

Armv9 Cortex-A720的L1 System memory简析
电子说
描述
思考
- L1 System memory 和 L1 Cache 是什么关系?
- L1 指令 cache 禁用时,指令 cache 就真的不会缓存了吗?此时还会出现缓存不一致的情况吗?
- L1 data cache 禁用时,L1 data cache 就真的不会缓存了吗?此时还会出现缓存不一致的情况吗?
- 在下电的时候,cache 有什么自动的行为?
- 有没有 invalidate the entire data cache 的操作?那操作系统中的 invalidate_all_cache 是如何实现的?
- 什么是 Branch Target Buffer (BTB)?
- 什么是 Write streaming mode?软件怎样可以影响到 Write streaming mode 的行为?
- 有关 cache 的 refill,如果 L1 MISS,那么 L1 会发生 refill 吗
- Armv9 中的原子指令,和 cache 有啥关系?
- Exclusive 机制和 cache 有啥关系?
- 数据预取的作用是什么?数据预取有哪些指令?
- 执行 memset() 函数清空一大块内存的时候,这些地址数据都会进 cache 吗?
本节课我们将讲述 Armv9 Cortex-A720 的 L1 System memory.
7 L1 instruction memory system
Cortex-A720 的 L1 指令内存系统用于提取指令并预测分支。它包括 L1 指令缓存、L1 指令 Translation Lookaside Buffer(TLB)以及分支预测单元。L1 指令内存系统向解码器提供指令流。为了提高整体性能并降低功耗,L1 指令内存系统使用动态分支预测和指令缓存。
下图显示了 L1 指令内存系统的特性。

L1 指令 TLB 也位于 L1 instruction memory system 中,它是内存管理单元(MMU)的一部分。
7.1 L1 instruction cache behavior
在 reset 时,除非 core 电源模式初始化为 “Debug Recovery”,否则 L1 指令缓存将自动失效。在 Debug Recovery 模式下,L1 指令缓存不起作用。
L1 instruction cache 的禁用
禁用 L1 instruction cache 对 L1 指令缓存的操作没有影响。即使在禁用状态下,指令仍可以缓存在 L1 指令缓存中并从中提取。软件必须考虑 Non-cacheable accesses 以确保正确的行为。
如果禁用了 L1 instruction cache,那么由指令提取引起的所有内存访问都将使用 Non-cacheable accesses。这意味着指令提取可能与同一核心或其他核心中的缓存不一致。软件必须考虑这一点,执行适当的缓存维护操作。
L1 instruction 维护
缓存维护操作可以在任何时候发生,不管 L1 的状态是禁用还是启用。
7.2 L1 指令缓存的推测性内存访问
指令提取是推测性的,流水线中可能存在多个未完成的分支。
代码流中的分支指令或异常可以导致流水线刷新,丢弃当前已提取的指令。
在指令提取时,具有 device memory 被视为 non-cacheable normal memory。为了防止指令提取,设备内存页面必须标记为翻译表描述符属性位 "Xecute Never"(XN)。设备和代码地址空间必须在物理内存映射中分离。这种分离防止了在禁用地址转换时对读取敏感设备的推测性提取。
如果启用了 L1 指令缓存并且指令提取在 L1 指令缓存中未命中,那么它们仍然可以在 L1 数据缓存中查找。
然而,无论数据缓存是否启用,查找都不会导致 L1 数据缓存重新填充 (refill)。该行仅 refill allocated 在 L2 缓存中,前提是 L1 指令缓存已启用。
7.3 程序流预测
Cortex-A720 核包含程序流预测硬件,也称为分支预测。分支预测提高了整体性能并增强了功耗效率。
当内存管理单元(MMU)启用当前异常级别时,程序流预测被启用。如果禁用程序流预测,那么所有已执行的分支都会产生与清除流水线相关的动作。如果启用程序流预测,则它会预测是否要执行条件或无条件分支,如下所示:
- 对于条件分支,它预测是否要执行分支以及分支转到的地址,即分支目标地址。
- 对于无条件分支,它仅预测分支目标地址。
程序流预测硬件包含以下功能:
- 存储以前已执行分支的分支目标地址的分支目标缓冲器 Branch Target Buffer (BTB)
- 使用以前的分支历史的分支预测(BP)预测器
- 返回堆栈,包括嵌套子例程返回地址
- 静态分支预测器
- 间接分支预测器
预测和非预测指令
- 序流预测硬件预测所有分支指令,包括:
- 条件分支
- 无条件分支
- 返回指令
- 间接分支
以下指令不会被预测:
- 异常返回指令(包括 ERET,ERETAA,ERETAB)
- svc 指令
- hvc 指令
- smc 指令
返回栈
返回栈存储了过程调用指令的返回地址。此地址应与这些指令由 Link 寄存器(X30)写入的值相等。
以下任何指令都会导致压栈:
- BL
- BLR
- BLRAA
- BLRAAZ
- BLRAB
- BLRABZ
以下任何指令都会导致出栈:
- RET
- RETAA
- RETAB
8 L1 data memory system
Cortex-A720 的 L1 数据内存系统执行加载和存储指令。它处理内存一致性请求以及特定指令,如原子操作、缓存维护操作和内存标记指令。L1 数据内存系统包括 L1 数据缓存和 L1 数据 Translation Lookaside Buffer(TLB)。
下表显示了 L1 数据内存系统的特性。
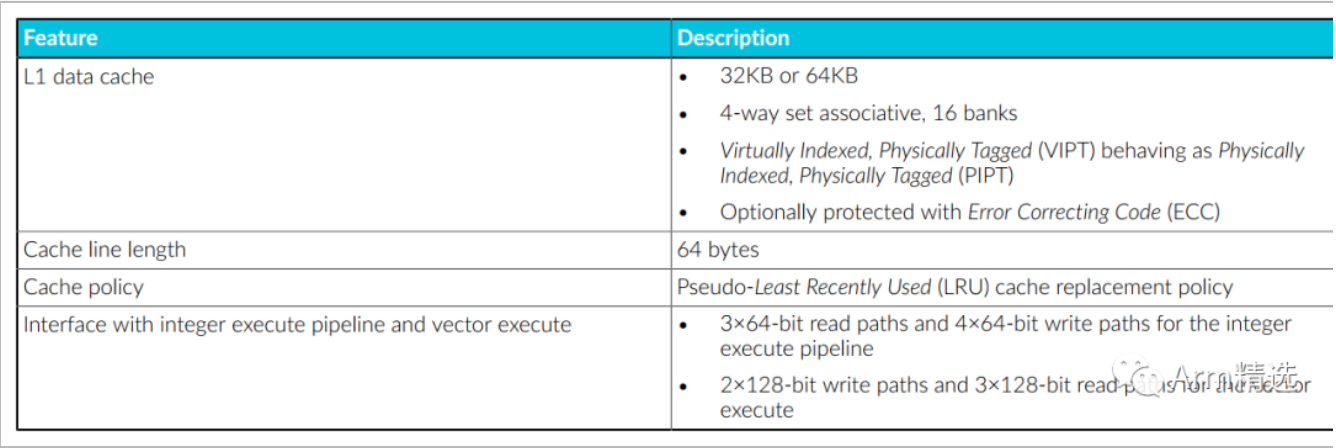
L1 数据 TLB 也位于 L1 数据内存系统中,它是内存管理单元(MMU)的一部分。
8.1 L1 数据缓存行为
除非将核心电源模式初始化为 Debug 恢复模式,否则 L1 数据缓存将在重置时自动失效。在 Debug 恢复模式下,不能保证缓存是否正常运行,因此不应启用。
没有使整个 data cache 失效的操作 (invalidate the entire data cache)。如果软件需要这个功能,那么必须通过循环执行的单独失效操作(通过 set/way 指令)来构建它。DC CISW 指令执行目标 set/way 的清除和失效操作。
禁用 data cache 行为
如果禁用数据缓存行为,则:
- 由于加载指令而导致的 L2 或 L3 缓存不会分配新的行。
- 对可缓存内存的所有加载和存储指令都视为 Non-cacheable。
- 数据缓存维护操作继续正常执行。
L1 数据缓存和 L2 缓存不能独立禁用。当一个核心禁用 L1 数据缓存时,由该核心发出的可缓存内存访问将不再在 L1 或 L2 缓存中缓存。在多个 core 之间 cache 的维护操作,使用 Modified Exclusive Shared Invalid (MESI) 协议
缓存索引的确定方式意味着物理地址(PA)和组编号之间没有直接关系。不能使用假设 PA 和组编号之间存在关系的有针对性的操作。要刷新整个缓存,必须根据缓存的 CCSIDR_EL1 描述的组和方式数量执行组和方式维护操作。
8.2 Write streaming mode
Cortex-A720 核心支持 Write streaming mode,有时也称为读分配模式,对于 L1 和 L2 缓存都支持。
在读不命中或写不命中时,会向 L1 或 L2 缓存分配缓存行。然而,写入大块数据可能会使缓存中充满不必要的数据。这不仅会浪费电力,也会降低性能,因为整个线路会被后续写入覆盖(例如使用 memset() 或 memcpy())。在某些情况下,不需要在写入时分配缓存行。例如,当执行 C 标准库的 memset() 函数来将大块内存清零为已知值时。
为了防止不必要的缓存行分配,内存系统会检测 core 何时写入了一系列完整的缓存行。如果在可配置数量的连续线路填充上检测到这种情况,那么它会切换到写入流模式。
在写入流模式下,加载操作行为与正常情况相同,仍然可能引起线路填充。
写入仍然在缓存中查找,但如果未命中,则会写入 L2 或 L3 缓存,而不会启动线路填充 L1。
在内存系统切换到写入流模式之前,CHI 主控器或 AXI 主控器接口可能会观察到超过指定数量的线路填充。
写入流模式保持启用,直到以下情况之一发生:
• 检测到一个不是完整缓存行的可缓存写入突发。
• 存在后续加载操作,其目标与未完成的写入流相同。
当 Cortex-A720 核心切换到写入流模式后,内存系统会继续监视总线流量。当它观察到一系列完整的缓存行写入时,会向 L2 或 L3 缓存发出信号,以进入写入流模式。
写入流阈值定义了在存储操作停止引起缓存分配之前,连续写入的缓存行数量。您可以通过写入寄存器 IMP_CPUECTLR_EL1 来配置每个缓存(L1、L2 和 L3)的写入流阈值。
8.3 L1 数据内存系统中的原子指令实现
Cortex-A720 核心支持 Arm v8.1-A 架构中添加的原子指令。对可缓存内存的原子指令可以作为近原子操作或远原子操作执行,默认情况下,Cortex-A720 核心将这些指令作为近原子操作执行。
换句说法,可以根据系统行为对 IMP_CPUECTLR_EL1 进行编程,以便某些原子指令尝试作为原子操作执行。
当作为远原子操作执行时,原子操作传递给 interconnect 执行操作。如果操作在集群内的任何位置 hit,或者如果互连器不支持原子操作,则 L3 内存系统执行原子操作。如果该行不存在,则将其分配到 L3 缓存中。
Cortex-A720 核心支持对 device 或 non-cacheable 的原子操作,但这也依赖于互连器是否支持原子操作。如果在互连器不支持原子操作的情况下执行此类原子操作指令,则会导致 abort。
8.4 内部独占监视器
Cortex-A720 核心包括一个内部独占监视器,具有 2 状态(open 状态和 exclusive 状态)的状态机,用于管理 Load-Exclusive 和 Store-Exclusive 访问以及 Clear-Exclusive(CLREX)指令。
您可以使用这些指令构建信号量,确保不同进程在核心上运行时进行同步,以及确保使用相同的一致内存位置的不同核心之间进行同步。Load-Exclusive 指令标记了一小块内存以进行独占访问。CTR_EL0 定义了标记块的大小为 16 个字,即一个缓存行。
Load-Exclusive 或 Store-Exclusive 指令是以 LDX、LDAX、STX 或 STLX 开头的指令。
8.5 数据预取
数据预取可以通过在需要数据之前获取数据来提高执行性能。
预加载指令
对于不能有效处理数据预取器的情况,Cortex-A720 核心支持 AArch64 预取内存指令 PRFM。
这些指令向内存系统发出信号,指定地址处的内存访问可能会很快发生。当内存访问发生时,内存系统采取措施以减少内存访问的延迟。
PRFM 指令在缓存中执行查找。如果未命中并且内存访问是对可缓存地址的,则开始线路填充。但是,PRFM 指令在开始线路填充时执行结束,并且不会等到线路填充完成。
硬件数据预取器
加载 / 存储单元包括硬件预取器引擎,负责生成针对 L1、L2 和 L3 缓存的预取。具体来说,L1 内存子系统中的预取引擎针对 L1 和 L2 缓存。L2 内存子系统中的预取引擎针对 L2 和 L3 缓存。加载端预取器使用虚拟地址(VA)和程序计数器(PC)。存储端预取器仅使用虚拟地址(VA)。CPUECTLR 寄存器允许对预取器行为的某些方面进行控制。
数据缓存清零
在 Cortex-A720 核心中,Data Cache Zero by Virtual Address(DC ZVA)指令将对齐到 64 字节的内存块(64 字节对齐)设置为零。
-
Armv9引入的MTE已成内存安全的新防线2023-06-01 1400
-
Arm®Cortex-A720核心加密扩展技术参考手册2023-08-02 0
-
一文搞懂Armv9的RME环境2022-07-27 0
-
如何在gem5里支持armv9 Transactional Memory (TME)扩展2022-08-01 0
-
Armv8.1-M PAC和BTI扩展简析2022-08-05 0
-
Armv9 system register class空间编码简析2023-03-17 0
-
ARMv8 architecture里的Memory aborts简析2023-03-21 0
-
Arm®Cortex-A720 Core技术参考手册2023-08-02 0
-
Cortex-A9处理器技术参考手册2023-08-02 0
-
Cortex-A9技术参考手册2023-08-17 0
-
ARM Cortex-A77软件优化指南2023-08-24 0
-
Arm Cortex®-A77核心软件优化指南2023-08-29 0
-
Arm下一代指令架构“Armv9”已经问世2019-11-13 43928
-
ARMv9架构能否解决中国“缺芯”之急?2021-05-02 2259
-
Arm微架构之Armv9时代2023-02-06 7526
全部0条评论

快来发表一下你的评论吧 !
