

Nature:人工智能芯片!
描述
具有数十亿参数的人工智能(AI)模型可以在一系列任务中实现高精度,但它们加剧了传统通用处理器(例如图形处理单元或中央处理单元)的低能效。模拟内存计算(模拟 AI)可以通过在“内存块”上并行执行矩阵向量乘法来提供更好的能源效率。然而,模拟人工智能尚未在需要许多此类图块以及图块之间神经网络激活的有效通信的模型上证明软件等效(SWeq)准确性。
有鉴于此,美国IBM 研究中心S. Ambrogio(一作兼通讯)等人展示了一款14 nm的模拟 AI 芯片,该芯片结合了跨 34 个区块的 3500 万个相变存储器件、大规模并行区块间通信和模拟低功耗外围电路,可实现12.4 万亿次 / 秒 / 瓦运算性能,能效是传统数字计算机芯片的14倍。作者展示了小型关键字识别网络的完全端到端 SWeq 精度,以及更大的 MLPerf 循环神经网络传感器 (RNNT) 上接近 SWeq 的精度,其中超过4500万个权重映射到跨越5个芯片的1.4亿个相变存储器件上。
芯片架构
作者展示了芯片的显微照片,突出显示了34个模拟块的 2D 网格,每个块都有512×2048PCM 交叉阵列。当持续时间向量从模拟快发送到OLP时,芯片有效地实现了基于斜坡的模数转换器 (ADC)。所有权重配置、MAC操作和路由方案均由每个图块上可用的用户可配置本地控制器(LC) 定义。本地SRAM存储定义数百个控制信号的时间序列的所有指令,从而实现高度灵活的测试并简化设计验证,与预定义状态机相比,面积损失较小。作者验证了持续时间可以在整个芯片上可靠地传输,最大误差等于5ns(较短持续时间为 3ns)。
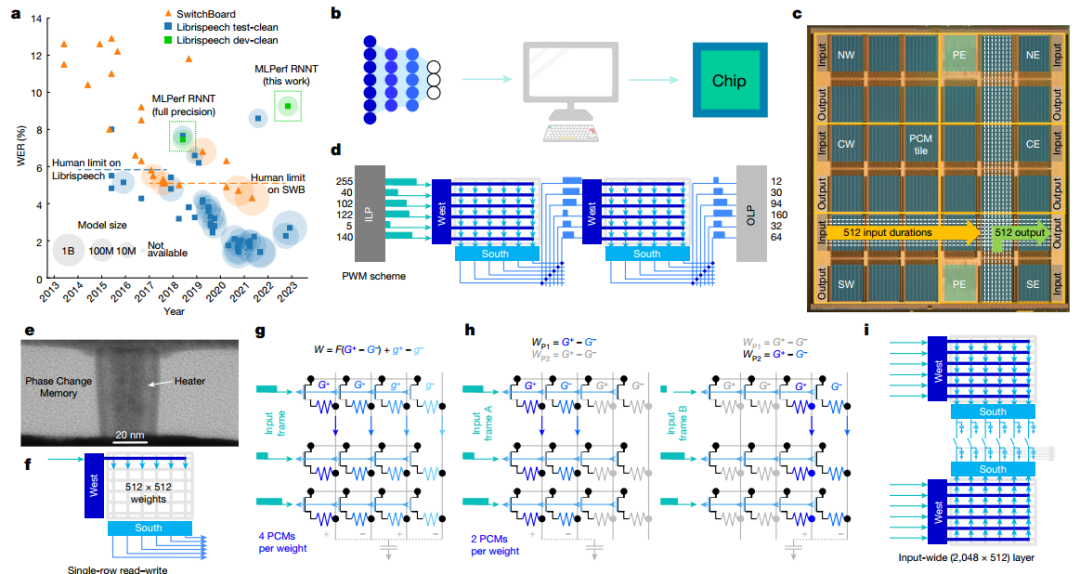
图 芯片架构
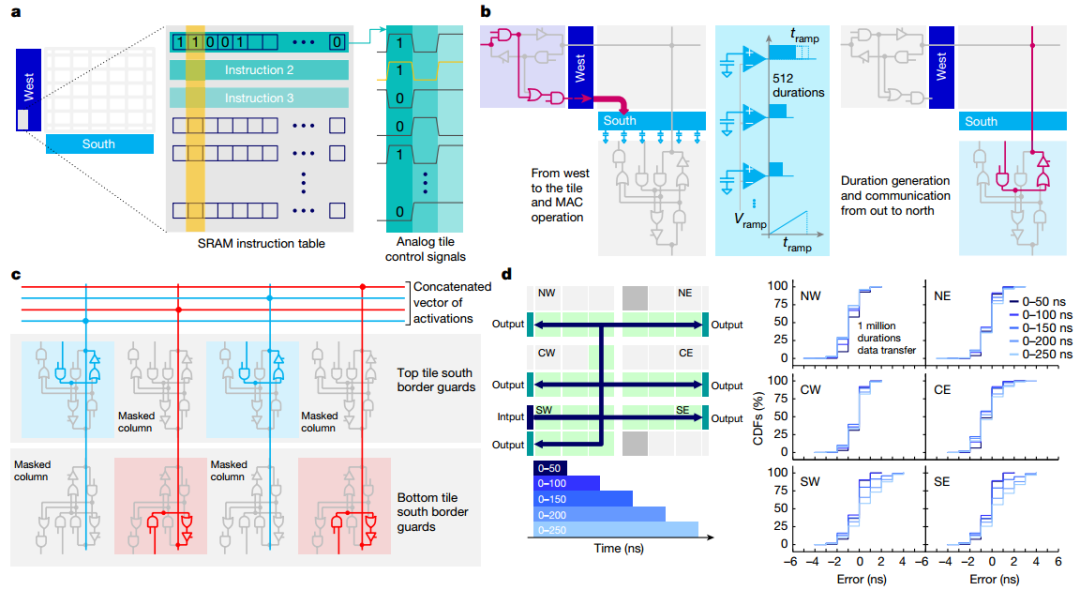
图 可重构架构和路由
KWS任务
为了演示芯片在端到端网络中的性能,实现了多类KWS任务。作者采用了 FC网络,实现了 86.75% 的分类准确度。为了在芯片上实现完全端到端的传输,作者进行了一系列修改,最终端到端实现总共使用四个图块。为了提高MAC精度并补偿外围电路的不对称性,引入了MAC不对称平衡(AB)方法,测得的KWS精度为86.14%,完全在 MLPerf SWeq“等精度”极限 85.88%之内。
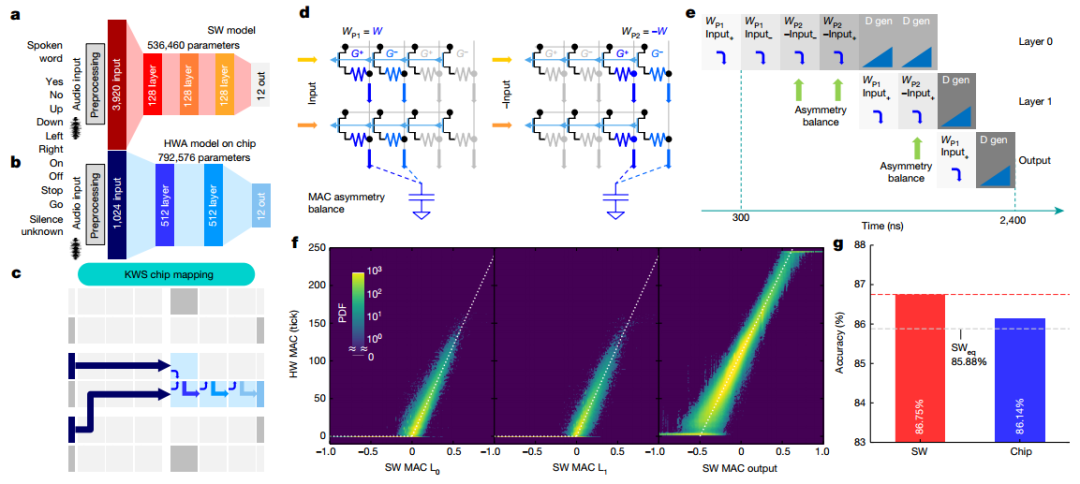
图 端到端 KWS 任务
芯片上的 RNNT 映射
作者实施了MLPerf数据中心网络RNNT作为行业相关的工作负载演示。当 RNNT等大型DNN以降低的数字精度实现时,整个网络的最佳精度选择可能会有所不同。研究表明即使使用激进的量化,不易受影响的层或整个网络块仍将提供较低的 WER,而高度敏感的块即使对于少量的权重量化也将表现出较高的 WER。对每个单独的层重复此过程以识别最敏感的层,接着将 MLPerf 权重映射到分布在5个芯片上的142个图块上。在总共 45,321,309 个网络权重和偏差参数中,45,261,568 个被映射到模拟存储器(权重的 99.9%)。
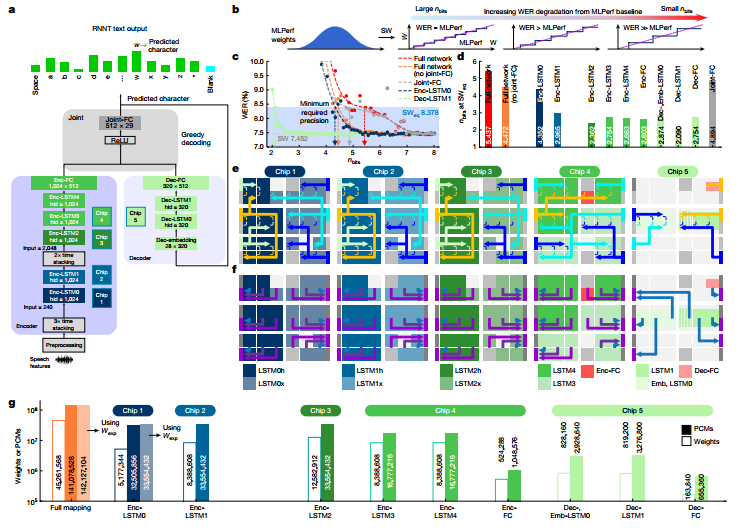
图 用于语音转录的 MLPerf RNNT 网络
准确度结果
作者展示了2513个音频查询的完整 Librispeech 验证数据集的权重映射和编程后的实验WER。总WER为9.475%,与SW 基线相比总体下降了 2.02%。在本实验中,通过芯片推断完整的Librispeech验证数据集并保存输出结果。然后将这些输入到芯片 2 中,依此类推,输入到所有 5 个芯片中。即使在PCM漂移超过1周后重复进行,且没有任何重新校准或重量重新编程,RNNT WER 也仅下降了 0.4%。
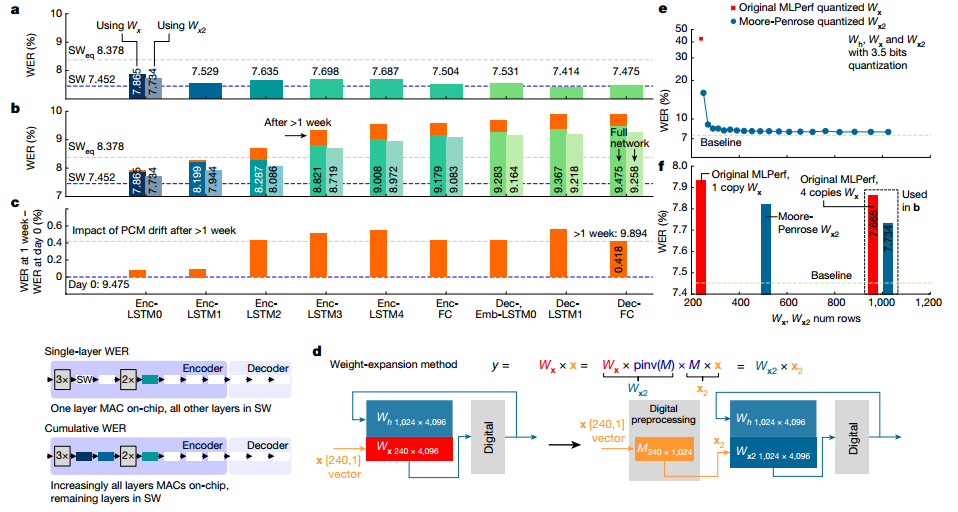
图 在 MLPerf RNNT上使用Librispeech进行WER实验
电源和系统性能
作者还测量了推理操作期间每个芯片的全部功耗。所有控制和通信电路均以 0.8V 驱动。芯片最佳功率性能 为12.40 TOPS/W。通过将积分时间减半,芯片的 TOPS/W 可以再提高 25%,但 WER 会额外降低1%。随着重量的增加,使用本文报道的芯片的模拟人工智能系统可以在3.57W的功率下实现6.704TOPS/W,比MLPerf的最佳能效提高了14 倍,WER 为 9.258%。

图 MLPerf RNNT功率和系统性能
-
人工智能是什么?2015-09-16 0
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 0
-
人工智能就业前景2018-03-29 0
-
解读人工智能的未来2018-11-14 0
-
【2019人工智能大会】大咖齐聚,共同探讨加速人工智能技术落地2019-01-21 0
-
人工智能技术及算法设计指南2019-02-12 0
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 0
-
人工智能语音芯片行业的发展趋势如何?2019-09-11 0
-
传感器和人工智能的关系2019-11-25 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
一文看懂人工智能语音芯片 精选资料分享2021-07-29 0
-
物联网人工智能是什么?2021-09-09 0
-
人工智能AI芯片到底怎么用2021-09-22 0
-
人工智能芯片是指什么2021-10-25 0
-
人工智能对汽车芯片设计的影响是什么2021-12-17 0
全部0条评论

快来发表一下你的评论吧 !
