

后端太卷?冲测开去了!
描述
大家好,我是小林。
秋招进展中,有的同学投大厂后端没什么面试机会,就会尝试投测试开发岗位。
测试开发岗会伴随开发+测试类的工作,开发主要是开发一些测试工具来提高测试效率,也会和根据业务团队的需求开发一些工具。
测试开发的面试其实跟后端开发差不多,其实被问的问题不会太细节或者太底层,除此后端的内容之外,还会考察一些测试相关的内容。
比如,如何设计测试用例、黑盒测试和白盒测试有什么区别、手动测试和自动测试有什么区别、api 测试工具怎么用等等,甚至也会问,为什么要选择做测试开发。所以这类问题, 同学们在投递的时候,最好提前准备下。
今天分享一位同学大厂测开的秋招面试(面试已过),算法做了 2 题,面试问基础内容比较多,难度确实会比后端减少了很多。
面试记录
1. 项目问题:rabbitmq进行了异步解耦,说说看?
回答:用作消息通知类似的
面试官:那你没必要用消息队列,异步任务就行了,感觉是为了学做的这个需求,感觉你喜欢把简单的东西复杂化(心凉一半)
小林补充
可以说一下为什么要用到mq,比如同样是挂了的情况,消息队列有什么异常处理机制,确保消息不丢失这方面提到,当然也是要看你的业务是否需要确保任务不丢失。
2. SpringBoot自动装配介绍一下。
回答:讲了一下原理,说了实现了一个starter,封装了一些日志类,通用的类
3. MySQL查询缓慢,排查过程?
回答:explain看看有没有触发索引,有慢查询日志的话可以看看日志
4. explain主要关注哪些字段?
回答:覆盖索引 记得有个Condition index,还有一个字段是索引长度的记得(全靠回忆小林coding)
小林补充:
需要重点关注 type 和 extra 字段。

对于执行计划,参数有:
possible_keys 字段表示可能用到的索引;
key 字段表示实际用的索引,如果这一项为 NULL,说明没有使用索引;
key_len 表示索引的长度;
rows 表示扫描的数据行数。
type 表示数据扫描类型,我们需要重点看这个。
type 字段就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为:
All(全表扫描);
index(全索引扫描);
range(索引范围扫描);
ref(非唯一索引扫描);
eq_ref(唯一索引扫描);
const(结果只有一条的主键或唯一索引扫描)。
在这些情况里,all 是最坏的情况,因为采用了全表扫描的方式。index 和 all 差不多,只不过 index 对索引表进行全扫描,这样做的好处是不再需要对数据进行排序,但是开销依然很大。所以,要尽量避免全表扫描和全索引扫描。
range 表示采用了索引范围扫描,一般在 where 子句中使用 < 、>、in、between 等关键词,只检索给定范围的行,属于范围查找。从这一级别开始,索引的作用会越来越明显,因此我们需要尽量让 SQL 查询可以使用到 range 这一级别及以上的 type 访问方式。
ref 类型表示采用了非唯一索引,或者是唯一索引的非唯一性前缀,返回数据返回可能是多条。因为虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。
eq_ref 类型是使用主键或唯一索引时产生的访问方式,通常使用在多表联查中。比如,对两张表进行联查,关联条件是两张表的 user_id 相等,且 user_id 是唯一索引,那么使用 EXPLAIN 进行执行计划查看的时候,type 就会显示 eq_ref。
const 类型表示使用了主键或者唯一索引与常量值进行比较,比如 select name from product where id=1。
需要说明的是 const 类型和 eq_ref 都使用了主键或唯一索引,不过这两个类型有所区别,const 是与常量进行比较,查询效率会更快,而 eq_ref 通常用于多表联查中。
除了关注 type,我们也要关注 extra 显示的结果。
这里说几个重要的参考指标:
Using filesort :当查询语句中包含 group by 操作,而且无法利用索引完成排序操作的时候, 这时不得不选择相应的排序算法进行,甚至可能会通过文件排序,效率是很低的,所以要避免这种问题的出现。
Using temporary:使了用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表,常见于排序 order by 和分组查询 group by。效率低,要避免这种问题的出现。
Using index:所需数据只需在索引即可全部获得,不须要再到表中取数据,也就是使用了覆盖索引,避免了回表操作,效率不错。
5. 索引失效有哪些场景
回答:%x,函数,Or,表本来就不大。
小林补充:
当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx%这两种方式都会造成索引失效;
当我们在查询条件中对索引列使用函数,就会导致索引失效。
当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。
MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而条件语句中的输入参数是数字的话,那么索引列会发生隐式类型转换,由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
6. 常见索引哪几类?
回答:非聚簇和聚簇,主键索引(淦,记得小林coding里有分,一时想不起来了)
小林补充
按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
按「字段个数」分类:单列索引、联合索引。
7. 你知道什么是唯一索引吗?
回答:Unique
追问:一般干什么用的?只知道是unique不知道是干啥用的是吧?
小林补充
唯一索引主要是为了确保字段的唯一性,通常会对身份证号,学生号之类具有唯一性约束的字段建立唯一索引。唯一索引的更新性能没有普通索引高,因为没办法利用 changebuffer 的优化。
8. TCP和UDP区别
回答:
TCP面向连接,UDP不在话消息是否到达,QUIC基于UDP实现了类似TCP的可靠传输
TCP建立连接要三次握手 四次挥手断开连接,拥塞控制,阻塞窗口
小林补充
连接方式:TCP是一种面向连接的协议,通信前需要建立连接。UDP是无连接的,发送数据前无需建立连接。
可靠性:TCP提供了数据包的顺序、错误检查和重发机制,因此是一种可靠的协议。UDP则不保证数据包的顺序或是否会到达,所以是不可靠的。
速度:由于TCP的这些额外特性,它通常比UDP慢。UDP由于没有错误检查和重发机制,因此速度更快。
头部大小:TCP的头部大小为20-60字节,而UDP的头部大小为8字节。
9. TCP上层协议有哪些?
回答:Http https 不记得了
小林补充
FTP(文件传输协议)、SMTP(简单邮件传输协议)
10. DNS是吗?
回答:是吧
面试官:这个可能不太对 你下去再看看吧(寄)
小林补充
DNS(域名系统)通常基于UDP(用户数据报协议)而非TCP来运作,因为UDP对于DNS的快速请求-应答通信模式更为高效。然而,在某些情况下,如当DNS响应的大小超过UDP的最大包大小(512字节)或进行区域传输时,DNS会使用TCP。所以,虽然DNS主要使用UDP,但在特定情况下也会使用TCP。
11. 进程和线程的区别?
回答:
cpu调度,内存调度
进程独立,线程基于进程
切换损耗
12. 死锁是怎么发生的?
回答:四个必要条件和银行家算法(上课学过)
小林补充
死锁问题的产生是由两个或者以上线程并行执行的时候,争夺资源而互相等待造成的。
死锁只有同时满足互斥、持有并等待、不可剥夺、环路等待这四个条件的时候才会发生。
互斥条件
互斥条件是指多个线程不能同时使用同一个资源。
比如下图,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占用的资源,那线程 B 只能等待,直到线程 A 释放了资源。
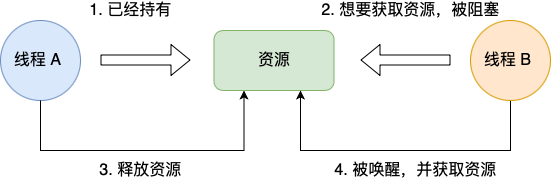
img
持有并等待条件
持有并等待条件是指,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。
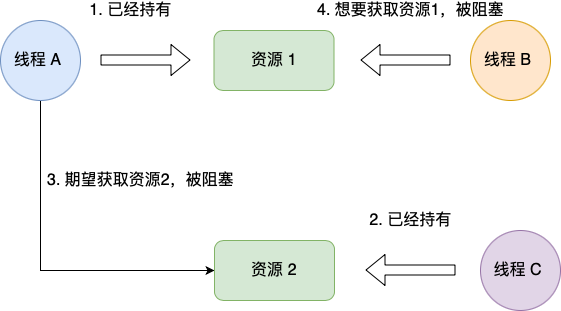
img
不可剥夺条件
不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。
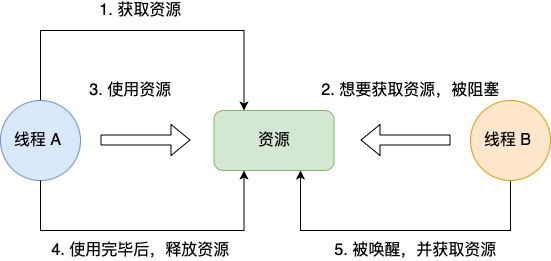
img
环路等待条件
环路等待条件指的是,在死锁发生的时候,两个线程获取资源的顺序构成了环形链。
比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环形图。
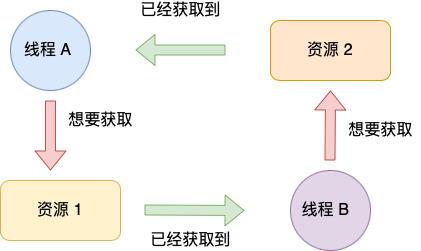
img
所以要避免死锁问题,就是要破坏其中一个条件即可,最常用的方法就是使用资源有序分配法来破坏环路等待条件。
13. os的内存管理有分页和分段了解吗?
回答:
分段是逻辑方面的,比如函数会放在一个段,提高复用性
还能多想一点吗 虚拟内存是分页还是分段
分页,记得一个页面置换
14. 页面置换有哪些算法?
回答:纯靠上课印象了 (LRU、LFU、时钟)
小林补充
页面置换算法的功能是,当出现缺页异常,需调入新页面而内存已满时,选择被置换的物理页面,也就是说选择一个物理页面换出到磁盘,然后把需要访问的页面换入到物理页。
那其算法目标则是,尽可能减少页面的换入换出的次数,常见的页面置换算法有如下几种:
最佳页面置换算法(OPT)
先进先出置换算法(FIFO)
最近最久未使用的置换算法(LRU)
时钟页面置换算法(Lock)
最不常用置换算法(LFU)
最佳页面置换算法
最佳页面置换算法基本思路是,置换在「未来」最长时间不访问的页面。
所以,该算法实现需要计算内存中每个逻辑页面的「下一次」访问时间,然后比较,选择未来最长时间不访问的页面。
我们举个例子,假设一开始有 3 个空闲的物理页,然后有请求的页面序列,那它的置换过程如下图:
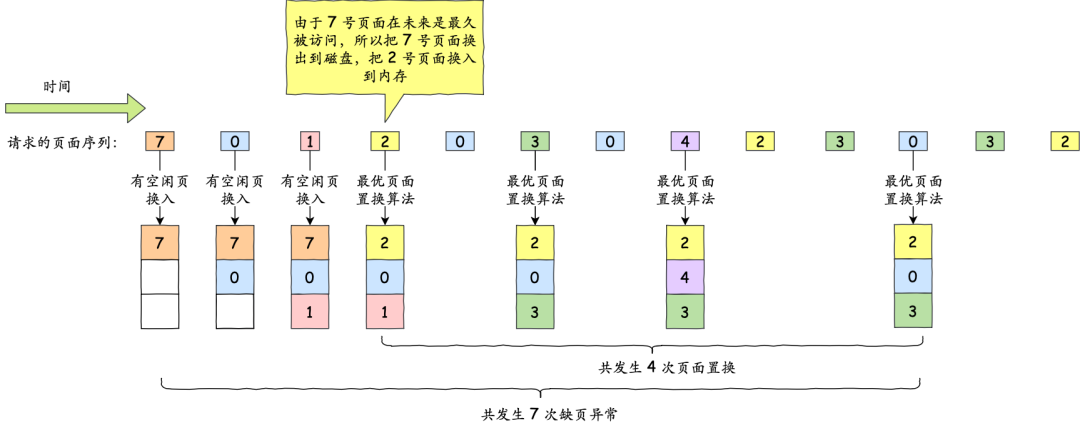
最佳页面置换算法
在这个请求的页面序列中,缺页共发生了 7 次(空闲页换入 3 次 + 最优页面置换 4 次),页面置换共发生了 4 次。
这很理想,但是实际系统中无法实现,因为程序访问页面时是动态的,我们是无法预知每个页面在「下一次」访问前的等待时间。
所以,最佳页面置换算法作用是为了衡量你的算法的效率,你的算法效率越接近该算法的效率,那么说明你的算法是高效的。
先进先出置换算法
既然我们无法预知页面在下一次访问前所需的等待时间,那我们可以选择在内存驻留时间很长的页面进行中置换,这个就是「先进先出置换」算法的思想。
还是以前面的请求的页面序列作为例子,假设使用先进先出置换算法,则过程如下图:
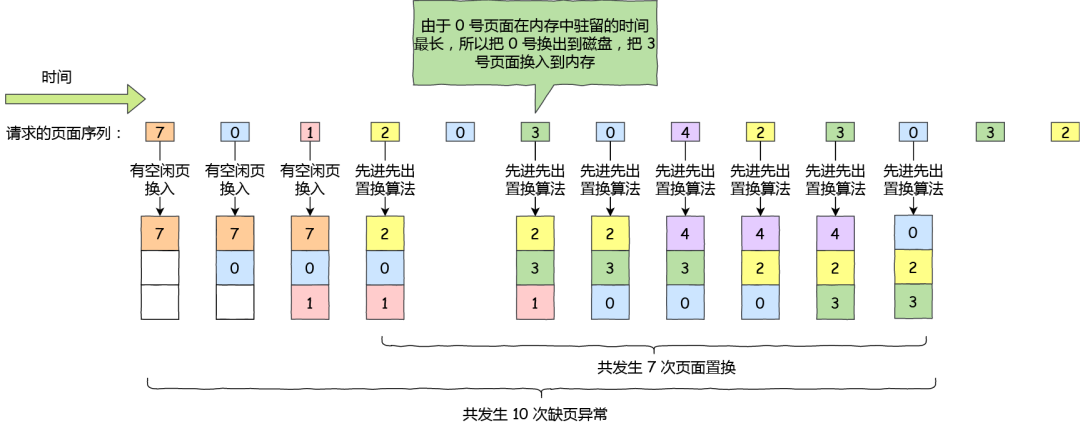
先进先出置换算法
在这个请求的页面序列中,缺页共发生了 10 次,页面置换共发生了 7 次,跟最佳页面置换算法比较起来,性能明显差了很多。
最近最久未使用的置换算法
最近最久未使用(LRU)的置换算法的基本思路是,发生缺页时,选择最长时间没有被访问的页面进行置换,也就是说,该算法假设已经很久没有使用的页面很有可能在未来较长的一段时间内仍然不会被使用。
这种算法近似最优置换算法,最优置换算法是通过「未来」的使用情况来推测要淘汰的页面,而 LRU 则是通过「历史」的使用情况来推测要淘汰的页面。
还是以前面的请求的页面序列作为例子,假设使用最近最久未使用的置换算法,则过程如下图:
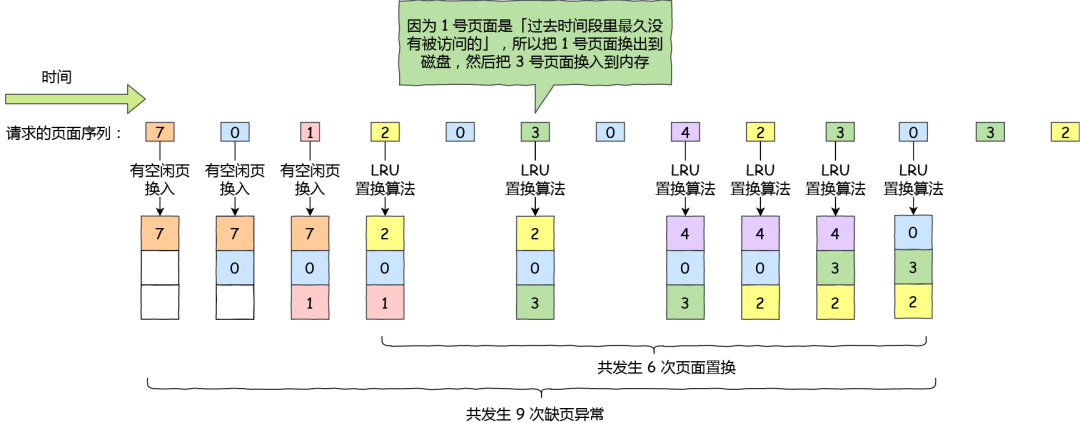
最近最久未使用的置换算法
在这个请求的页面序列中,缺页共发生了 9 次,页面置换共发生了 6 次,跟先进先出置换算法比较起来,性能提高了一些。
虽然 LRU 在理论上是可以实现的,但代价很高。为了完全实现 LRU,需要在内存中维护一个所有页面的链表,最近最多使用的页面在表头,最近最少使用的页面在表尾。
困难的是,在每次访问内存时都必须要更新「整个链表」。在链表中找到一个页面,删除它,然后把它移动到表头是一个非常费时的操作。
所以,LRU 虽然看上去不错,但是由于开销比较大,实际应用中比较少使用。
时钟页面置换算法
那有没有一种即能优化置换的次数,也能方便实现的算法呢?
时钟页面置换算法就可以两者兼得,它跟 LRU 近似,又是对 FIFO 的一种改进。
该算法的思路是,把所有的页面都保存在一个类似钟面的「环形链表」中,一个表针指向最老的页面。
当发生缺页中断时,算法首先检查表针指向的页面:
如果它的访问位位是 0 就淘汰该页面,并把新的页面插入这个位置,然后把表针前移一个位置;
如果访问位是 1 就清除访问位,并把表针前移一个位置,重复这个过程直到找到了一个访问位为 0 的页面为止;
我画了一副时钟页面置换算法的工作流程图,你可以在下方看到:
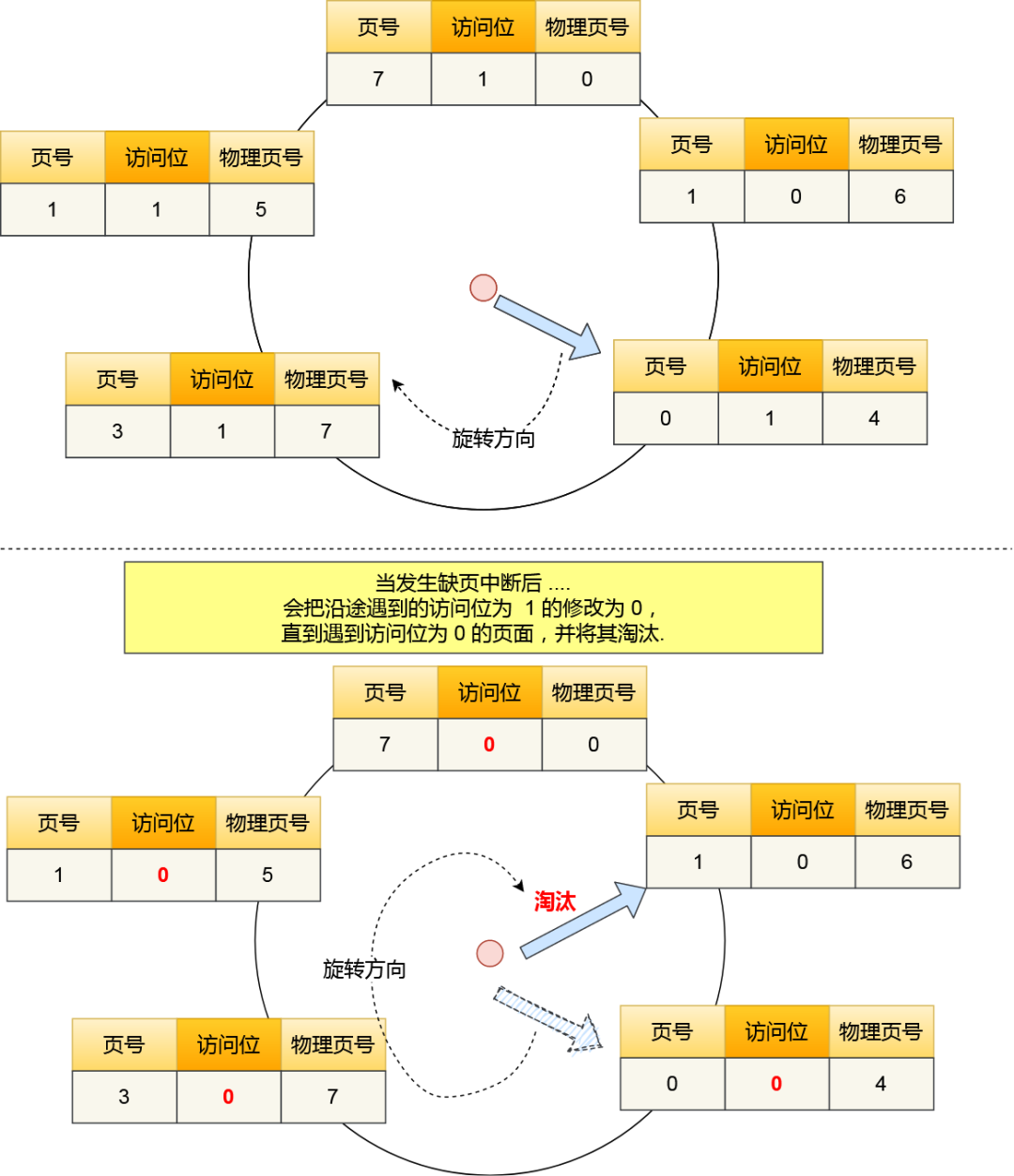
时钟页面置换算法
了解了这个算法的工作方式,就明白为什么它被称为时钟(Clock)算法了。
最不常用算法
最不常用(LFU)算法,这名字听起来很调皮,但是它的意思不是指这个算法不常用,而是当发生缺页中断时,选择「访问次数」最少的那个页面,并将其淘汰。
它的实现方式是,对每个页面设置一个「访问计数器」,每当一个页面被访问时,该页面的访问计数器就累加 1。在发生缺页中断时,淘汰计数器值最小的那个页面。
看起来很简单,每个页面加一个计数器就可以实现了,但是在操作系统中实现的时候,我们需要考虑效率和硬件成本的。
要增加一个计数器来实现,这个硬件成本是比较高的,另外如果要对这个计数器查找哪个页面访问次数最小,查找链表本身,如果链表长度很大,是非常耗时的,效率不高。
但还有个问题,LFU 算法只考虑了频率问题,没考虑时间的问题,比如有些页面在过去时间里访问的频率很高,但是现在已经没有访问了,而当前频繁访问的页面由于没有这些页面访问的次数高,在发生缺页中断时,就会可能会误伤当前刚开始频繁访问,但访问次数还不高的页面。
那这个问题的解决的办法还是有的,可以定期减少访问的次数,比如当发生时间中断时,把过去时间访问的页面的访问次数除以 2,也就说,随着时间的流失,以前的高访问次数的页面会慢慢减少,相当于加大了被置换的概率。
算法(35min+):
数组中和最接近目标值的三个数
数组最大的组合数{3,32,9,912} 组合成9912332
反问:
评价以及哪些方面需要学习?
测开岗干啥?
-
nodejs 后端技术介绍2023-05-05 831
-
数字IC后端设计介绍,写给哪些想转IC后端的人!2020-12-29 0
-
什么是后端?2021-06-23 0
-
基于层次法实现EOS芯片的后端设计2009-08-07 448
-
后端系统,后端系统是什么意思2010-04-06 3644
-
后端时序修正基本思路2011-10-26 2775
-
基于Serverless的前后端一体化框架2020-03-01 765
-
springboot前后端交互流程2023-11-22 1175
-
芯片设计分为哪些步骤?为什么要分前端后端?前端后端是什么意思2023-12-07 2189
-
模拟后端是什么意思2024-03-15 272
全部0条评论

快来发表一下你的评论吧 !
