

YOLOv5网络结构训练策略详解
描述
前言
前面已经讲过了Yolov5模型目标检测和分类模型训练流程,这一篇讲解一下yolov5模型结构,数据增强,以及训练策略。
网络结构
Yolov5发布的预训练模型,包含yolov5l.pt、yolov5l6.pt、yolov5m.pt、yolov5m6.pt、yolov5s.pt、yolov5s6.pt、yolov5x.pt、yolov5x6.pt等。
针对不同大小的网络整体架构(n, s, m, l, x)都是一样的,只不过会在每个子模块中采用不同的深度和宽度,分别应对yaml文件中的depth_multiple和width_multiple参数。下面以yolov5l.yaml绘制的网络整体结构为例。
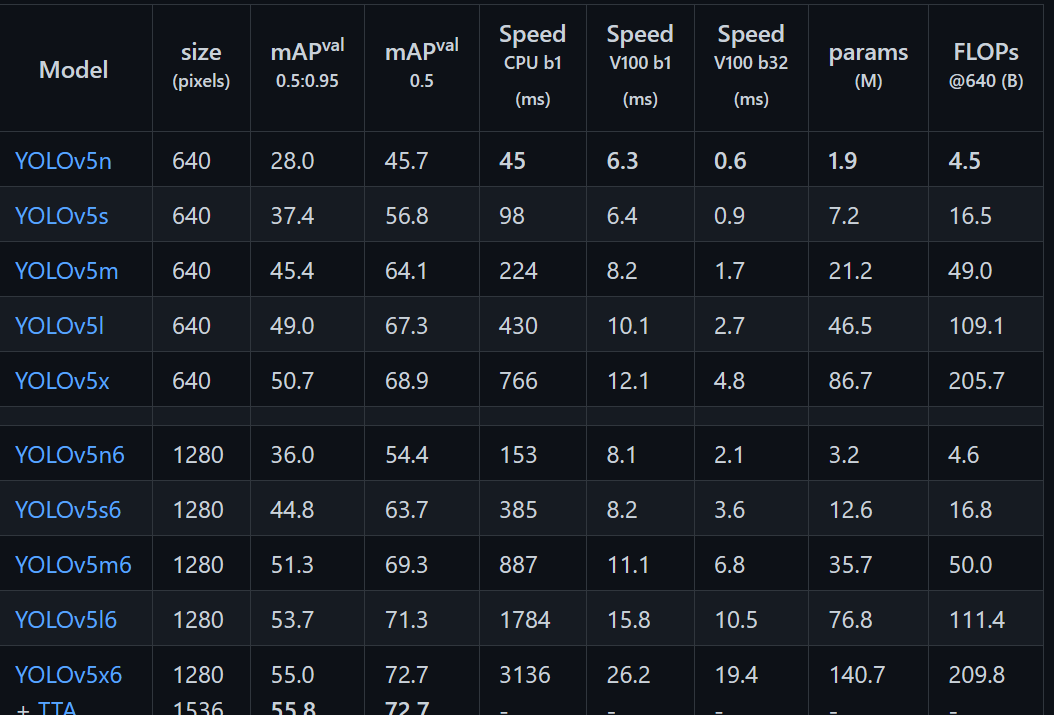
网络结构图:
网络结构主要由以下几部分组成:
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2) Backbone: New CSP-Darknet53
(3)Neck: SPPF, New CSP-PAN
(4)输出端:Head
官方网络结构图:
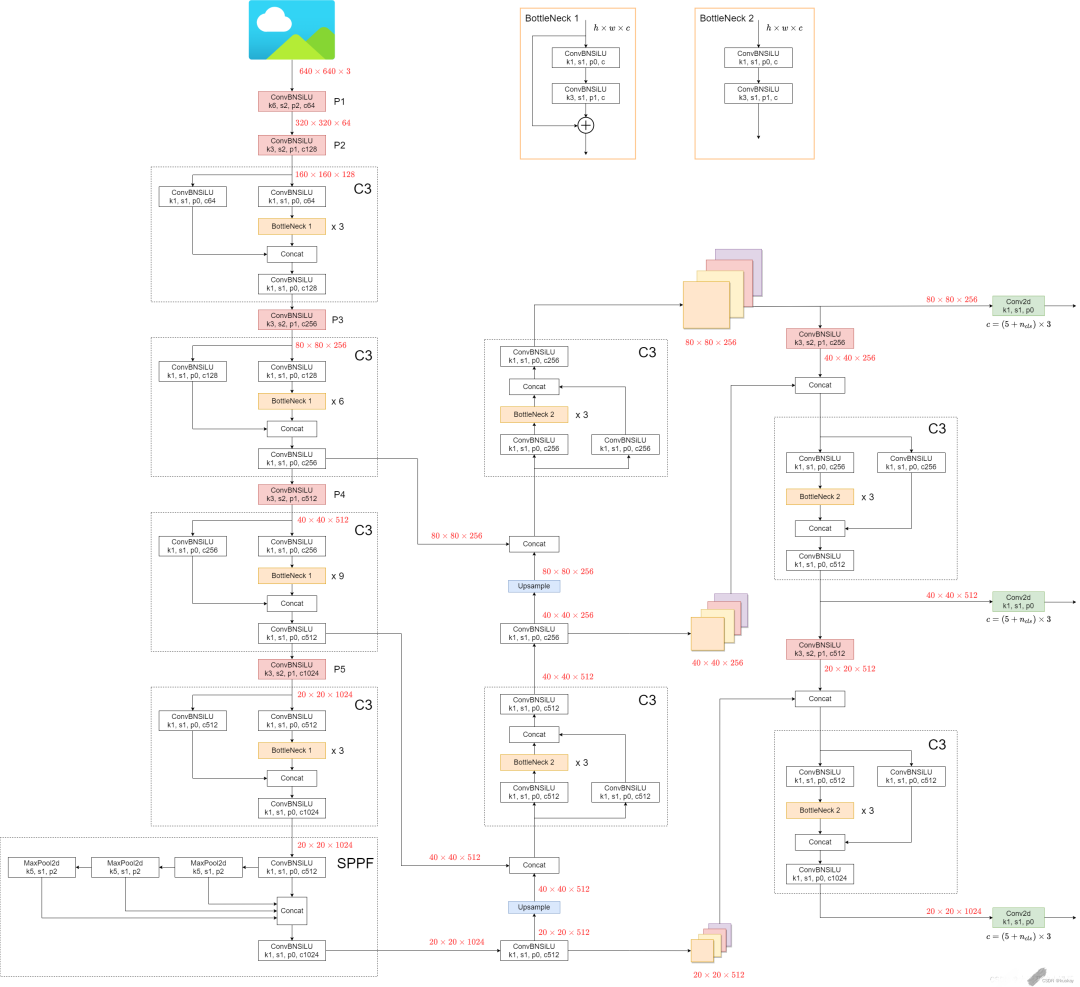
v5.x网络结构:

v6.x网络结构:
可以看出,相比于之前v5.x,最新版的v6.x网络结构更加精简(以提高速度和推理性能),主要有以下更新:
•Conv(k=6, s=2, p=2) 替换Focus,便于导出其他框架(for improved exportability)
•SPPF代替SPP,并且将SPPF放在主干最后一层(for reduced ops)
•主干中的C3层重复次数从9次减小到6次(for reduced ops)
•主干中最后一个C3层引入shortcut
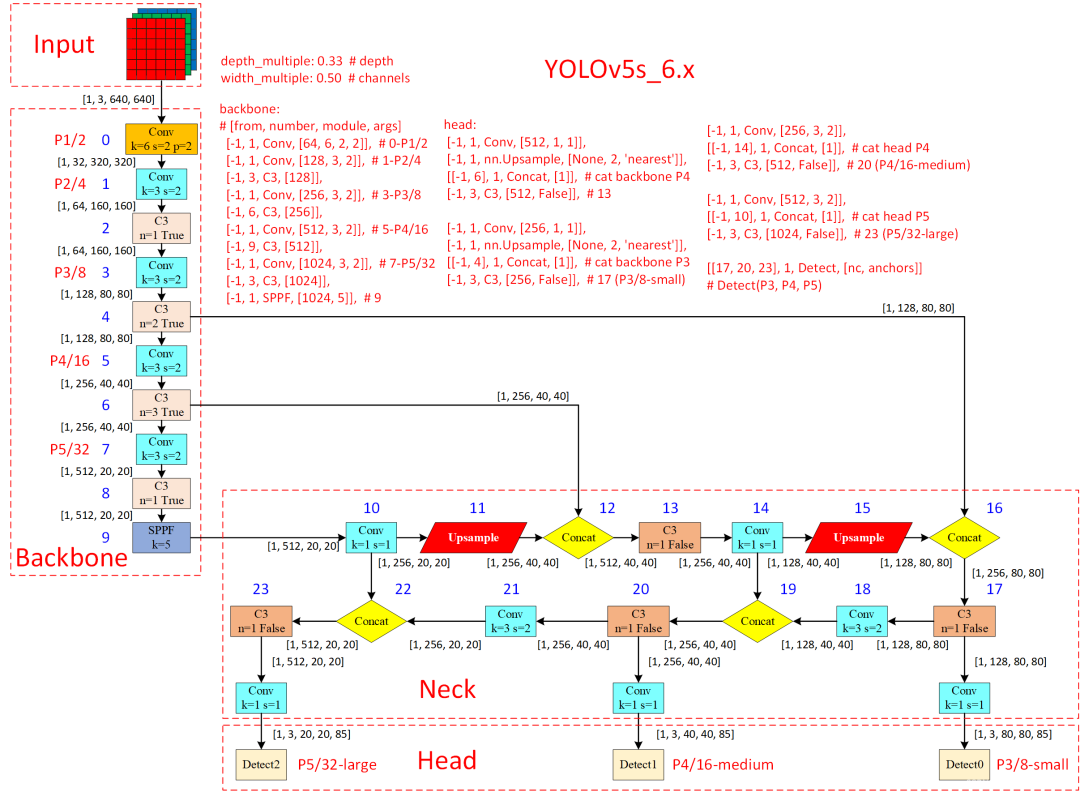
yolov5s.yaml文件内容:
nc: 80 # number of classes 数据集中的类别数 depth_multiple: 0.33 # model depth multiple 模型层数因子(用来调整网络的深度) width_multiple: 0.50 # layer channel multiple 模型通道数因子(用来调整网络的宽度) # 如何理解这个depth_multiple和width_multiple呢?它决定的是整个模型中的深度(层数)和宽度(通道数。 anchors: # 表示作用于当前特征图的Anchor大小为 xxx # 9个anchor,其中P表示特征图的层级,P3/8该层特征图缩放为1/8,是第3层特征 - [10,13, 16,30, 33,23] # P3/8, 表示[10,13],[16,30], [33,23]3个anchor - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5s v6.0 backbone backbone: # [from, number, module, args] [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 6, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 3, C3, [1024]], [-1, 1, SPPF, [1024, 5]], # 9 ] # YOLOv5s v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
nc是类别数;
depth_multiple表示channel的缩放系数,就是将配置里面的backbone和head部分有关通道的设置,全部乘以该系数即可;
而width_multiple表示BottleneckCSP模块的层缩放系数,将所有的BottleneckCSP模块的number系数乘上该参数就可以最终的层个数;如果希望大一点,就把这个数字改大一点,网络就会按比例变深、变宽;如果希望小一点,就把这个数字改小一点,网络就会按比例变浅、变窄。
anchors 解读
yolov5 初始化了 9 个 anchors,分别在三个特征图 (feature map)中使用,每个 feature map 的每个 grid cell 都有三个 anchor 进行预测。分配规则:
•尺度越大的 feature map 越靠前,相对原图的下采样率越小,感受野越小, 所以相对可以预测一些尺度比较小的物体(小目标),分配到的 anchors 越小。
•尺度越小的 feature map 越靠后,相对原图的下采样率越大,感受野越大, 所以可以预测一些尺度比较大的物体(大目标),所以分配到的 anchors 越大。
•即在小特征图(feature map)上检测大目标,中等大小的特征图上检测中等目标, 在大特征图上检测小目标。
backbone & head解读
[from, number, module, args] 参数
四个参数的意义分别是:
•第一个参数 from :从哪一层获得输入,-1表示从上一层获得,[-1, 6]表示从上层和第6层两层获得。
•第二个参数 number:表示有几个相同的模块,如果为9则表示有9个相同的模块。
•第三个参数 module:模块的名称,这些模块写在common.py中。
•第四个参数 args:类的初始化参数,用于解析作为 moudle 的传入参数,即[ch_out, kernel, stride, padding, groups][输出通道数量,卷积核尺寸,步长,padding],这里连ch_in都省去了,因为输入都是上层的输出(初始ch_in为3)
Backbone骨干网络
骨干网络是指用来提取图像特征的网络,它的主要作用是将原始的输入图像转化为多层特征图,以便后续的目标检测任务使用。
在Yolov5中,使用的是CSPDarknet53或ResNet骨干网络。Backbone中的主要结构有Conv模块、C3模块、SPPF模块。
Conv
Conv模块是卷积神经网络中常用的一种基础模块,它主要由卷积层、BN层和激活函数组成。下面对这些组成部分进行详细解析。
•卷积层是卷积神经网络中最基础的层之一,用于提取输入特征中的局部空间信息。
•BN层是在卷积层之后加入的一种归一化层,用于规范化神经网络中的特征值分布。
•激活函数是一种非线性函数,用于给神经网络引入非线性变换能力。常用的激活函数包括sigmoid、ReLU、LeakyReLU、ELU等。
C3模块
C3模块是YOLOv5网络中的一个重要组成部分,其主要作用是增加网络的深度和感受野,提高特征提取的能力。
C3模块是由三个Conv块构成的,其中第一个Conv块的步幅为2,可以将特征图的尺寸减半,第二个Conv块和第三个Conv块的步幅为1。C3模块中的Conv块采用的都是3x3的卷积核。在每个Conv块之间,还加入了BN层和LeakyReLU激活函数,以提高模型的稳定性和泛化性能。
Neck特征金字塔
在Neck部分的变化还是相对较大的,首先是将SPP换成成了SPPF,其次是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。
SPPF模块
SPP
SPP模块是何凯明大神在2015年的论文《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》中被提出。
SPP全程为空间金字塔池化结构,主要是为了解决两个问题:
•有效避免了对图像区域裁剪、缩放操作导致的图像失真等问题;
•解决了卷积神经网络对图相关重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
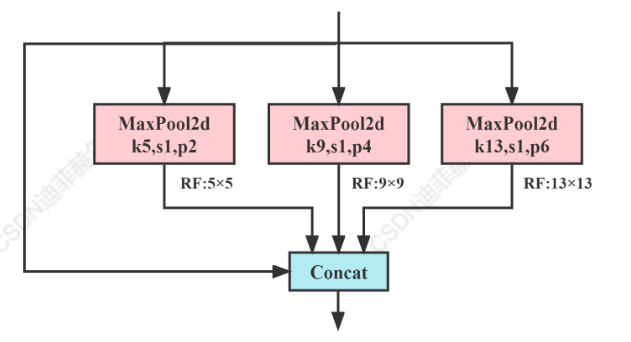
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
SPPF
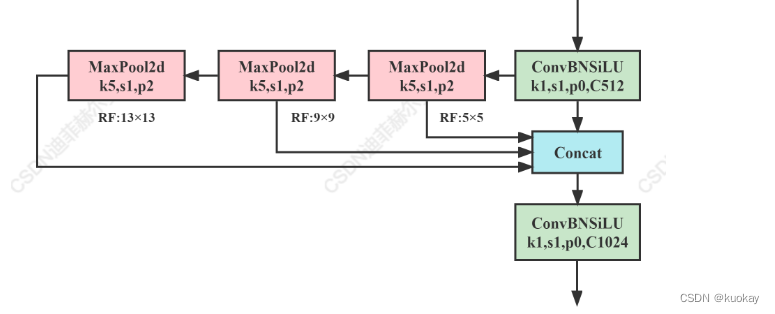
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
CSP-PAN
在Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。
CSP
YOLOv5s的CSP结构是将原输入分成两个分支,分别进行卷积操作使得通道数减半,然后一个分支进行Bottleneck * N操作,然后concat两个分支,使得BottlenneckCSP的输入与输出是一样的大小,这样是为了让模型学习到更多的特征。
YOLOv5中的CSP有两种设计,分别为CSP1_X结构和CSP2_X结构。
PAN
Yolov5 的 Neck 部分采用了 PANet 结构,Neck 主要用于生成特征金字塔。特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。
PANet 结构是在FPN的基础上引入了 Bottom-up path augmentation 结构。
PANet[1]最大的贡献是提出了一个自顶向下和自底向上的双向融合骨干网络,同时在最底层和最高层之间添加了一条“short-cut”,用于缩短层之间的路径。PANet还提出了自适应特征池化(Adaptive Features Pooling)和全连接融合(Fully-connected Fusion)两个模块。其中自适应特征池化可以用于聚合不同层之间的特征,保证特征的完整性和多样性,而通过全连接融合可以得到更加准确的预测mask。
Head目标检测头
目标检测头是用来对特征金字塔进行目标检测的部分,它包括了一些卷积层、池化层和全连接层等。
head中的主体部分就是三个Detect检测器,即利用基于网格的anchor在不同尺度的特征图上进行目标检测的过程。
head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
数据增强
1.Mosaic数据增强
将四张图片拼成一张图片,采用随机缩放、随机裁剪、随机排布的方式进行拼接。
优点:
1. 丰富数据集
2. 减少GPU
2.Copy paste数据增强
将部分目标随机的粘贴到图片中,前提是数据要有segments数据才行,即每个目标的实例分割信息。
3. Random affine仿射变换
yolov5的仿射变换包含随机旋转、平移、缩放、错切操作,和yolov3-spp一样,代码都没有改变。据配置文件里的超参数发现只使用了Scale和Translation即缩放和平移。
4. MixUp数据增强
就是将两张图片按照一定的透明度融合在一起。
5. HSV(Augment HSV(Hue, Saturation, Value))随机增强图像
随机调整色度,饱和度以及明度。
6.Random horizontal flip随机水平翻转
随机上下左右的水平翻转
7. Cutout数据增强
Cutout是一种新的正则化方法。训练时随机把图片的一部分减掉,这样能提高模型的鲁棒性。它的来源是计算机视觉任务中经常遇到的物体遮挡问题。通过cutout生成一些类似被遮挡的物体,不仅可以让模型在遇到遮挡问题时表现更好,还能让模型在做决定时更多地考虑环境。
Cutout数据增强在之前也见过很多次了。在yolov5的代码中默认也是不启用的。
8. Albumentations数据增强工具包
该工具最大的好处是会根据你使用的数据增强方法自动修改标注框信息!
albumentations 是一个给予 OpenCV的快速训练数据增强库,拥有非常简单且强大的可以用于多种任务(分割、检测)的接口,易于定制且添加其他框架非常方便。
它可以对数据集进行逐像素的转换,如模糊、下采样、高斯造点、高斯模糊、动态模糊、RGB转换、随机雾化等;也可以进行空间转换(同时也会对目标进行转换),如裁剪、翻转、随机裁剪等。
YOLOV5的训练技巧
1.训练预热 Warmup
刚开始训练时,模型的权重是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡)。选择Warmup预热学习率的方式可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
常见Warmup类型
1. Constant Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持不变
2. Constant Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持不变
3. Constant Warmup
在前面100epoch里,学习率线性增加,大于100epoch以后保持不变
超参数设置
在yolov5中data/hyps/hyp.scratch-*.yaml三个文件中,都存在着warmup_epoch代表训练预热轮次
2. 自动调整锚定框——Autoanchor
预定义边框就是一组预设的边框,在训练时,以真实的边框位置相对于预设边框的偏移来构建(也就是我们打下的标签)
训练样本。这就相当于,预设边框先大致在可能的位置“框“出来目标,然后再在这些预设边框的基础上进行调整。
一个Anchor Box可以由:边框的纵横比和边框的面积(尺度)来定义,相当于一系列预设边框的生成规则,根据Anchor Box,可以在图像的任意位置,生成一系列的边框
3.超参数进化
yolov5提供了一种超参数优化的方法–Hyperparameter Evolution,即超参数进化。超参数进化是一种利用 遗传算法(GA) 进行超参数优化的方法,我们可以通过该方法选择更加合适自己的超参数。
提供的默认参数也是通过在COCO数据集上使用超参数进化得来的。由于超参数进化会耗费大量的资源和时间,如果默认参数训练出来的结果能满足你的使用,使用默认参数也是不错的选择。
4.冻结训练——Freeze training
冻结训练的作用:当我们已有部分预训练权重,这部分预训练权重所应用的那部分网络是通用的,如骨干网络,那么我们可以先冻结这部分权重的训练,将更多的资源放在训练后面部分的网络参数,这样使得时间和资源利用都能得到很大改善。然后后面的网络参数训练一段时间之后再解冻这些被冻结的部分,这时再全部一起训练。
5.多尺度训练——multi-scale training
当前的多尺度训练(Multi Scale Training,MST)通常是指设置几种不同的图片输入尺度,训练时从多个尺度中随机选取一种尺度,将输入图片缩放到该尺度并送入网络中,是一种简单又有效的提升多尺度物体检测的方法。
虽然一次迭代时都是单一尺度的,但每次都各不相同,增加了网络的鲁棒性,又不至于增加过多的计算量。而在测试时,为了得到更为精准的检测结果,也可以将测试图片的尺度放大,例如放大4倍,这样可以避免过多的小物体。
6. 加权图像策略
图像加权策略可以解决样本不平衡的,具体操作步骤图下:
根据样本种类分布使用图像调用频率不同的方法解决。
1. 读取训练样本中的GT,保存为一个列表;
2. 计算训练样本列表中不同类别个数,然后给每个类别按相应目标框数的倒数赋值,数目越多的种类权重越小,形成按种类的分布直方图;
3. 对于训练数据列表,训练时按照类别权重筛选出每类的图像作为训练数据。使用random.choice(population, weights=None, *, cum_weights=None, k=1)更改训练图像索引,可达到样本均衡的效果。
7.矩形推理——Rectangular Inference
通常YOLO系列网络的输入都是预处理后的方形图像数据,如416 * 416、608 * 608。当原始图像为矩形时,会将其填充为方形(如下图:方形输入),但是填充的灰色区域其实就是冗余信息,不论是在训练还是推理阶段,这些冗余信息都会增加耗时。
为了减少图像的冗余数据,输入图像由方形改为矩形(如下图:矩形输入):将长边resize为固定尺寸(如416),短边按同样比例resize,然后把短边的尺寸尽量少地填充为32的倍数。
这种方法在推理阶段称为矩形推理(Rectangular Inference),在训练阶段则称为矩形训练(Rectangular Training)。推理阶段直接对图像进行resize和pad就行,但是训练阶段输入的是一个批次的图像集合,需要保持批次内的图像尺寸一致,因此处理逻辑相对复杂一些。
8.非极大值抑制——NMS
在目标检测的预测阶段时,会输出许多候选的anchor box,其中有很多是明显重叠的预测边界框都围绕着同一个目标,这时候我就可以使用NMS来合并同一目标的类似边界框,或者说是保留这些边界框中最好的一个。
9. 断点训练
在用yolov5训练数据的过程中由于突发情况训练过程突然中断,从头训练耗时,想接着上次训练继续训练怎么办。放心,在yolov5中给我们提供现成的参数–resume
10.早停机制(Early Stopping)
patience:训练了多少个epoch,如果模型效果未提升,就让模型提前停止训练。
fitness监控的是增大的数值,例如mAP,如果mAP在连续训练patience次内没有增加就停止训练。
11.多GPU训练
审核编辑:汤梓红
-
使用Yolov5 - i.MX8MP进行NPU错误检测是什么原因?2023-03-31 0
-
龙哥手把手教你学视觉-深度学习YOLOV5篇2021-09-03 0
-
怎样使用PyTorch Hub去加载YOLOv5模型2022-07-22 0
-
YOLOv5网络结构解析2022-10-31 0
-
如何YOLOv5测试代码?2023-05-18 0
-
请问从yolov5训练出的.pt文件怎么转换为k210可以使用的.kmodel文件?2023-09-13 0
-
基于YOLO-V5的网络结构及实现行人社交距离风险提示2022-07-06 2677
-
YOLOv5 7.0版本下载与运行测试2022-11-30 2807
-
yolov5训练部署全链路教程2023-01-05 2379
-
在C++中使用OpenVINO工具包部署YOLOv5模型2023-02-15 2205
-
使用旭日X3派的BPU部署Yolov52023-04-26 555
-
Yolov5算法解读2023-05-17 4472
-
【教程】yolov5训练部署全链路教程2023-01-29 2867
-
yolov5和YOLOX正负样本分配策略2023-08-14 1788
全部0条评论

快来发表一下你的评论吧 !
