

基于全稀疏的单阶段3D目标检测器优化方案
人工智能
描述
作者:王利民
本文介绍我们在 3D 目标检测领域的新工作:SparseBEV。我们所处的 3D 世界是稀疏的,因此稀疏 3D 目标检测是一个重要的发展方向。然而,现有的稀疏3D目标检测模型(如 DETR3D[1],PETR[2] 等)和稠密3D检测模型(如 BEVFormer[3],BEVDet[8])在性能上尚有差距。针对这一现象,我们认为应该增强检测器在 BEV 空间和 2D 空间的适应性(adaptability)。基于此,我们提出了高性能、全稀疏的 SparseBEV 模型。在 nuScenes 验证集上,SparseBEV 在取得 55.8 NDS 性能的情况下仍能维持 23.5 FPS 的实时推理速度。在 nuScenes 测试集上,SparseBEV 在仅使用 V2-99 这种轻量级 backbone 的情况下就取得了 67.5 NDS 的超强性能。如果用上 HoP[5] 和 StreamPETR-large[6] 等方法中的 ViT-large 作为 backbone,冲上 70+ 不在话下。
我们的工作已被 ICCV 2023 接收,论文、代码和权重(包括我们在榜单上 67.5 NDS 的模型)均已公开:

在CVer微信公众号后台回复:SparseBEV,可下载本论文pdf和代码
SparseBEV: High-Performance Sparse 3D Object Detection from Multi-Camera Videos
论文:https://arxiv.org/abs/2308.09244
代码:https://github.com/MCG-NJU/SparseBEV
1. 引言
现有的 3D 目标检测方法可以被分类为两种:基于稠密 BEV 特征的方法和基于稀疏 query 的方法。前者需要构建稠密的 BEV 空间特征,虽然性能优越,但是计算复杂度较大;基于稀疏 query 的方法避免了这一过程,结构更简单,速度也更快,但是性能还落后于基于 BEV 的方法。因而我们自然而然地提出疑问:基于稀疏 query 的方法是否可以实现和基于稠密 BEV 的方法接近甚至更好的性能?
根据我们的实验分析,我们认为实现这一目标的关键在于提升检测器在 BEV 空间和 2D 空间的适应性。这种适应性是针对 query 而言的,即对于不同的 query,检测器要能以不同的方式来编码和解码特征。这种能力正是之前的全稀疏 3D 检测器 DETR3D 所欠缺的。因此,我们提出了 SparseBEV,主要做了三个改进。首先,设计了尺度自适应的自注意力模块(scale-adaptive self attention, SASA)以实现在 BEV 空间的自适应感受野。其次,我们设计了自适应性的时空采样模块以实现稀疏采样的自适应性,并充分利用长时序的优势。最后,我们使用动态 Mixing 来自适应地 decode 采到的特征。
早在今年的2月9日,ICCV 投稿前夕,我们的 SparseBEV(V2-99 backbone)就已经在 nuScenes 测试集上取得了65.6 NDS 的成绩,超过了 BEVFormer V2[7] 等方法。如下图所示,该方案命名为 SparseBEV-Beta,具体可见 eval.ai 榜单。
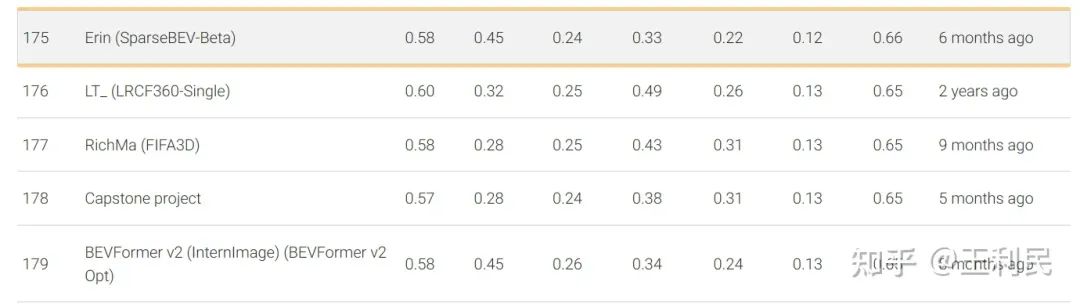
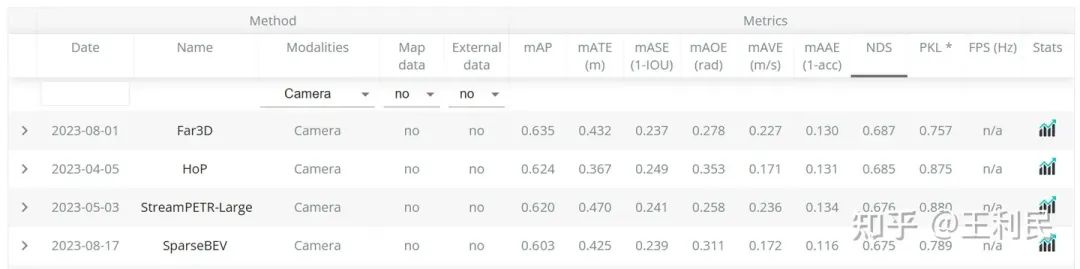
最近,我们采用了一些来自 StreamPETR 的最新 setting,包括将 bbox loss 的 X 和 Y 的权重调为 2.0,并使用 query denoising 来稳定训练等等。现在,仅采用轻量级 V2-99 作为 backbone 的 SparseBEV 在测试集上就能够实现 67.5 NDS 的超强性能,在纯视觉 3D 检测排行榜中排名第四(前三名均使用重量级的 ViT-large 作为 backbone):
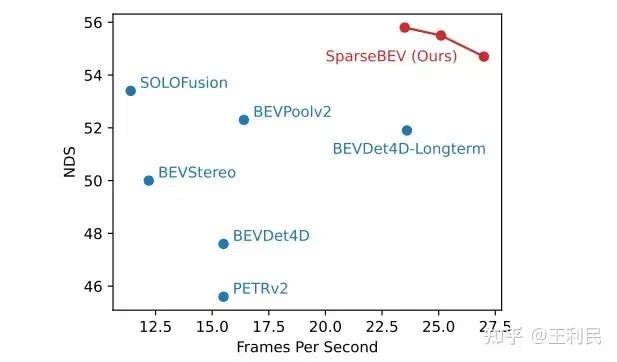
在验证集的小规模的 Setting(ResNet50,704x256)下,SparseBEV 能取得 55.8 NDS 的性能,同时保持 23.5 FPS 的实时推理速度,充分发挥了 Sparse 设计带来的优势。
2. 方法
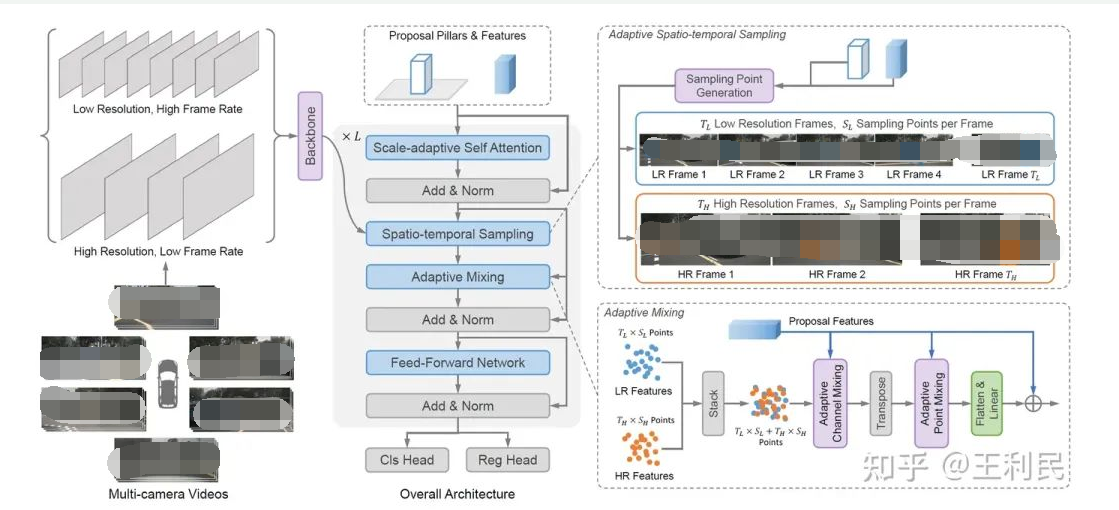
模型架构
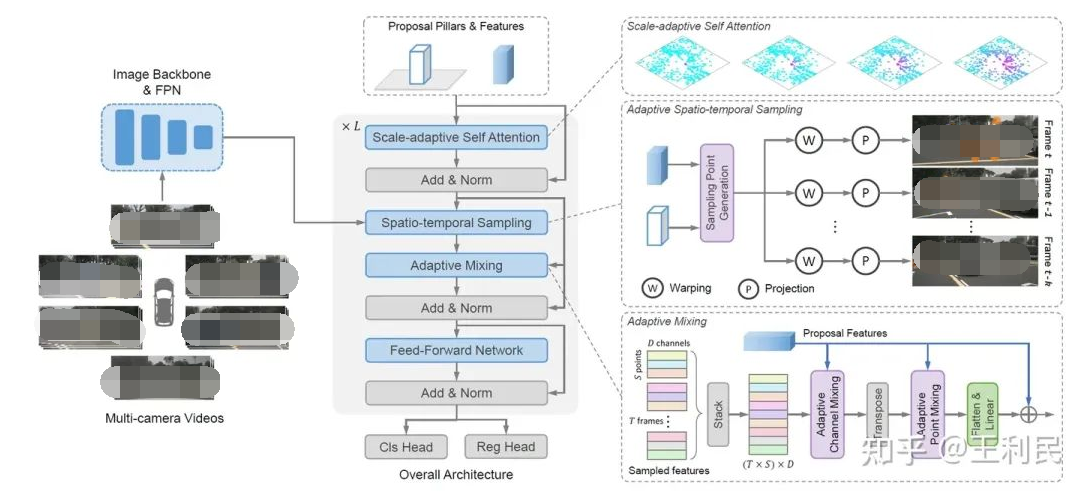
SparseBEV 的模型架构如上所示,其核心模块包括尺度自适应自注意力、自适应时空采样、自适应融合。

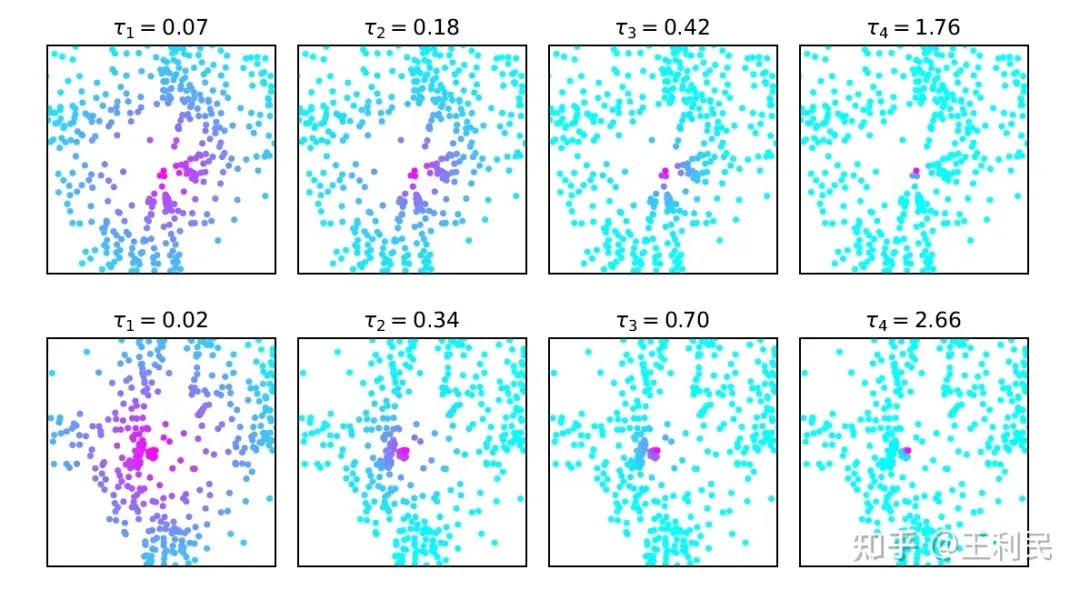
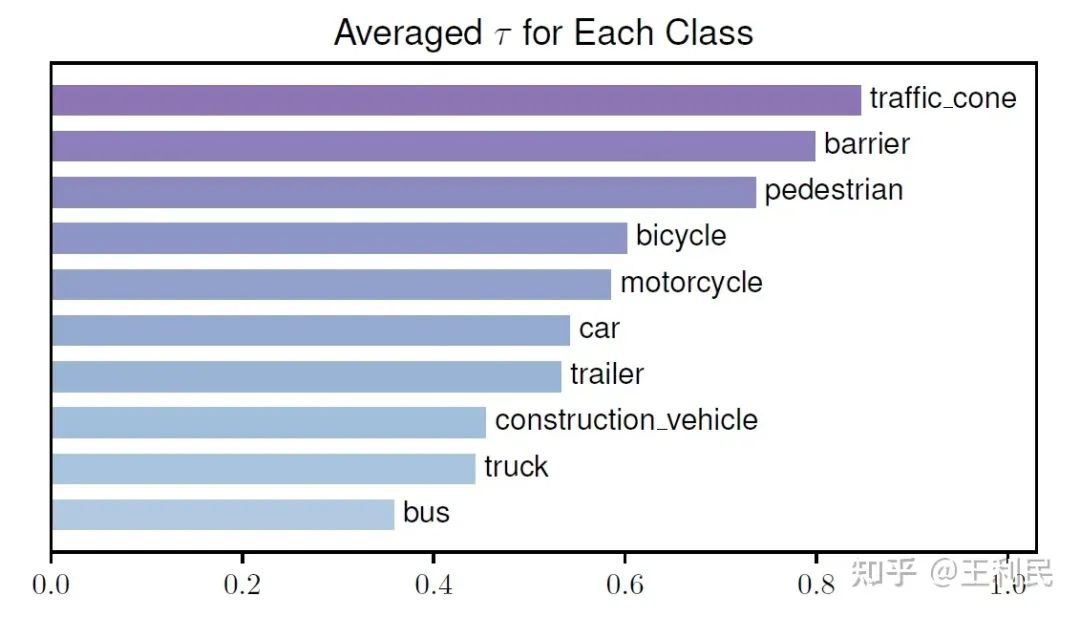
二:不同类别的物体所对应的 query 生成的 τ 值有着明显差异。我们发现,大物体(例如公交车)对应 query 的感受野明显大于小物体对应 query(例如行人)的感受野。(如下图所示。注意:τ 越大,感受野越小)
相比于标准的 MHSA,SASA 几乎没有引入额外开销,简单又有效。在消融实验中,使用 SASA 替换 MHSA 能直接暴涨 4.0 mAP 和 2.2 NDS:

Adaptive Spatio-temporal Sampling

这样,我们生成的采样点可以适应于给定的 query,从而能够更好地处理不同尺寸、远近的物体。同时,这些采样点并不局限于给定的 query bbox 内部,它们甚至可以撒到框外面去,这由模型自己决定。
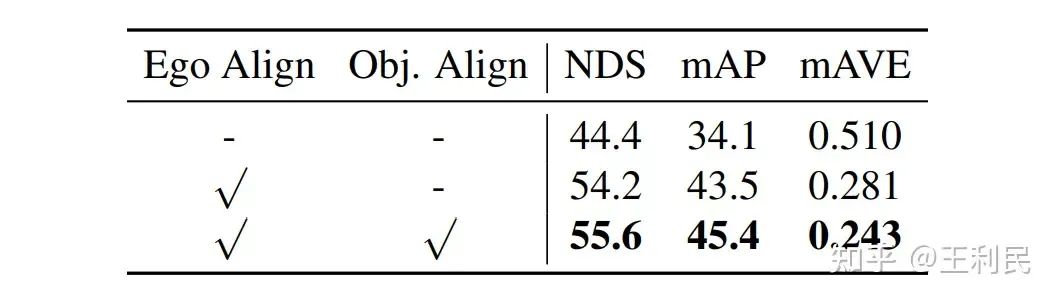
接着,为了进一步捕捉长时序的信息,我们将采样点 warp 到不同时刻的坐标系中,以此实现帧间对齐。在自动驾驶场景中,有两种类型的运动:一是车自身的运动(ego motion),二是其他物体的运动(object motion)。对于 ego motion,我们使用数据集提供的 ego pose 来实现对齐;对于 object motion,我们利用 query 中定义的瞬时速度向量,并配合一个简单的匀速运动模型来对运动物体进行自适应的对齐。这两种对齐操作都能涨点:
随后我们将 3D 采样点投影到 2D 图像并通过双线性插值获取对应位置的 2D 特征。这里有一个工程上的小细节:由于是六张图的环视输入,DETR3D 是将每个采样点分别投影到六个视图中,并对正确的投影点抽到的特征取平均。我们发现,大多数情况下就只有一个投影点是正确的,偶尔会有两个(即采样点位于相邻视图的重叠区域)。于是,我们干脆只取其中一个投影点(即使有时会有两个),把它对应的视图 ID 作为一个新的坐标轴,从而可以通过 Pytorch 内置的 grid sample 算子的 3D 版一步到位。这样可以显著提速,并且不咋掉点(印象里只掉了 0.1~0.2 NDS)。具体可以看代码:
github.com/MCG-NJU/SparseBEV/blob/main/models/sparsebev_sampling.py.py
对于稀疏采样这块,我们后来也基于 Deformable DETR 写了一个 CUDA 优化。不过,纯 PyTorch 实现其实也挺快的,CUDA 优化进一步提速了 15% 左右。
我们还提供了采样点的可视化(第一行是当前帧,二三两行是历史前两帧),可以看到,SparseBEV 的采样点精准捕捉到了场景中不同尺度的物体(即在空间上具备适应性),且对于不同运动速度的物体也能很好的对齐(即在时间上具备适应性)。

Dual-branch SparseBEV
在实验中,我们发现将输入的多帧图像分为 Fast、Slow 两个分支处理可以进一步提升性能。具体地,我们将输入分为高分辨率、低帧率的 Slow 分支和低分辨率、高帧率的 Fast 分支。于是,Slow 分支专注于提取高分辨率的静态细节,而 Fast 分支则专注于捕获运动信息。加入 Dual-branch 的 SparseBEV 结构图如下所示:
Dual-branch 设计不光减小了训练开支,还显著提升了性能,具体可见补充材料。它的涨点说明了自驾长时序中的静态细节和运动信息应该解耦处理。但是,它把整个模型搞得太复杂,因此我们默认情况下并没有使用它(本文中只有测试集 NDS=63.6 的那行结果用了它)。
3. 实验结果
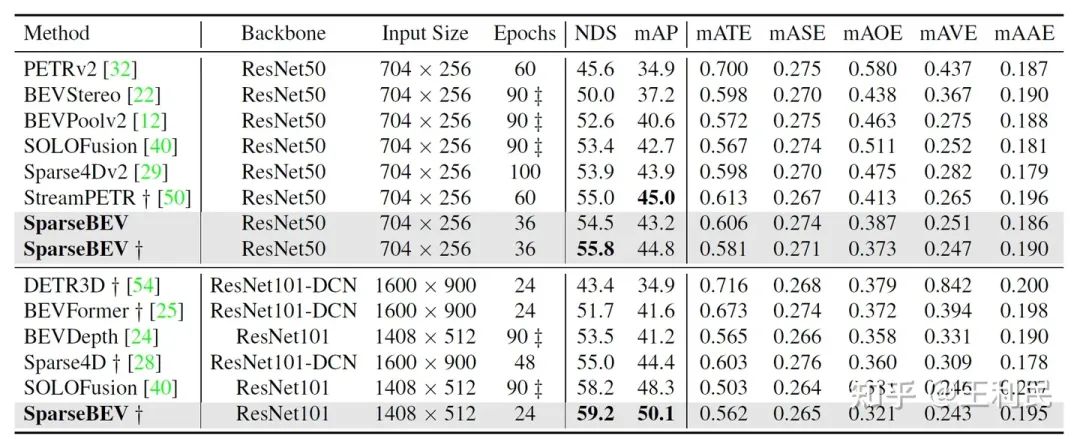
上表为 SparseBEV 与现有方法在 nuScenes 的验证集上的结果对比,其中 † 表示方法使用了透视预训练。在使用 ResNet-50 作为 backbone 和 900 个 query,且输入图像分辨率为 704x256 的情况下,SparseBEV 超越现有最优方法 SOLOFusion[4] 0.5 mAP 和 1.1 NDS。在使用 nuImages 预训练并将 query 数量降低到 400 后,SparseBEV 在达到 55.8 的 NDS 的情况下仍能维持 23.5 FPS 的推理速度。而将 backbone 升级为 ResNet-101 并将输入图像尺寸升为 1408x512 后,SparseBEV 超越 SOLOFusion 达 1.8 mAP 和 1.0 NDS。
nuScenes test split
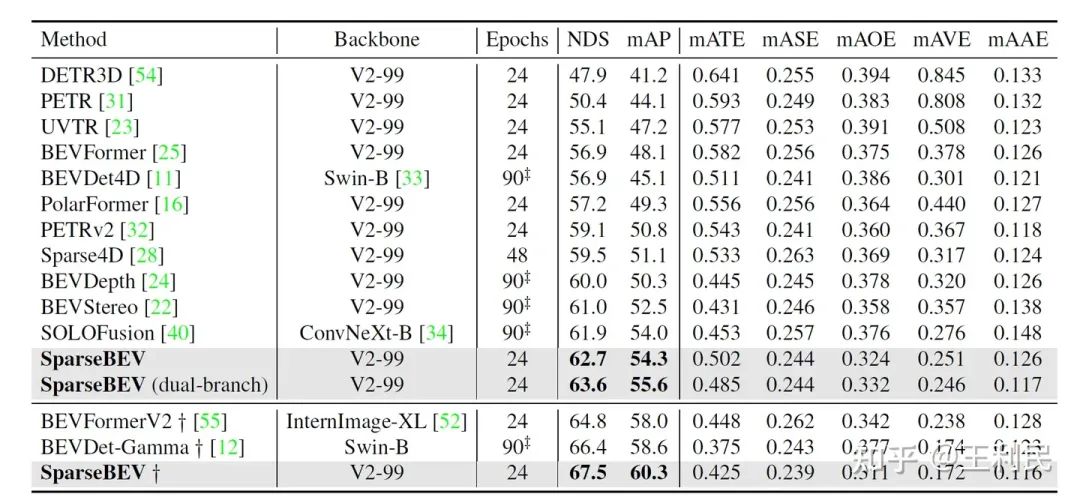
上表为 SparseBEV 与现有方法在测试集上的结果对比,其中 † 表示方法使用了未来帧。在不使用未来帧的情况下,SparseBEV 取得了 62.7 NDS 和 54.3 mAP;其 Dual-branch 版本进一步提升到了 63.6 NDS 和 55.6 mAP。在加入未来帧后,SparseBEV 超越 BEVFormer V2 高达 2.8 mAP 和 2.2 NDS,而我们使用的 V2-99 仅约 70M 参数,参数量远低于 BEVFormer V2 使用的 InternImage-XL(超过 300M 参数)。
4. 局限性
SparseBEV 的弱点还不少:
SparseBEV 非常依赖 ego pose 来实现帧间对齐。在论文的 Table 5 中,如果不使用 ego-based warping,NDS 能掉 10 个点左右,几乎和没加时序一样。
SparseBEV 中使用的时序建模属于堆叠时序,它的耗时和输入帧数成正比。当输入帧数太多的时候(比如 16 帧),会拖慢推理速度。
目前 SparseBEV 采用的训练方式还是传统方案。对于一次训练迭代,DataLoader 会将所有帧全部 load 进来。这对于机器的 CPU 能力有较高的要求,因此我们使用了诸如 TurboJPEG 和 Pillow-SIMD 库来加速 loading 过程。接着,所有的帧全部会经过 backbone,对 GPU 显存也有一定要求。对于 ResNet50 和 8 帧 704x256 的输入来说,2080Ti-11G 还可以塞下;但如果把分辨率、未来帧等等都拉满,就只有 A100-80G 可以跑了。我们开源的代码中使用的 Training 配置均为能跑的最低配置。目前有两种解决方案:
A.将部分视频帧的梯度截断。我们开源的 config 中有个 stop_prev_grad 选项,它会将所有之前帧都以 no_grad 模式推理,只有当前帧会有梯度回传。
B. 另一种解决方案是采用 SOLOFusion、StreamPETR 等方法中使用的 sequence 训练方案,省显存省时间,我们未来可能会尝试。
5. 结论
本文中,我们提出了一种全稀疏的单阶段 3D 目标检测器 SparseBEV。SparseBEV 通过尺度自适应自注意力、自适应时空采样、自适应融合三个核心模块提升了基于稀疏 query 模型的自适应性,取得了和基于稠密 BEV 的方法接近甚至更优的性能。此外我们还提出了一种 Dual-branch 的结构进行更加高效的长时序处理。SparseBEV 在 nuScenes 同时实现了高精度和高速度。我们希望该工作可以对稀疏 3D 检测范式有所启发。
编辑:黄飞
-
主动快门式3D眼镜设计方案2012-12-12 0
-
耐用的破损玻璃检测器2015-05-06 0
-
3D检测系统可检测PCB板针脚高度2016-01-05 0
-
全场应变测量与仿真优化分析系统MatchID-2D/3D2018-07-23 0
-
便宜工业级3D打印机CASET4002018-09-06 0
-
AMEYA360设计方案丨混合 3D 显示仪表板解决方案2018-09-28 0
-
PADS 3D使用出现界面全黑的情况2018-09-29 0
-
3d全息风扇灯条|3D全息风扇方案|3d全息风扇PCBA2019-08-02 0
-
NB-IoT地磁车位检测器技术方案2020-07-09 0
-
基于ToF的3D活体检测算法研究2021-01-06 0
-
3D设计软件中怎么快速进行工程计算?2021-05-06 0
-
浩辰3D的「3D打印」你会用吗?3D打印教程2021-05-27 0
-
嵌入式3D视觉功能相关资料推荐2021-12-23 0
-
基于BEV的视觉3D目标检测器2023-09-16 448
-
CCV 2023 | SparseBEV:高性能、全稀疏的纯视觉3D目标检测器2023-09-19 457
全部0条评论

快来发表一下你的评论吧 !
