03 20:59 3.8 GIB SN5_Roads_test_public_AOI_7_Moscow.tar.gz 2019-09-24 08:43:02 3.2 GIB SN5_test_public_AOI_7_Moscow.gz 2019-09-24 08:43:02 GIB SN5_test_ public_AOI_8_San_Juan.tar.gz 2019-09-14 13:13:19-09-14 13:13:3:34.5 GIB SN5_test_rations_train_AOI_8_Mumbai.tar.gz
您可以使用以下命令下载和拆解文件 :
aws s3 cp s3://spacenet-dataset/spacenet/SN5_roads/tarballs/SN5_roads_train_AOI_7_Moscow.tar.gz. tar-xvzf ~/spacenet5data/moscow/SN5_roads_train_AOI_7_Moscow.tar.gz z
数据集准备
我使用了莫斯科卫星卫星图像数据集,该数据集由1,352张1,300比1,300像素的1,352张图像组成,在不同的文本文件中有相应的街道标签,其中包括8波段多频谱图像和3波段RGB图像。图3显示了四种RGB卫星图像样本及其相应的面具。yped_ masks. py 速度和量从 CRESI 仓库生成分隔面罩的脚本 。
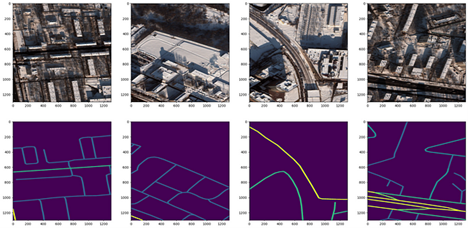
图3 图33. 莫斯科(顶行)的卫星图像3频道RGB芯片和具有不同速度限制(底排)的对应像素分离面罩(作者图像)
还有一个JSON配置文件,必须更新其余所有组成部分:培训和验证分解、培训和推论。在此可以找到一个示例配置。我进行了80:20的培训/验证分解,确保指向正确的卫星图像文件夹和相应的培训面具。以GitHub为例的笔记本,.
培训ResNet34联合国模式
我做了一些修改cresi 缩写为了在CPU上运行并优化培训,以下的代码描述如下,以便运行在CPU上并优化培训。自定义模型 = nn.DataParallel( 模型). cuda ()与自定义模型 = nn.DataParallel( 模型)和在列列. py脚本中01_tran.py 01_tran.py 01_tran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py删除脚本irch.randn( 10) cuda ().
为优化培训,增加intel_ extension_ for_ pytorch 导入为 ipex 的 intel_ extension_ for_ pytorch中输入对帐单的输入对帐单列列. py在将模型和优化器定义如下之后:
自我模型 = nn.DataParallel( 模型) 自我. 优化 = 优化( 自我. 模型. 参数 (), lr= config. lr)
添加Ex. 优化使用 BF16 精度的行, 而不是 FP32:
自我模范,自我优化 = ipex. 优化(自. model, 优化 = self. 优化, dtype= torch.bfloat16)
添加一条行, 用于混合精度训练, 只需在前方过路和计算损失函数前完成 :
使用 torch. cpu. amp. autocast () : 如果动词 : 打印 (“ 输入. shape, 目标. shape : ” , 输入. shape, 目标. shape ) 输出 = 自我 。 模型( 输入) 计量 = self. calculate_ loss_ single_ channel( 输出、 目标、 计量、 训练、 超大小 )
现在我们已经优化了训练守则, 我们可以开始训练我们的模型。
喜欢SpaceNet 5 竞赛获胜者,我训练了一个 ResNet34 编码器 Unet 解码器模型。该模型经过了图像网络重量的预先训练,而骨干在训练期间完全解冻。01_tran.py 01_tran.py 01_tran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py但为了控制硬件的使用, 我使用了一个助手脚本。 实际上有两个助手脚本: 一个是股票 PyTorch 的脚本, 一个是 PyToch 的 Intel 扩展版 。 它们都完成了同样的事情, 但第一个来自股票的脚本是后端. xeon. run_ cpu,第二个来自 英特尔扩展的PyTorrch是Ipexrun 扩展.
这是我在指挥线上运行的:
python - m short. trachends.xeon. run_ cpu - stinstances 1 -- ncores_per_instance 32 -- log_path/ home/devcloud/spacenet5data/ moscow/v10_xeon4_ devcloud22. 04/logs/run_cpu_logs/home/devcloud/cresi 缩写/cresi 缩写/01_train. py / home/devcloud/cresi 缩写/cresi 缩写/cresi 缩写/configs/ ben/v10_xeon4_ baseline_ben.json -- fold=0
Ipexrun 扩展 - stinstance 1 -- ncore_per_instance 32/ home/devcloud/cresi 缩写/cresi 缩写/01_tran.py 01_tran.py 01_tran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py/ home/devcloud/cresi 缩写/cresi 缩写/cresi 缩写/configs/ben/v10_xeon4_ baseline_ben.json -- fold=0
在这两种情况下,我都要求PyTorrch在一个有32个核心的插座上进行训练。 运行后,我得到一份打印出哪些环境变量在后端设置,以了解PyTorrch是如何使用硬件的:
INFO - 使用 CDMalloc 内存分布器INFO - 缩写(_num) 缩写(_N)=32 INFO - 使用 Intel OpenMP InFO - KMP_AFITY=granality=fine, compact, 1,0INFO - KMP_BLOCICTIME=1 INFO - LD_PRELOAD=/ home/devcloud/.conda/env/py39/lib/lib/lib/libclomp5.so:/home/dloud/.conda/env/py39/b/bin/python-u 01_tran.py 01_tran.py 01_tran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.py 01_triran.pycongs/ben/v10_xon4_baseline_ben.jfold=0
在培训期间,我确保我的完全损失功能正在减少(即模式正在趋于一致,寻找解决办法)。
推断
在培训模型后, 我们可以开始仅从卫星图像中进行预测。 在 evval. py 推断脚本中, 将导入的 intel_ extension_ for_ pytorch 添加为导入语句的 Ipex 。 在装入 PyTorch 模型后, 使用 PyTorrch 的 Intel 扩展来优化 BF16 推断的模型 :
模型 = irch.load( os. path. join( path_ model_ 量重, “ fold_ best. pth”.format( fold)), 地图_ 位置 = lambda 存储, loc: 存储) 模型. eval () 模型 = ipex. optimize( 模型, dtype = rch. bfloat16)
在进行预测之前,增加两行,以达到混杂精度:
使用 torch.no_ grad (): 使用 rch. cpu. amp. autocast (): 用于 pbar 中的数据 : 样本 = rch. autograd. 可变( 数据 [ “ 图像 , 挥发性 = True ) 预测 = 预测 (模型、 样本、 翻页 = self. flips )
运行推论,我们可以使用02_eval.py现在我们有了经过训练的模型, 我们可以在卫星图像上作出预测(图4), 我们可以看到它似乎在绘制与图像相近的道路图!

图4 图41. 莫斯科卫星图像和随附的道路预测(作者图像)
我意识到我所训练的模型过于适合莫斯科图像数据,赢得此项挑战的解决方案从六个城市(拉斯维加斯、巴黎、上海、喀土穆、莫斯科、孟买)获得的数据和新城市的表现良好。 在未来,值得测试的一件事就是在所有六个城市进行培训,并在另一个城市进行推论,以复制其结果。
关于处理后的说明
还可以采取进一步的后处理步骤,在地图中添加掩码作为图表特征。 您可以在此阅读关于后处理步骤的更多信息:
空间网5基线——第3部分:从卫星图像中提取公路速度矢量
后处理脚本
结语
总之,我们:
创建了1 352个图像培训面罩(速度限制),与我们的培训卫星图像数据(来自.geojson文本文件标签)相对应。
定义了用于培训和推断的配置文件
将我们的数据分成培训和鉴定组
优化了我们的CPU培训守则,包括使用PyTorch和BF16的Intel扩展
在第四 Gentel Xeon CPU 上培训了表演者ResNet34 UNet 模型
Ran 初始推论,以看到预测速度限制面罩的速度
您可以找到在此列出第四 Gentel Xeon CPU 的详细基准.
下一步步骤
使用 PyTorrch 的 Intel 扩展扩展号, 扩展 Intel CPU 的优化 :
pip 安装 intel- extension 用于 Pytorch 的 Intel- extension 设备
git 克隆 https://github.com/intel/intel/intel-extension-for-pytorch
联系我 联系连连In如果你还有问题要问!
PyTorrch 的 Intel 扩展的更多信息可在此处找到.
获取软件
我鼓励你查查英特尔的另外一个AIAI 工具工具和框架框架框架框架优化和了解开放、基于标准的单api构成英特尔的AI软件组合基础的多神多神多神多神多神多造编程模式。
有关第四任英特尔Xeon 缩放可缩放处理器的更多详情,访问AI 平台英特尔是如何授权开发商运行高性能、高效端对端的AI管道的。
PyTollch 资源
启动 PyTork 启动
D. 讨论讨论
文档文件文件
审核编辑:汤梓红
-
图像分割—基于图的图像分割2015-11-19 741
-
基于Matlab图像分割的研究2016-01-04 728
-
基于加速k均值的谱聚类图像分割算法改进_李昌兴2017-03-19 719
-
图像分割和图像边缘检测2017-12-19 10262
-
图像分割技术的原理及应用2017-12-19 40334
-
图像分割的基本方法解析2017-12-20 108419
-
图像分割技巧资料2020-09-24 1610
-
AI算法说-图像分割2023-05-17 883
-
PyTorch教程7.2之图像卷积2023-06-05 186
-
PyTorch教程14.1之图像增强2023-06-05 257
-
PyTorch教程14.9之语义分割和数据集2023-06-05 170
-
没你想的那么难 | 一文读懂图像分割2023-05-16 611
-
什么是图像分割?图像分割的体系结构和方法2023-08-18 2595
-
如何加速生成2 PyTorch扩散模型2023-09-04 820
-
机器视觉(六):图像分割2023-10-22 516
全部0条评论

快来发表一下你的评论吧 !
