

使用MVTec HALCON AI加速器接口在英特尔独立显卡上加速AI推理
描述

1.1
什么是 HALCON
MVTec HALCON 是一款在全球范围内使用,综合性的机器视觉标准软件。它有一个专门的集成开发环境(HDevelop),专门用于开发图像处理解决方案。使用 MVTec HALCON,您可以:
-
受益于灵活的软件架构
-
加快所有可行的机器视觉应用发展
-
保证快速进入市场
-
持续地降低成本
作为一个综合工具箱,HALCON 涵盖了机器视觉应用的整个工作流程。其核心是灵活而强大的图像处理库,其中有 2100 多个算子。HALCON 适用于所有行业,并为图像处理提供卓越性能。
官网链接:
https://www.mvtec.com/

图片引用自:
https://www.mvtec.com/cn/products/HALCON/why-HALCON/compatibility
1.2
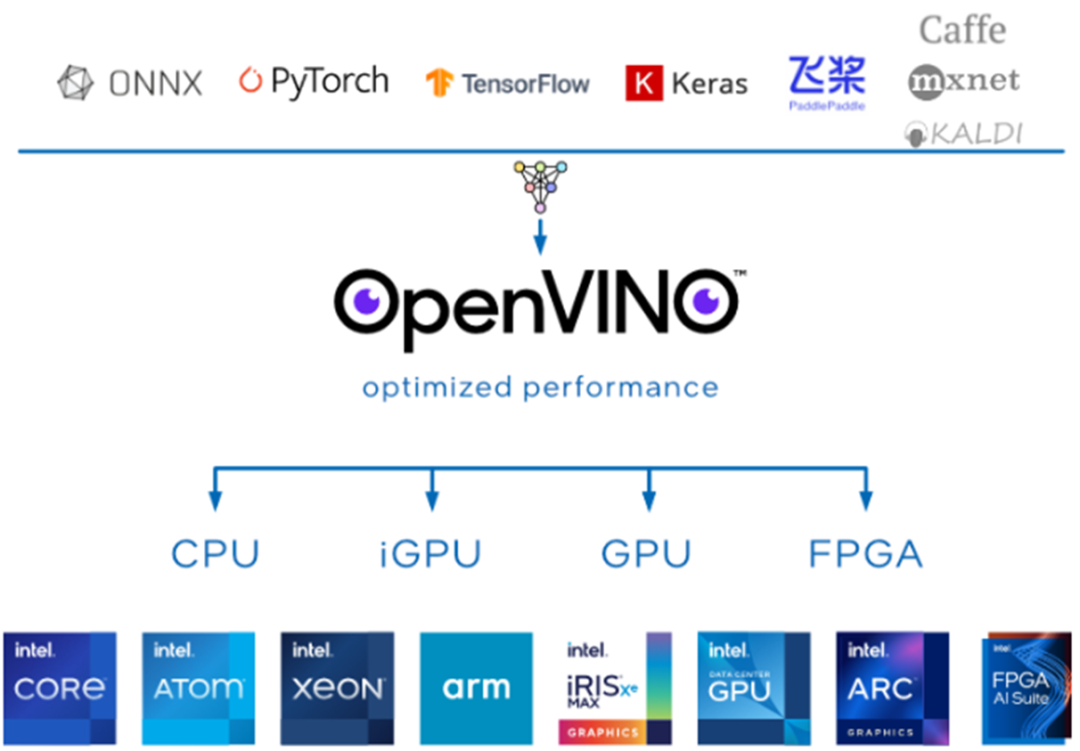
什么是OpenVINO
OpenVINO 是一个用于优化和部署人工智能(AI)推理的开源工具平台。
-
提高计算机视觉、自动语音识别、自然语言处理和其他常见任务的深度学习性能
-
使用经过 TensorFlow、PyTorch 等流行框架训练的模型
-
减少资源需求,并在从边缘到云的一系列英特尔平台上高效部署
1.3
安装 HALCON 和 OpenVINO
从 21.05 版本开始,HALCON 通过全新 HALCON AI 加速器接口 (AI²),支持 OpenVINO 工具套件,从而支持 AI 模型在英特尔的硬件设备上实现推理计算加速。
当前 HALCON 的 AI 模型对英特尔的硬件设备支持,如下表所示
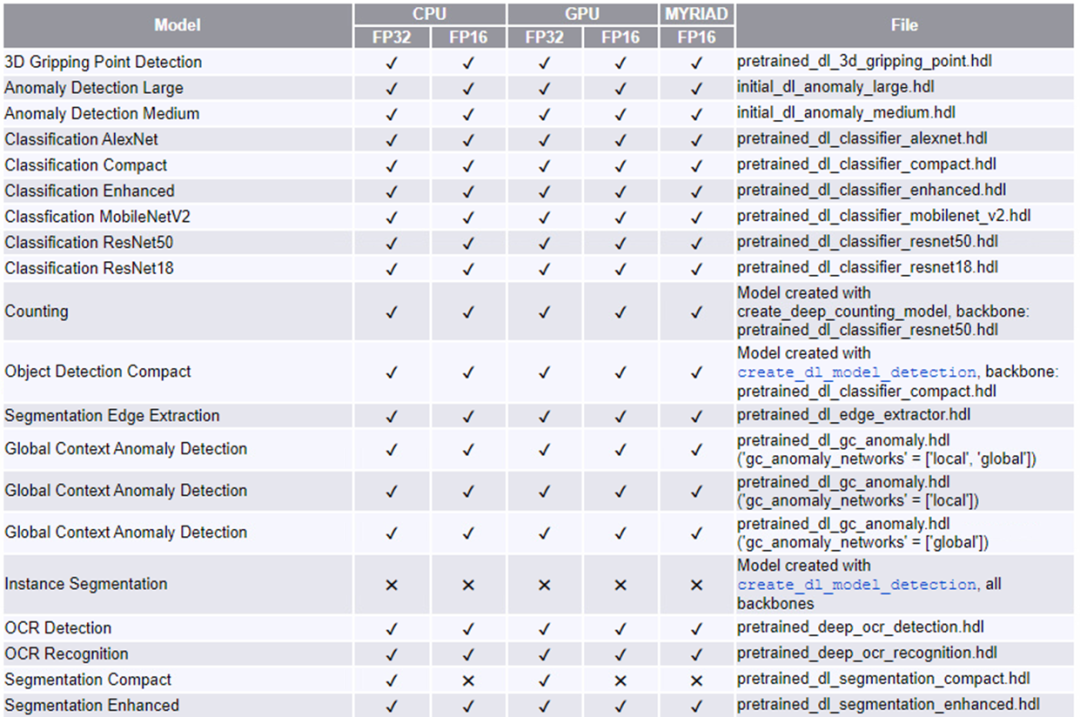
要实现使用 HALCON AI 加速器接口在英特尔硬件设备上加速 AI 推理计算,只需要一次安装 HALCON 和 OpenVINO,然后编写 HALCON AI 推理程序即可。
1.3.1
安装 HALCON
官网注册
登录 MVTec 官网 HALCON 软件下载页面(目前 HALCON 的最新版本是 23.05 Progress)
https://www.mvtec.com/downloads/halcon, 如果没有注册过 MVTec 用户账号,需要先进行注册个人或企业账号。(请注意此处需要使用公司邮箱注册,qq 邮箱、163 邮箱等私人邮箱会注册失败)
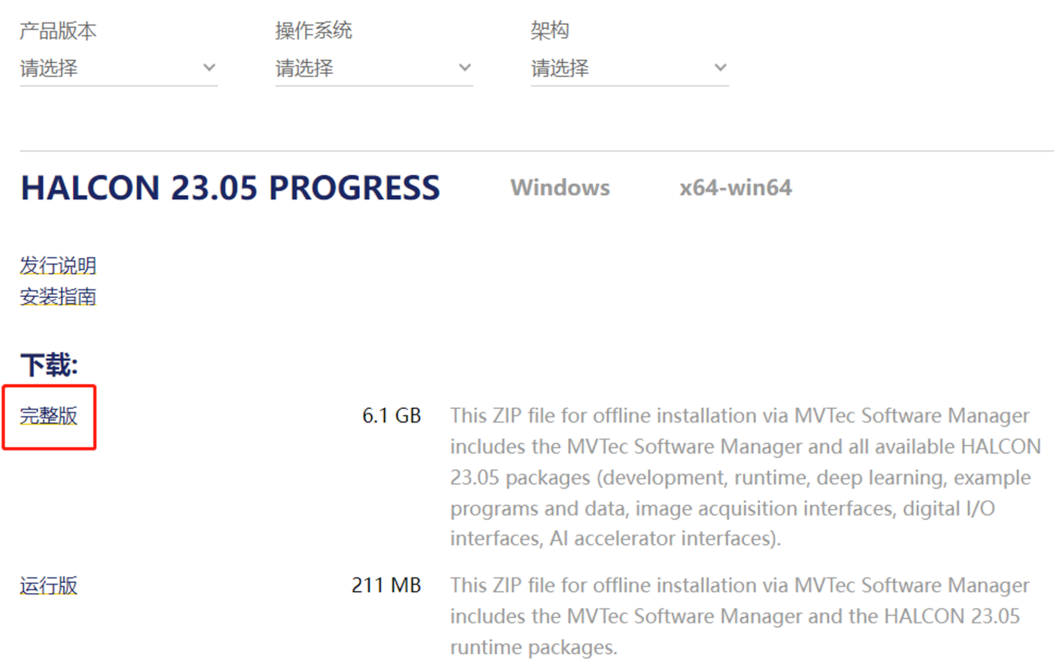
下载并解压
在官网下载完整版的安装包(需要登陆账号), 下载 HALCON: MVTec Software[1] 。可以选择产品的版本和操作系统,此处以 Windows 平台的 23.05 progress 版本为例。点击图中链接会自动开始下载,可自行使用工具加速。
下载完成后,解压缩完成,打开对应的文件夹,点击 som.exe 文件,启动 SOM(Software Manager)。
安装设置
SOM 会使用默认浏览器打开安装界面,如果打开界面后未出现可选安装项目,建议重启电脑再次打开 som.exe。
可以点击“语言” 按钮切换界面语言,点击“环境”按钮修改一些设置,如程序和数据安装路径,仓库地址等等,一般使用默认值最好。


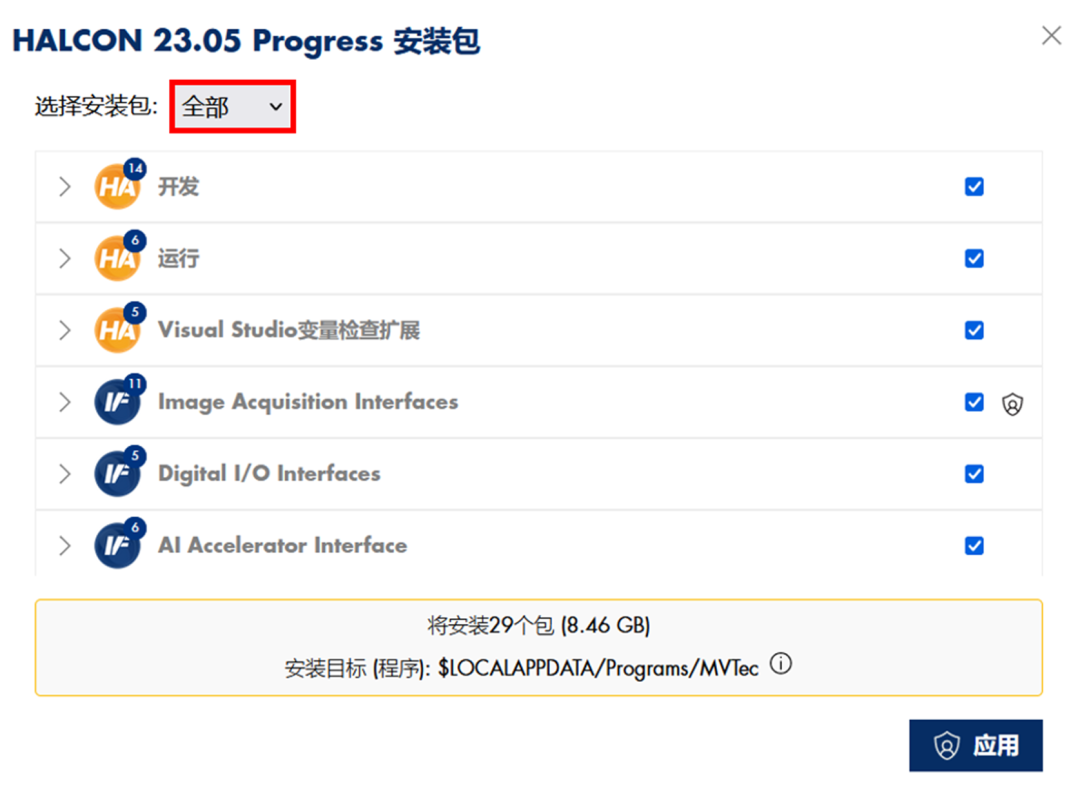
然后选择“可获得的”页面,找到安装包,点击“安装”按钮, 上方按钮是为当前用户安装,下方是为所有用户安装(需要系统管理员权限),一般点选上方按钮。
设备空间足够的话(15G 以上),建议右侧全选,全部安装;点击后等待安装结束即可。
加载 license 文件

HALCON 软件的运行还需要对应的 license 加密文件,可以向 MVTec 官方购买正式版或者申请评估。
然后,可以直接在 SOM 界面中加载 license 文件,点击上图中的红色按钮,可以打开下方界面进行 license 文件的安装和管理,将 license 文件直接拖入即可。
最后,在 Windows 桌面上找到 HALCON 集成开发环境 HDevelop 软件图标,即可正常使用 HALCON。
1.3.2
安装 OpenVINO 2021.4 LTS
请到 OpenVINO 官网[2] 下载并安装OpenVINO 2021.4.2,如下图所示。

安装完毕后,请将 OpenVINO 运行时库的路径添加到环境变量 path 中。
第一步,运行:
C:Program Files (x86)Intelopenvino_2021.4.752insetupvars.bat
path
获取 OpenVINO 运行时库的路径,如下图所示:
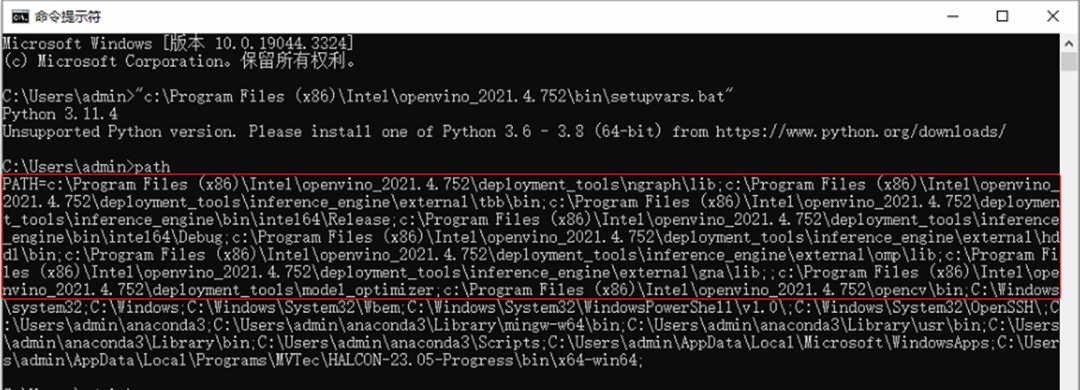
第二步,将 OpenVINO 运行时库的路径添加到环境变量 path 中,如下图所示:
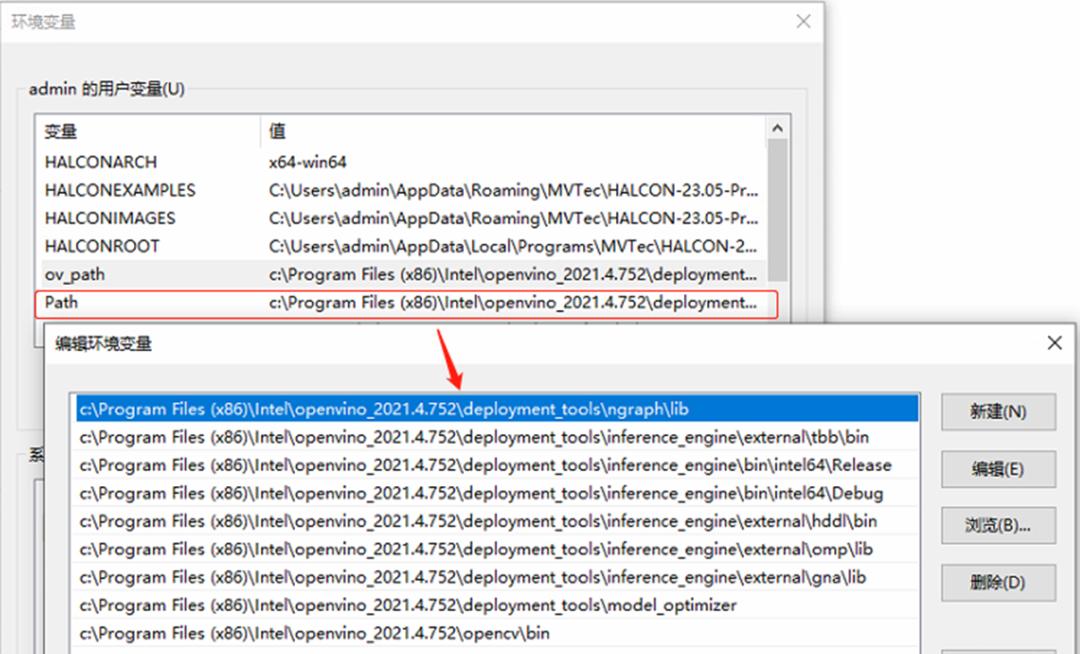
到此,下载并安装 OpenVINO,然后 OpenVINO 运行时库的路径添加到环境变量 path 中的工作全部完成。
1.4
编写 HALCON AI 推理程序
1.4.1
HALCON AI 推理程序工作流程
关于 HALCON AI 推理程序工作流程,以 HALCON 的深度学习图像分类为例,程序代码为 HALCON 集成开发环境 HDevelop 的开发语言。
1. 读取已训练完成的深度学习模型:
* Read in the retrained model.
read_dl_model (RetrainedModelFileName, DLModelHandle)
2. 设置深度学习模型参数:
* Set the batch size.
set_dl_model_param (DLModelHandle, 'batch_size', BatchSizeInference)
* Initialize the model for inference.
set_dl_model_param (DLModelHandle, 'device', DLDevice)
3. 导入数据集预处理的参数:
* Get the parameters used for preprocessing.
read_dict (PreprocessParamFileName, [], [], DLPreprocessParam)
4. 导入推理图像并生成深度学习样本:
* Read the images of the batch.
read_image (ImageBatch, Batch)
* Generate the DLSampleBatch.
gen_dl_samples_from_images (ImageBatch, DLSampleBatch)
5. 对深度学习样本进行预处理以匹配模型:
* Preprocess the DLSampleBatch.
preprocess_dl_samples (DLSampleBatch, DLPreprocessParam)
6. 执行深度学习推理:
* Apply the DL model on the DLSampleBatch.
apply_dl_model (DLModelHandle, DLSampleBatch, [], DLResultBatch)
1.4.2
HALCON AI 加速器接口 (AI²)
MVTec 的 OpenVINO 工具套件插件基于全新 HALCON AI 加速器接口 (AI²)。通过这一通用接口,客户可以快速方便地将支持的 AI 加速器硬件用于深度学习应用的推理环节。
这些特殊设备不仅在嵌入式环境中得到广泛应用,也越来越多地出现在 PC 环境中。AI 加速器接口从特定硬件中抽象出深度学习模型,因而特别能够适应未来发展。
MVTec 作为机器视觉软件的技术领导者,其软件可以在工业物联网环境中,通过使用 3D 视觉、深度学习和嵌入式视觉等现代技术,实现新的自动化解决方案。
除 MVTec 提供的插件外,还可以集成客户特定的 AI 加速器硬件。此外,不仅典型深度学习应用可以通过 AI² 加速,所有集成深度学习功能的“经典”机器视觉方法,例如 HALCON 的 Deep OCR,也能从中受益。
1.4.3
HALCON 基于 OpenVINO 的 AI 推理范例程序
本文中,我们使用的是基于 HALCON 的深度学习图像分类的官方范例程序。
本文中所使用的基于 OpenVINO 的 HALCON 范例代码已分享到 MVTec 官网,网址为:
https://www.mvtec.com/cn/technologies/deep-learning/ai-accelerator-interface
下载后将该程序保存至 HALCON 范例程序指定的文件路径中:
%HALCONEXAMPLES%/hdevelop/Deep-Learning/Classification/。
默认情况下,由于推理需要加载已经过训练的深度学习模型,所以需要使用 HALCON 的开发环境 Hdevelop 依次先运行该路径下的范例程序,从而可以完成训练并保存模型:
-
classify_pill_defects_deep_learning_1_preprocess.hdev
-
classify_pill_defects_deep_learning_2_train.hdev
接着打开下载的范例并运行(或按 F5),首先需要查询 HALCON 所支持的 OpenVINO 设备:
* This example needs the HALCON AI²-interface for the Intel Distribution of the OpenVINO Toolkit * and a installed version of the Intel Distribution of the OpenVINO Toolkit.
query_available_dl_devices ('ai_accelerator_interface', 'openvino', DLDeviceHandlesOpenVINO)
之后,继续执行程序,在可视化界面会依次显示所有查询到的 OpenVINO 设备信息,包括本文所需使用的英特尔 Arc A770 独立显卡,这里我们看到支持的推理精度有 FP32 和 FP16,如下所示。

然后,需要选择 OpenVINO 设备,目前 HALCON AI² 接口所支持的 OpenVINO 设备包括英特尔的 CPU,GPU,HDDL 以及 MYRIAD。在安装 HALCON 时,只内置安装了 CPU 插件,需要额外安装 OpenVINO 工具套件来支持 GPU 等其他设备,具体安装参考章节 1.3.2。这里我们指定 OpenVINO 运行设备为“GPU”,即英特尔的独立显卡。
* The device parameter 'type' can be used for further selection.
* It states the OpenVINO plugin responsible for handling the
* device. Depending on your OpenVINO installation, possible values
* are e.g. 'CPU', 'GPU', 'HDDL', and 'MYRIAD'. If you did not install
* OpenVINO, HALCON will install the 'CPU' plugin.
OpenVINODeviceType := 'GPU'
继续运行程序,会针对 GPU 的不同浮点精度做推理优化,得到经过 OpenVINO 加速优化的推理模型。
* To convert the model to 'float16'/'float32' precision, no samples have to be provided to
* optimize_dl_model_for_inference.
* No additional conversion parameters are required, so use the default parameters.
get_dl_device_param (DLDeviceHandleOpenVINO, 'optimize_for_inference_params', OptimizeForInferenceParams)
optimize_dl_model_for_inference (DLModelHandle, DLDeviceHandleOpenVINO, 'float32', [], OptimizeForInferenceParams, DLModelHandleOpenVINO, ConversionReport)
在可视化窗口会展示 CPU 和 GPU 分别在 FP32 和 FP16 下的性能比对,包括推理时间和 Top-1 错误率。
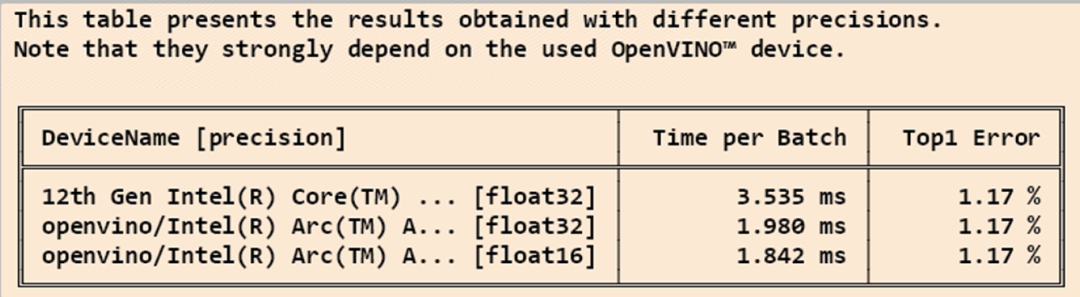
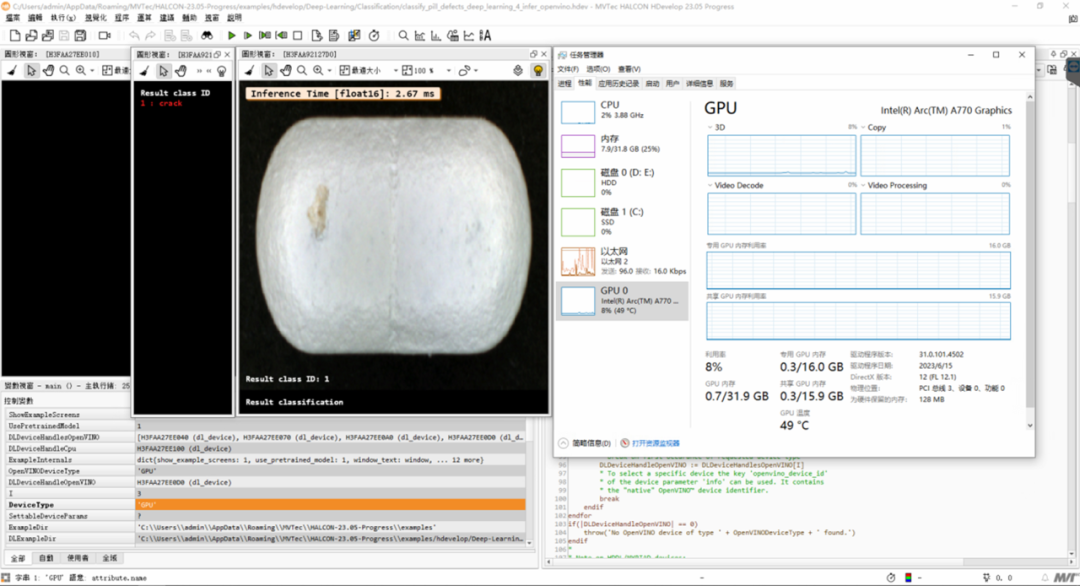
至此,OpenVINO 的配置测试已基本完成,接着就是执行深度学习的推理,在可视化窗口里可以看到对于推理步骤的图示和文字解释,其中会再次展示所使用的推理设备,即英特尔的独立显卡信息。

推理的工作流程可以参考 1.4.1 章节,在执行推理的同时,可以打开任务管理器,观察英特尔独立显卡的运行状态。范例中,默认使用 FP16 精度加速推理,也可以根据具体需要切换成 FP32 精度进行对比测试。
1.5
总结
MVTec HALCON AI 加速器接口(AI²)可帮助 MVTec 软件产品用户充分利用与 OpenVINO 工具套件兼容的 AI 加速器硬件。如此一来,对于关键工作负载,可以在英特尔计算设备(包括 CPU、GPU 和 VPU)上明显缩短深度学习推理时间。
由于支持硬件范围得到扩展,用户现在可以充分利用各种英特尔设备的性能来加速深度学习应用,不再局限于少数特定设备。同时,这种集成可以无缝进行,不受特定硬件细节约束。现在只需更改参数,即可在 OpenVINO工具套件支持的设备上执行现有深度学习应用的推理过程。
-
英特尔高清显卡4600帮助2018-10-26 0
-
英特尔重点发布oneAPI v1.0,异构编程器到底是什么2020-10-26 0
-
基于SRAM的方法可以加速AI推理2020-12-30 0
-
【书籍评测活动NO.18】 AI加速器架构设计与实现2023-07-28 0
-
英特尔媒体加速器参考软件Linux版用户指南2023-08-04 0
-
Intel媒体加速器参考软件用户指南2023-08-04 0
-
《 AI加速器架构设计与实现》+第2章的阅读概括2023-09-17 0
-
创客汇:英特尔“众创空间加速器”计划正式启动2015-04-09 939
-
英特尔10nm嵌入式处理器变身AI加速器2019-07-02 712
-
K210 AI加速器适用于计算机视觉应用的紧凑型树莓派HAT2022-11-22 1114
-
英特尔面向中国市场发布Gaudi2处理器,加速大模型训练和推理2023-07-17 1294
-
大模型算力新选择——宝德AI服务器采用8颗英特尔Gaudi®2加速器2023-07-19 506
-
英特尔Gaudi 3系列AI加速器明年上市2023-12-15 445
-
在英特尔独立显卡上加速HALCON AI模型推理2023-12-16 711
-
英特尔专家为您揭秘第五代英特尔® 至强® 可扩展处理器如何为AI加速2023-12-23 462
全部0条评论

快来发表一下你的评论吧 !
