

人工智能下如何提升主要CPU处理单元速度?
人工智能
描述
芯片企业正在借助不断演进和革命性技术,以在功耗相同或更低的情况下显著提高性能,这标志着从制造驱动设计到半导体架构师驱动设计的根本性转变。
01. 计算任务改变对计算架构的需求
过去大多数芯片只包含一到两项先进技术,主要是为了跟上每隔几年新工艺节点的光刻技术改进,是根据行业路线图进行的,要求在未来能够获得可预测但不显著的收益。随着大型语言模型和传感器数据的爆炸式增长,以及自行设计芯片的系统公司之间的竞争加剧,以及国际竞争在人工智能领域不断激烈,芯片设计的规则正在发生重大变化。
渐进式改进与性能的巨大飞跃相结合,虽然这些改进将计算和分析能力提升到全新水平,但也需要全新的权衡考虑。这些变革的核心在于高度定制的芯片架构,芯片是在最先进的工艺节点开发的。并行处理变得几乎是必然的,加速器用于特定数据类型和操作。在某些情况下,这些微型系统可能不会商业销售,因为它们为数据中心提供了竞争优势。
也可能包括其他商业技术,如处理核心、加速器、减少延迟的内存内或近内存计算技术,以及不同的缓存策略、共同封装的光学器件和更快速的互连。其中许多进展多年来一直处于研究或搁置状态,现在正在全面部署。
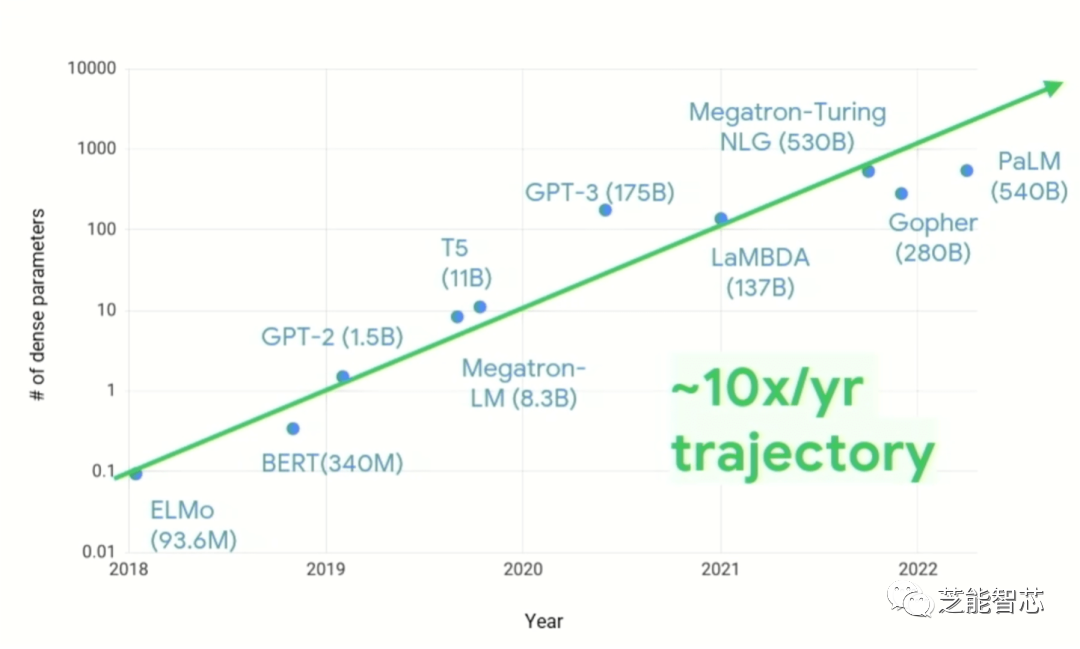
在最近的Hot Chips 2023会议上,谷歌研究院的工程研究员兼机器学习系统副总裁Amin Vahdat指出,现在的芯片可以解决十年前无法想象的问题,机器学习正在承担越来越多的任务。需要改变对系统设计的看法。过去五、六、七年中计算需求的增长令人震惊...虽然在[算法]稀疏性方面出现了许多创新,10倍每个模型的参数数量持续一年。计算成本随着参数数量的增加而超线性增长。必须构建一种不同的计算基础设施来应对这一挑战。值得注意的是,如果尝试在通用计算上做到这一点,就不会取得今天的成就,在过去50或60年间开发的传统计算智慧已被抛弃。”
旧问题并没有解决,功耗和散热一直是设计团队头疼的问题,并且随着处理速度和数量的增加,问题变得更加难以解决。在大约3GHz之后,由于热密度更高且芯片无法散发热量,仅仅提高时钟频率就不再是一个简单的选择。虽然稀疏数据模型和软硬件协同设计提高了在各种处理元件上运行的软件效率,以及每个计算周期处理更多数据的能力,但不再需要转动一个旋钮来提高每瓦性能。随着数据的增加和架构创新的转变,这些经济学发生了巨大的变化,这一点在今年的Hot Chips会议上显而易见。
解决的办法包括内存中/近内存处理,以及更接近数据源的处理。移动大量数据需要大量的系统资源——带宽、电力和时间——这对计算有直接的经济影响。一般来说,收集和处理的大部分数据都是无用的。汽车或安全系统中的视频输入中的相关数据可能仅持续一两秒,而可能需要数小时的数据进行整理。对靠近源头的数据进行预处理,并使用人工智能来识别感兴趣的数据,意味着只需发送一小部分数据进行进一步处理和存储。
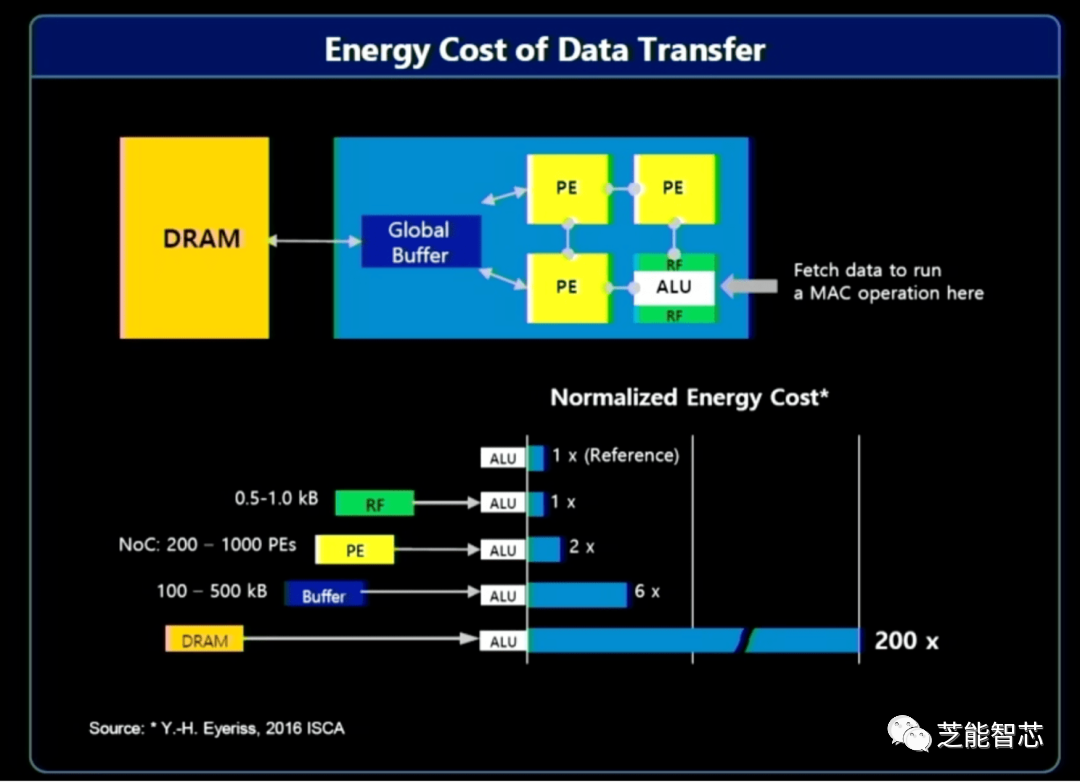
三星首席工程师Jin Hyun Kim表示:“大部分能源消耗来自移动数据。” 他指出了三种提高效率和提升绩效的解决方案:使用HBM进行内存处理,实现极高的带宽和功耗;使用LPDDR对需要高容量的低功耗设备进行内存处理;使用CXL进行近内存处理,以适中的成本实现极高的容量。
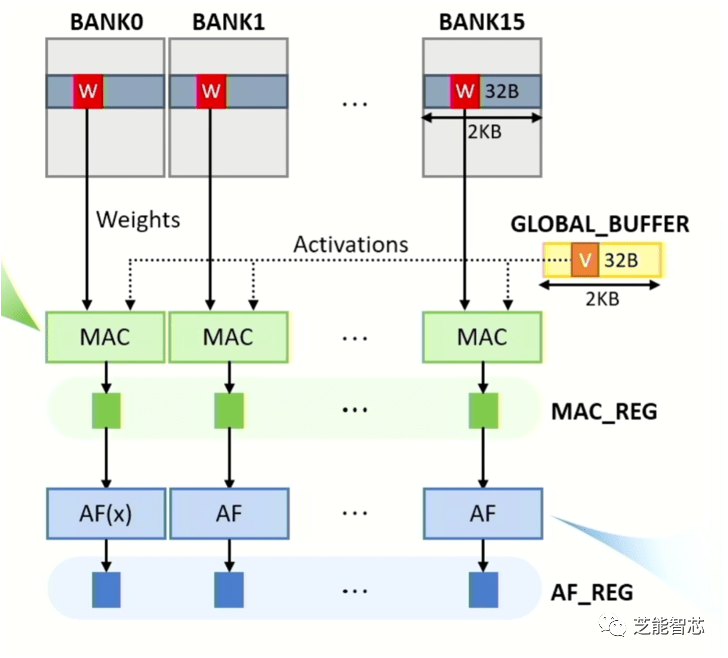
内存处理已经酝酿了很多年,直到最近才出现太大进展。大型语言模型已经极大地推动了这项技术的发展。大部分数据处理中的计算都是稀疏的,这意味着许多数值是零。利用这一点需要另一种类型的处理单元,这种处理单元要比通用计算单元快,也要节省能源。没有人会完全放弃通用处理器,在大部分的应用中具有多样性需求的硬件。
内存加速对于 AI/ML 的乘法累加 (MAC) 函数特别有用,因为需要快速处理的数据量呈爆炸式增长。使用生成式预训练 Transformer 3 (GPT-3) 和 GPT4,仅加载数据就需要大量带宽。与此相关的挑战有很多,包括如何有效地做到这一点,同时最大限度地提高性能和吞吐量,如何扩展它以处理大型语言模型中参数数量的快速增加,以及如何建立灵活性以适应未来的变化。
SK hynix America 高级技术经理 Yonkwee Kwon 在 Hot Chips 2023 上的演讲中表示:“一开始的想法是将内存作为加速器,第一个目标是实现高效扩展,拥有高性能也很重要。设计的系统架构易于编程,同时最大限度地减少系统结构开销,但仍然允许软件堆栈实现灵活性。
02. CPU的改进
计算的开销也是一个重要的内容,计算要求大量的能量,随着数据的增加,处理元素的数量将越来越多。要找到这些计算元素,需要大量的互连,而这些互连要么会增加成本,要么会增加功耗,或者两者兼而有之。从计算工作负载的核心到核心移动数据意味着不仅需要互连,还需要一种具有高度可扩展性和能够使用低功耗传输大量数据的技术。这需要更复杂的网络拓扑,需要在整个系统级别进行管理,以确保能够处理大量数据。
03. CPU计算-提高速度
下一个挑战是提高主要CPU处理单元的速度。
一种方法是分支预测,类似于预测下一个操作的方式,就像互联网搜索引擎一样。然而,与任何并行架构一样,关键是确保各种处理单元充分运行,以最大限度地提高性能和效率。
Arm通过其Neoverse V2设计对这一概念进行了改进,将分支预测与获取分离。这导致了通过减少停顿来提高效率,并更快地从错误预测中恢复。Arm的首席CPU架构师Magnus Bruce表示:“动态馈送机制允许内核调节攻击性,并主动防止系统拥塞。这些基本概念使我们能够推动机器的宽度和深度,保持较短的管道以快速恢复错误预测。”
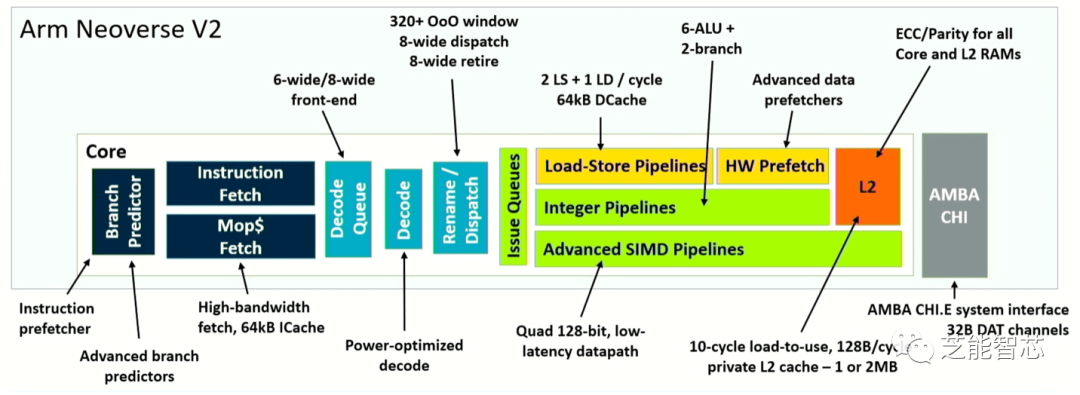
这些改进是通过在多个架构点进行微调而实现的,而不是进行大规模改变。例如,分离分支预测和获取可以将分支目标缓冲区拆分为两个级别,使其能够处理多50%的条目。增加了预测器中存储的历史记录三倍,并将获取队列中的条目数量增加一倍,从而显着提高了实际性能。综合考虑各种改进,Neoverse V2的性能是V1的两倍,具体取决于其在系统中的角色。
AMD的下一代Zen 4核心通过微架构的改进,每周期的指令数增加了约14%。由于工艺扩展,5nm下的频率提高了16%。由于微架构和技术的改进,功耗降低了约60%。物理设计也得到了改进。
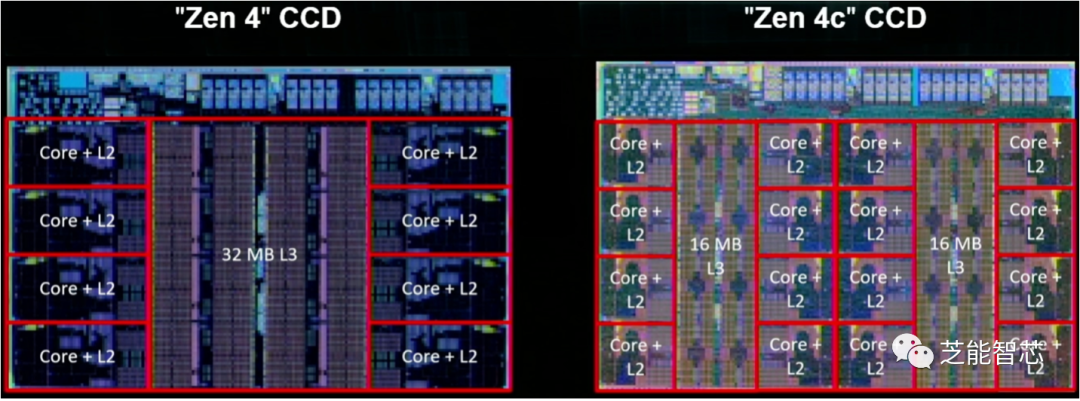
与Arm一样,AMD也致力于改进分支预测和获取。AMD的研究员兼Zen 4首席架构师Kai Troester表示,通过更多的分支、每周期更多的分支预测以及允许更多条目和每个条目更多操作的更大操作缓存,分支预测的准确性得到了提高。此外,Zen 4增加了3D V高速缓存,将每个内核的L3高速缓存提升至高达96 MB,并在256位数据路径上使用两个连续周期提供对512位操作的支持。这一设计扩大了数据管道的规模,并尽可能缩短数据传输距离。
04. 平台系统架构平台系统架构
平台架构方面的主要趋势是领域特定性的不断增加,这对通用处理器的传统开发模式造成了破坏。现在的挑战是如何提供本质上大规模的定制,有两种主要方法:
1)通过添加硬件或可编程逻辑来实现可编程性
2)开发可互换的平台部件。
英特尔引入了一个将小芯片集成到先进封装中的框架,利用其嵌入式多芯片互连桥来连接高速I/O、处理器内核和内存。英特尔的目标是提供足够的定制和性能,以满足客户需求,但交付这些系统的速度比完全定制的架构要快得多,并且结果是可预测的。
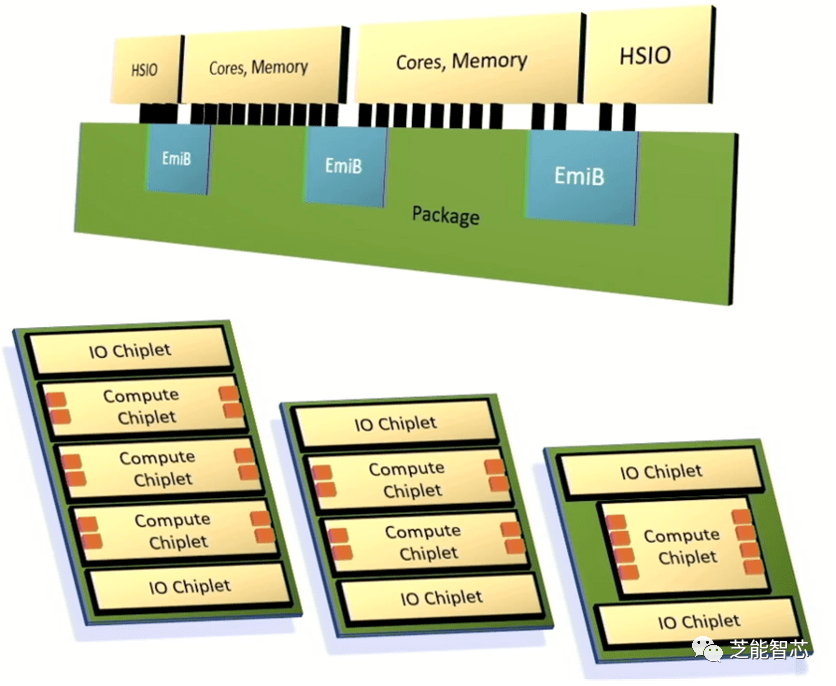
英特尔首席至强架构师Chris Gianos表示。“这将是一个多芯片架构,可以使用这些小芯片构建结构,具有很大的灵活性,只是互操作,为我们提供了专门优化产品核心的维度之一。将创建E核(超高效)的小芯片和P核(高性能)的小芯片。”
英特尔还创建了一个模块化网状结构来将各种组件连接在一起,以及一个支持DDR或MCR内存以及通过CXL连接的内存的通用控制器。
05. 神经处理器和光学互连
这是研究的重要方向,新方法和新技术的清单也是前所未有的。业界正在广泛寻找增加性能、降低功耗的新方法,同时仍然关注面积和成本。对于AI/ML应用程序来说,精度也至关重要。光子学在机架内的服务器之间发挥着作用,但是否将其应用到芯片层面仍不确定。这领域的工作仍在继续,光子学受到了许多公司的关注。
整个行业正在积极寻找提高性能并降低功耗的全新方法,同时关注成本和芯片尺寸。PPAC(性能、功耗、面积、成本)仍然是关注的核心,但不同应用和用例可能会对这些方面的权衡提出不同的要求。IBM的研究员Dharmendra Modha指出:“人工智能的运营支出和资本支出正变得难以维持。”他进一步表示:“架构胜过摩尔定律。”这强调了架构创新在应对当前挑战方面的重要性。
对于AI/ML应用程序来说,精度至关重要。IBM的设计包括支持混合精度的向量矩阵乘法器、具有FP16精度的向量计算单元和激活函数单元。处理是在距离内存几微米的范围内完成的,避免了依赖于数据的条件分支、缓存未命中、停顿和推测执行等问题。
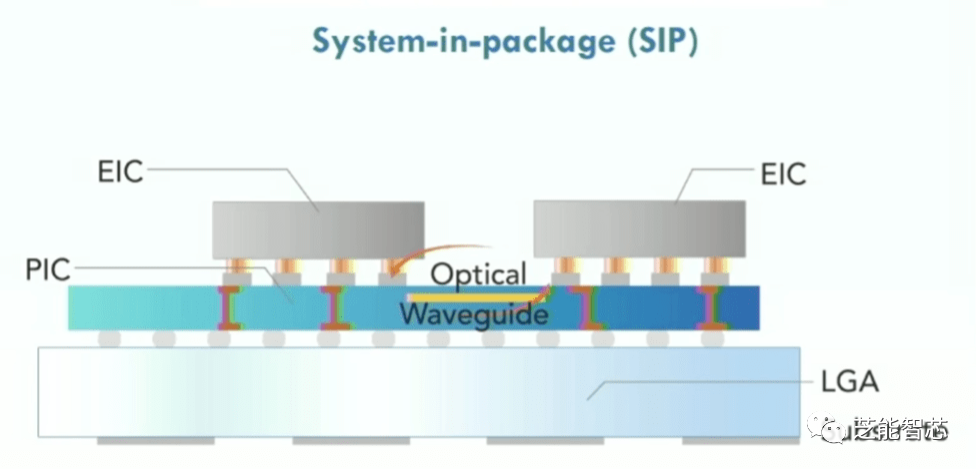
复杂芯片所面临的一个关键挑战不仅在于内存和处理器之间的数据传输,还包括芯片周围的数据传输。片上网络和其他互连结构简化了这一过程。尽管硅光子学在高速网络芯片中已有所应用,光子学在芯片层面的使用仍不确定。然而,光子学在许多公司中引起了广泛关注,特别是在服务器之间的机架内。
Lightelligence工程副总裁Maurice Steinman表示,已经开发了基于光子学的专门加速器,速度比GPU快100倍,同时功耗显著降低。该公司还研发了片上光学网络,使用硅介质层作为连接小芯片的媒介,而不是电子连接。
06. 可持续性和可靠性
随着所有这些变化,出现了两个未解决的问题。
首先是可持续性问题。随着越来越多的数据由芯片处理,能源消耗成为一个日益突出的挑战,而制造这些设备也需要大量能源。尽管在数据中心方面已经取得了一些进展,但能源问题仍然存在。芯片制造商正积极寻找可持续发展的解决方案。
第二个未解决的问题是可靠性。现代芯片设计更加复杂,因此确保结果的准确性和一致性变得更加困难。这一挑战涉及到数据的分区、处理、重新聚合和分析,尤其是当设备老化程度不同并以意想不到的方式交互时。可靠性问题需要深入研究和解决。
有关人工智能训练和CO2排放的数据可能具有误导性。正确的数据分析对于理解问题的严重性至关重要。与此同时,模型从单一模态转向多种模态,这包括图像、文本、声音和视频,因此动力、可持续性和可靠性仍然是至关重要的关注点。
编辑:黄飞
-
人工智能是什么?2015-09-16 0
-
人工智能:革命还是伤害?2016-10-10 0
-
电销机器人成为2018人工智能最热产业之一2018-05-21 0
-
人工智能的影响超乎你想象2018-06-22 0
-
解读人工智能的未来2018-11-14 0
-
人工智能:超越炒作2019-05-29 0
-
异构计算在人工智能什么作用?2019-08-07 0
-
什么是基于云计算的人工智能服务?2019-09-11 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
物联网人工智能是什么?2021-09-09 0
-
人工智能汽车标定方案2021-09-09 0
-
嵌入式与人工智能关系是什么2021-10-27 0
-
什么叫嵌入式人工智能2021-10-28 0
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
全部0条评论

快来发表一下你的评论吧 !
