

只需简单的几步,2D视频变3D?最新视频创作AI模型!
描述
文中解决了从描述复杂动态场景的单目视频中合成新视图的问题。作者提出了一种新方法,该方法不是在 MLP 的权重内对整个动态场景进行编码,而是该方法通过采用基于体积图像的渲染框架,该框架通过以场景运动感知的方式聚合来自附近视图的特征来合成新的视点,从而解决了这些限制。此系统保留了先前方法(Dynamicn NeRFs)在对复杂场景和视图相关效果进行建模的能力方面的优势,但也能够从具有无约束相机轨迹的复杂场景动态的长视频合成逼真的新视图。此方法在动态场景数据集上展示了对最先进方法的显着改进,并将此方法应用于具有具有挑战性的相机和对象运动的野外视频,先前的方法在此应用中是无法生成高质量的渲染。
1 前言
计算机视觉方法现在可以产生具有惊人质量的静态3D场景的自由视点渲染。那么在移动的场景的表现怎么样呢,比如那些有人物或宠物的场景?从动态场景的单目视频中合成新视图是一个更具挑战性的动态场景重建问题。最近的工作在空间和时间合成新视图方面取得了进展,这要归功于新的时变神经体积表示,如HyperNeRF和神经场景流场(Neural Scene Flow Fields,NSFF),它们在基于坐标的多层感知器(MLP)中对时空变化的场景内容进行体积编码。然而,这些Dynamic NeRF方法有局限性,阻碍了它们在复杂、户外视频中的应用。本文提出了一种新的方法(DynIBaR),可以扩展到具有1)长时间持续时间、2)无界场景、3)不受控制的摄像机轨迹以及4)快速和复杂的物体运动捕获的动态视频。本文的主要贡献如下:
提出了在场景运动调整的光线空间中聚合多视图图像特征,这个方法能够正确推理时空变化的几何和外观。
为了有效地跨多个视图建模场景运动,使用跨越多帧的运动轨迹场对这种运动进行建模,用学习的基函数表示。
为了在动态场景重建中实现时间一致性,引入了一种新的时间光度损失,该损失在运动调整的射线空间中运行。这里也推荐「3D视觉工坊」新课程《如何学习相机模型与标定?(代码+实战)》。
为了提高新视图的质量,提出通过一种新的在贝叶斯学习框架中的基于IBR的运动分割技术将场景分解为静态和动态组件。
2 相关背景
Novel view synthesis(新视图生成方法)经典的基于图像的渲染(IBR)方法通过整合输入图像的像素信息来合成新视图,并根据它们对显式几何的依赖进行分类。光场或亮度图渲染方法通过使用显式几何模型过滤和插值采样射线来生成新的视图。为了处理稀疏输入视图,许多方法 利用预先计算的代理几何,例如深度图或网格来渲染新视图。
Dynamic scene view synthesis(动态场景视图合成)大多数先前关于动态场景新视图合成的工作需要多个同步输入视频,限制了它们在现实世界中的适用性。一些方法使用领域知识(domian knowledge),例如模板模型(template models)来实现高质量的结果,但仅限于特定类别的。最近,许多工作建议从单个相机合成动态场景的新颖视图。Yoon等人通过使用通过单视图深度和多视图立体(multi view stereo)获得的深度图显式扭曲(explicit warping)来渲染新视图。然而,这种方法无法对复杂的场景几何进行建模,并在不遮挡时填充真实和一致的内容。随着神经渲染的进步,基于 NeRF 的动态视图合成方法显示了最先进的结果。一些方法,如Nerfies和HyperNeRF,使用变形场(deformation field)表示场景,将每个局部观测映射到规范场景表示。这些变形以时间或每帧潜码(per-frame latent code)为条件,参数化为平移或刚体运动场。这些方法可以处理长视频,但大多局限于物体中心场景,物体运动相对较小,摄像机路径控制。其他方法将场景表示为时变nerf(time-varying nerfs)。特别是,NSFF使用神经场景流场,可以捕获快速和复杂的3D场景运动,用于户外视频。然而,这种方法仅适用于短(1-2 秒)、面向前向视频。
3 方法
本文的网络将给定一个具有帧的动态场景的单目视频(I1, I2,…,, IN ) 和已知的相机参数 (P1, P2,., PN ),目标是在视频中任何所需时间合成一个新的视点。与许多其他方法一样,此方法训练每个视频,首先优化模型来重建输入帧,然后使用该模型渲染新视图。
3.1 Motion-adjusted feature aggregation(运动调整的特征聚合)
我们通过聚合从某一时刻附近的源视图中提取的特征来合成新的视图。为了渲染时刻i的图像,我们首先在i的时间半径r帧内识别源视图Ij, j∈N (i) = [i−r, i + r]。对于每个源视图,我们通过共享卷积编码器网络提取一个二维特征图Fi,形成一个输入元组{Ij, Pj, Fj}。
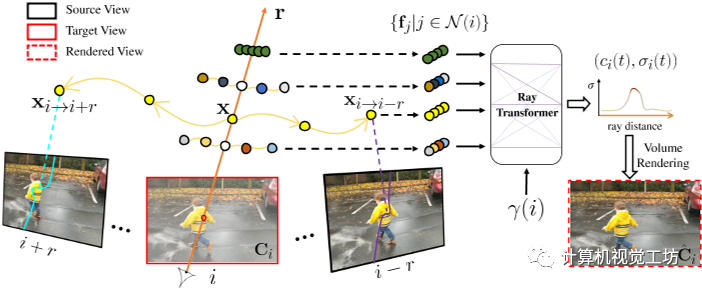
图 2. 通过运动调整的多视图特征聚合渲染。给定沿目标射线r在时间i的采样位置x,我们估计其运动轨迹,它确定x在附近时间j∈N (i)处的3D对应关系,记为xi→j。然后将每个扭曲点投影到其对应的源视图中。沿投影曲线提取的图像特征 fj 被聚合并馈送到具有时间嵌入 γ(i) 的光线转换器,产生每个样本的颜色和密度 (ci, σi)。然后通过沿 r 的体积渲染 (ci, σi) 合成最终像素颜色 ^Ci。
为了预测沿目标射线r采样的每个点的颜色和密度,我们必须在考虑场景运动的同时聚合源视图特征。对于静态场景,沿目标射线的点将位于相邻源视图中对应的极线上,通过简单地沿相邻极线采样来聚合潜在的对应关系。然而移动场景元素违反极线约束,导致特征聚合不一致。因此,作者执行运动调整(motion-adjust)特征聚合。**Motion trajectory fileds(运动轨迹场) **文中使用根据学习基函数描述的运动轨迹场来表示场景运动。对于时刻i沿目标射线r的给定3D点x,用MLP GMT编码其轨迹系数: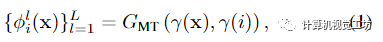 其中
其中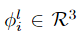 是基系数(使用下面描述的运动基,x、y、z分别有系数),γ表示位置编码。本文还引入了全局可学习的运动基
是基系数(使用下面描述的运动基,x、y、z分别有系数),γ表示位置编码。本文还引入了全局可学习的运动基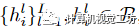 ,它跨越输入视频的每一个时间步长i,并与MLP联合优化。将x的运动轨迹定义为
,它跨越输入视频的每一个时间步长i,并与MLP联合优化。将x的运动轨迹定义为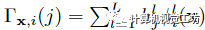 ,则在j时刻x与其三维对应xi→j之间的相对位移计算为:
,则在j时刻x与其三维对应xi→j之间的相对位移计算为: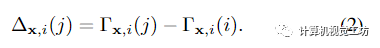 使用这种运动轨迹表示,在邻近视图中查找查询点x的3D对应关系只需要一个MLP查询,从而在本文的体绘制框架内实现高效的多视图特征聚合。利用x在时刻i的估计运动轨迹,作者将x在时刻j对应的三维点记为。使用相机参数将每个扭曲点投影到其源视图中,并在投影的2D像素位置提取颜色和特征向量。通过加权平均池化将输出特征聚合到共享MLP中,从而在沿射线r的每个3D样本点处生成单个特征向量。然后,具有时间嵌入的Ray Transformer网络沿射线处理聚合特征序列,以预测每个样本的颜色和密度。然后,我们使用标准NeRF体渲染,从这个颜色和密度序列中获得射线的最终像素颜色。
使用这种运动轨迹表示,在邻近视图中查找查询点x的3D对应关系只需要一个MLP查询,从而在本文的体绘制框架内实现高效的多视图特征聚合。利用x在时刻i的估计运动轨迹,作者将x在时刻j对应的三维点记为。使用相机参数将每个扭曲点投影到其源视图中,并在投影的2D像素位置提取颜色和特征向量。通过加权平均池化将输出特征聚合到共享MLP中,从而在沿射线r的每个3D样本点处生成单个特征向量。然后,具有时间嵌入的Ray Transformer网络沿射线处理聚合特征序列,以预测每个样本的颜色和密度。然后,我们使用标准NeRF体渲染,从这个颜色和密度序列中获得射线的最终像素颜色。
3.2 Cross-time rendering for temporal consistency(跨时间渲染以实现时间一致性)
如果通过单独比较和 来优化我们的动态场景表示,则表示可能会过度拟合输入图像。这可能是因为表示有能力为每个时间实例重建完全独立的模型,而无需利用或准确地重建场景运动。因此,为了恢复具有物理上合理的运动的一致场景,本文强制场景表示的时间相干性。在这种情况下定义时间一致性的一种方法是在考虑场景运动时,两个相邻时间 i 和 j 的场景应该是一致的。
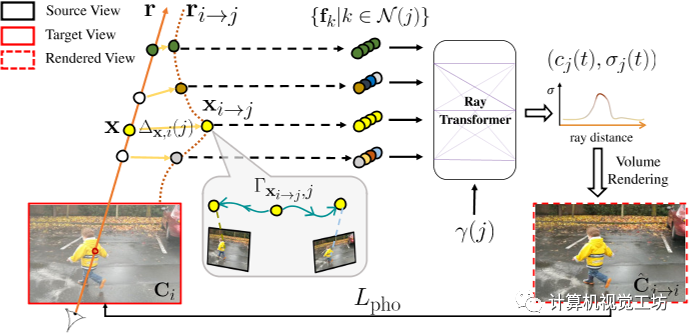
图三:通过跨时间渲染实现时间一致性。为了加强动态重建中的时间一致性,我们使用来自附近时间j的场景模型渲染每个帧Ii,我们称之为跨时间渲染。图像i中的射线r使用弯曲射线ri→j渲染,即r扭曲到时间j。也就是说,从沿r的每个采样位置计算出在时间j附近的运动调整点xi→j = x+∆x,i(j),我们通过MLP查询xi→j和时间j,预测其运动轨迹Γxi→j,j,我们将从时间k∈N (j)内的源视图中提取的图像特征fk聚合在一起。沿着ri→jr聚合的特征通过时间嵌入γ(j)输入到射线转换器中,在j时刻生成每个样本的颜色和密度(cj, σj)。通过体绘制计算得到像素颜色(cj, σj) mj→iis,然后与地面真色Ci进行比较,形成重建损失Lpho。
特别是,本文通过在运动调整的光线空间中的跨时间渲染来加强优化表示中的时间光度一致性。具体为通过时间i附近的某个时间j来时间i渲染视图,称之为跨时间渲染。对于每个附近的时间 j ∈ N (i),不是直接使用沿光线 r 的点 x,而是考虑沿运动调整的光线 的点 并将它们视为它们位于时间 j 的光线上。具体来说,在计算运动调整点时,查询MLP来预测新轨迹并使用公式2计算时间窗口N (j)中图像k对应的3D点然后使用这些新的三维对应关系精确地渲染像素颜色,如第3.1节中“直”射线所述,除了现在沿着弯曲的、运动调整的射线 。也就是,每个点被投影到其源视图和具有相机参数 的特征图 以提取 RGB 颜色和图像特征 ,然后将这些特征聚合并输入到具有时间嵌入 的光线转换器。结果是在时间j沿的颜色和密度序列,可以通过体绘制合成以形成颜色。然后通过运动错位感知 RGB 重建损失将 与目标像素 进行比较
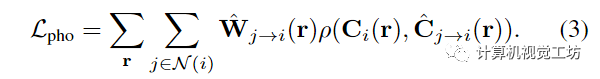
对 RGB 损失 ρ 使用广义 Charbonnier 损失,是运动错位权重,由时间 i 和 j 之间的累积 alpha 权重的差异计算,以解决 NSSF 描述的运动错位歧义。
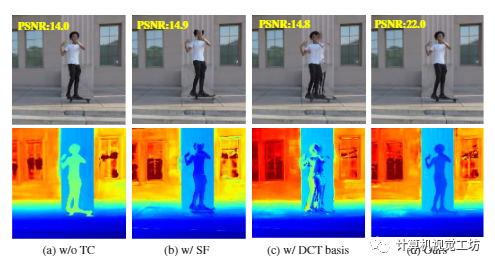
图4 定性消融。从左到右,我们展示了我们的系统 (a) 中渲染的新视图(顶部)和深度(底部),而不强制执行时间一致性,(b) 使用场景流场而不是运动轨迹聚合图像特征,(c) 表示具有固定 DCT 基础的运动轨迹而不是学习的视图,以及 (d) 具有完整配置。简单配置显著降低了渲染质量
上图的第一列中展示了使用和不使用时间一致性的方法之间的比较。
3.3 Combining static and dynamic models(结合静态和动态模型)
正如在NSFF中观察到的,使用小时间窗口合成新视图不足以恢复静态场景区域的完整和高质量的内容,因为相机路径不受控制的,内容只能在空间上遥远的帧中观察到。因此,我们遵循NSFF的思想,并使用两个独立的表示对整个场景进行建模。动态内容 用如上所述的时变模型表示(在优化过程中用于跨时间渲染)。静态内容用时不变模型表示,该模型以与时变模型相同的方式呈现,但在没有场景运动调整(即沿极线)的情况下聚合多视图特征。使用NeRF-W的静态和瞬态模型相结合的方法,将动态和静态预测组合成单个输出颜色(或跨时间渲染期间的)。每个模型都的颜色和密度估计也可以单独渲染,为静态内容提供颜色,为动态内容提供。结合这两种表示时,我们将公式3中的光度一致性项重写为将与目标像素 进行比较的损失:
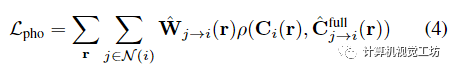
Image-based motion segmentation(基于图像的运动分割)在本文的框架中,作者观察到,在没有任何初始化的情况下,场景分解往往以时不变或时变表示为主。为了便于分解,作者提出了一种新的运动分割模块,该模块生成分割掩码来监督本文的主要双分量场景表示。该想法是受到最近的工作中提出的贝叶斯学习技术的启发,但集成到动态视频的体积IBR表示中。在训练主要双分量场景表示之前,联合训练两个轻量级模型来获得每个输入帧的运动分割掩码。使用IBRNet对静态场景内容进行建模,IBRNet通过沿附近源视图的极线特征聚合沿每条射线渲染像素颜色,而不考虑场景运动;我们使用二维卷积编码器-解码器网络D对动态场景内容进行建模,该网络从输入帧预测二维不透明度图、置信图和RGB图像: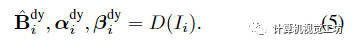 然后,从两个模型的输出像素级合成完整的重建图像:
然后,从两个模型的输出像素级合成完整的重建图像: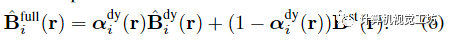 为了分割移动对象,我们假设观察到的像素颜色以异方差任意方式不确定,并使用具有时间依赖置信度 的 Cauchy 分布对视频中的观察结果进行建模。通过取观察的负对数似然,我们的分割损失写成加权重建损失:
为了分割移动对象,我们假设观察到的像素颜色以异方差任意方式不确定,并使用具有时间依赖置信度 的 Cauchy 分布对视频中的观察结果进行建模。通过取观察的负对数似然,我们的分割损失写成加权重建损失:
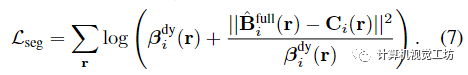
下图展示了我们估计的运动分割掩码叠加在输入图像上。

图 5. 运动分割。我们展示了覆盖渲染动态内容*(底部)的完整渲染(顶部)和运动分割。我们的方法分割具有挑战性的动态元素,例如移动阴影、摆动和摇摆灌木。
Supervision with segmentation masks(基于分割掩码的监督)本文使用掩码初始化主要时变和时不变模型,如Omnimatte,通过将重构损失应用于动态区域的时变模型的渲染,并从静态区域的时不变模型渲染:
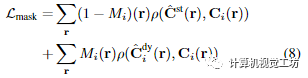
对进行形态侵蚀和膨胀,分别得到动态区域和静态区域的掩模,从而关闭掩模边界附近的损失。我们用 Lmask 监督系统,每 50K 优化步骤将动态区域的权重衰减 5 倍。
3.4 Regularization(正则化)
如前所述,复杂动态场景的单目重建是高度不适定的,单独使用光度一致性不足以在优化过程中避免糟糕的局部极小值。因此,我们采用先前工作中使用的正则化方案,该方案由三个主要部分组成是一个数据驱动的术语,由单眼深度和光流一致性先验组成,使用Zhang等人和RAFT的估计。是一个运动轨迹正则化项,它鼓励估计的轨迹场是周期一致的和时空平滑的。是一个紧实先验,它鼓励场景分解通过熵损失二进制,并通过失真损失减轻漂浮物。参考补充以获取更多详细信息。总之,用于优化时空视图合成的主要表示的最终组合损失是: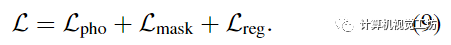
4 实验
4.1 Baselines and error metrics-评价指标
对比对象:Nerfies, HyperNeRF, NSFF, DVS评价指标:峰值信噪比 (PSNR)、结构相似性 (SSIM) 、通过 LPIPS 的感知相似性 ,并计算整个场景 (Full) 的误差并仅限于移动区域 (Dynamic Only)。这里也推荐「3D视觉工坊」新课程《如何学习相机模型与标定?(代码+实战)》。
4.2 Quantitative evaluation-定量评价
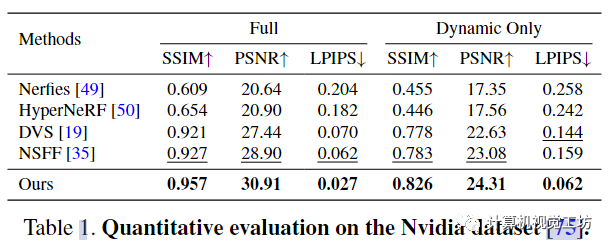
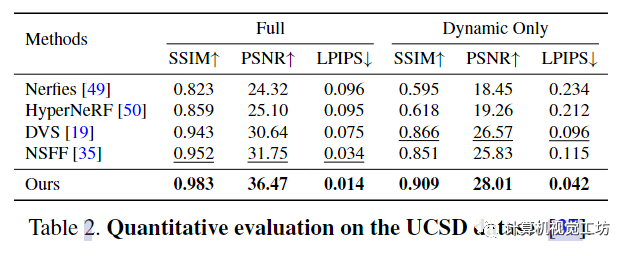
这些结果表明,本文的框架在恢复高度详细的场景内容方面更有效。
4.3 Ablations - 消融研究
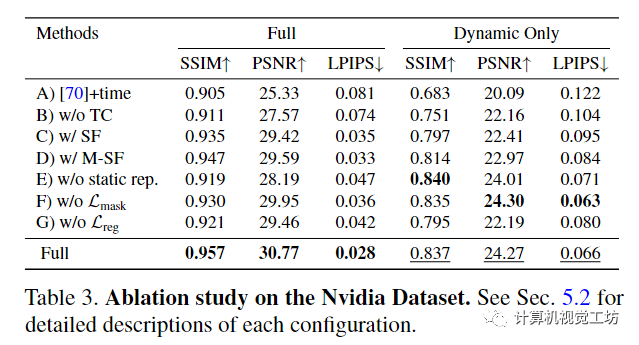
image.png
A)基线IBRNet,具有额外的时间嵌入;B)不通过跨时间渲染强制时间一致性;C)使用场景流场在一个时间步内聚合图像特征;D)预测多个3D场景流向量,指向每个样本附近2r次;E)不使用时不变静态场景模型;F)通过估计的运动分割掩码没有掩模重建损失;G)没有正则化损失。
对于该项消融研究,使用每条射线 64 个样本训练每个模型。如果没有我们的运动轨迹表示和时间一致性,视图合成质量显著下降,如表3的前三行所示。集成全局空间坐标嵌入进一步提高了渲染质量。结合静态和动态模型可以提高静态元素的质量,如完整场景的指标所示。最后,从运动分割或正则化中去除监督会降低整体渲染质量,证明了在优化过程中避免不良局部最小值的建议损失值。


先前的动态NeRF方法很难渲染运动物体的细节,如过于模糊的动态内容所示,包括气球、人脸和服装的纹理。相比之下,本文的方法综合了静态和动态场景内容的照片真实感新视图,最接近地面真实图像。


本文的方法综合了逼真的新视图,而先前的动态Nerf方法无法恢复静态和动态场景内容的高质量细节,例如图8中的衬衫皱纹和狗的毛皮。另一方面,显式深度扭曲在咬合和视野外的区域产生孔洞。
5 Discussion and conclusion-讨论与总结
Limitations(局限):由于不正确的初始深度和光流估计,我们的方法无法处理小的快速运动物体;与之前的动态NeRF方法相比,合成的视图并不是严格的多视图一致,静态内容的渲染质量取决于选择哪个源视图;本文的方法能够合成仅出现在遥远时间的动态内容

我们的方法可能无法对移动薄物体进行建模,例如移动皮带(左)。我们的方法只能渲染在远距离帧(中间)中可见的动态内容。如果为给定像素聚合源视图特征不足(右),则渲染的静态内容可能不切实际或空白。
结论:本文提出了一种从描述复杂动态场景的单目视频中合成时空视图合成的新方法。通过在体积IBR框架内表示动态场景,克服了最近的方法无法对具有复杂相机和物体运动的长视频进行建模的局限性。实验已经证明,本文的方法可以从野外动态视频中合成照片逼真的新视图,并且可以在动态场景基准上比以前的最先进方法取得显着改进。
-
ModelSource免费的原理图,PCB组件库 和 2D & 3D 模型下载2012-12-26 0
-
【原创】关于Altium Design中如何创建3D模型及设计教程V1.12013-04-03 0
-
Ansys Maxwell 3D 2D RMxprt v16.0 Win32-U\2014-06-13 0
-
关于利用2D图片利用投影的方法创建3D模型2014-10-08 0
-
针对显示屏的2D/3D触摸与手势开发工具包DV1020142018-11-07 0
-
如何同时获取2d图像序列和相应的3d点云?2018-11-13 0
-
从视频中跟踪脸部使用2D模式找不到任何面部2018-11-20 0
-
请问怎么才能将AD中的3D封装库转换为2D的封装库?2019-06-05 0
-
如何在AltiumPCB中2D库里导出3D?2019-09-11 0
-
为什么3D与2D模型不能相互转换?2019-09-20 0
-
你没看错,浩辰3D软件中CAD图纸与3D模型高效转化这么好用!2020-05-13 0
-
AD的3D模型绘制功能介绍2021-01-14 0
-
全程“3D模型动画”展示《高频变压器绕制视频教程》2022-03-10 0
-
视觉处理,2d照片转3d模型2023-05-21 0
全部0条评论

快来发表一下你的评论吧 !
