

Hugging Face LLM部署大语言模型到亚马逊云科技Amazon SageMaker推理示例
描述
本篇文章主要介绍如何使用新的Hugging Face LLM推理容器将开源LLMs,比如BLOOM大型语言模型部署到亚马逊云科技Amazon SageMaker进行推理的示例。我们将部署12B Open Assistant Model,这是一款由开放助手计划训练的开源Chat LLM。
这个示例包括:
设置开发环境
获取全新Hugging Face LLM DLC
将开放助手12B部署到亚马逊云科技Amazon SageMaker
进行推理并与我们的模型聊天
清理环境
什么是Hugging Face LLM Inference DLC?
Hugging Face LLM DLC是一款全新的专用推理容器,可在安全的托管环境中轻松部署LLM。DLC由文本生成推理(TGI)提供支持,这是一种用于部署和服务大型语言模型(LLM)的开源、专门构建的解决方案。TGI使用张量并行和动态批处理为最受欢迎的开源LLM(包括StarCoder、BLOOM、GPT-Neox、Llama和T5)实现高性能文本生成。文本生成推理已被IBM、Grammarly等客户使用,Open-Assistant计划对所有支持的模型架构进行了优化,包括:
张量并行性和自定义cuda内核
在最受欢迎的架构上使用flash-attention优化了用于推理的变形器代码
使用bitsandbytes进行量化
连续批处理传入的请求以增加总吞吐量
使用safetensors加速重量加载(启动时间)
Logits扭曲器(温度缩放、topk、重复惩罚…)
用大型语言模型的水印添加水印
停止序列,记录概率
使用服务器发送事件(SSE)进行Token流式传输
官方支持的模型架构目前为:
BLOOM/BLOOMZ
MT0-XXL
Galactica
SantaCoder
gpt-Neox 20B(joi、pythia、lotus、rosey、chip、redPajama、open Assistant)
FLAN-T5-XXL(T5-11B)
Llama(vicuna、alpaca、koala)
Starcoder/santaCoder
Falcon 7B/Falcon 40B
借助亚马逊云科技Amazon SageMaker上推出的全新Hugging Face LLM Inference DLC,亚马逊云科技客户可以从支持高度并发、低延迟LLM体验的相同技术中受益,例如HuggingChat、OpenAssistant和Hugging Face Hub上的LLM模型推理API。
1.设置开发环境
使用SageMaker python SDK将OpenAssistant/pythia-12b-sft-v8-7k-steps部署到亚马逊云科技Amazon SageMaker。需要确保配置一个亚马逊云科技账户并安装SageMaker python SDK。

如果打算在本地环境中使用SageMaker。需要访问具有亚马逊云科技Amazon SageMaker所需权限的IAM角色。可以在这里找到更多关于它的信息。

2.获取全新Hugging Face LLM DLC
与部署常规的HuggingFace模型相比,首先需要检索容器URI并将其提供给HuggingFaceModel模型类,并使用image_uri指向该镜像。要在亚马逊云科技Amazon SageMaker中检索新的HuggingFace LLM DLC,可以使用SageMaker SDK 提供的get_huggingface_llm_image_uri方法。此方法允许根据指定的 “后端”、“会话”、“区域” 和 “版本”检索所需的Hugging Face LLM DLC 的 URI。

要将[Open Assistant Model](openAssistant/Pythia-12b-sft-v8-7K-steps)部署到亚马逊云科技Amazon SageMaker,创建一个HuggingFaceModel模型类并定义终端节点配置,包括hf_model_id、instance_type等。使用g5.4xlarge实例类型,它有1个NVIDIA A10G GPU和64GB的GPU内存。

亚马逊云科技Amazon SageMaker现在创建端点并将模型部署到该端点。这可能需要10-15分钟。
4.进行推理并与模型聊天
部署终端节点后,可以对其进行推理。使用predictor中的predict方法在端点上进行推理。可以用不同的参数进行推断来影响生成。参数可以设置在parameter中设置。
温度:控制模型中的随机性。较低的值将使模型更具确定性,而较高的值将使模型更随机。默认值为0。
max_new_tokens:要生成的最大token数量。默认值为20,最大值为512。
repeption_penalty:控制重复的可能性,默认为null。
seed:用于随机生成的种子,默认为null。
stop:用于停止生成的代币列表。生成其中一个令牌后,生成将停止。
top_k:用于top-k筛选时保留的最高概率词汇标记的数量。默认值为null,它禁用top-k过滤。
top_p:用于核采样时保留的参数最高概率词汇标记的累积概率,默认为null。
do_sample:是否使用采样;否则使用贪婪的解码。默认值为false。
best_of:生成best_of序列如果是最高标记logpros则返回序列,默认为null。
details:是否返回有关世代的详细信息。默认值为false。
return_full_text:是返回全文还是只返回生成的部分。默认值为false。
truncate:是否将输入截断到模型的最大长度。默认值为true。
typical_p:代币的典型概率。默认值null。
水印:生成时使用的水印。默认值为false。
可以在swagger文档中找到TGI的开放api规范。
openAssistant/Pythia-12b-sft-v8-7K-steps是一种对话式聊天模型,这意味着我们可以使用以下提示与它聊天:

先试一试,问一下夏天可以做的一些很酷的想法:

现在,使用不同的参数进行推理,以影响生成。参数可以通过输入的parameters属性定义。这可以用来让模型在“机器人”回合后停止生成。

现在构建一个快速gradio应用程序来和它聊天。

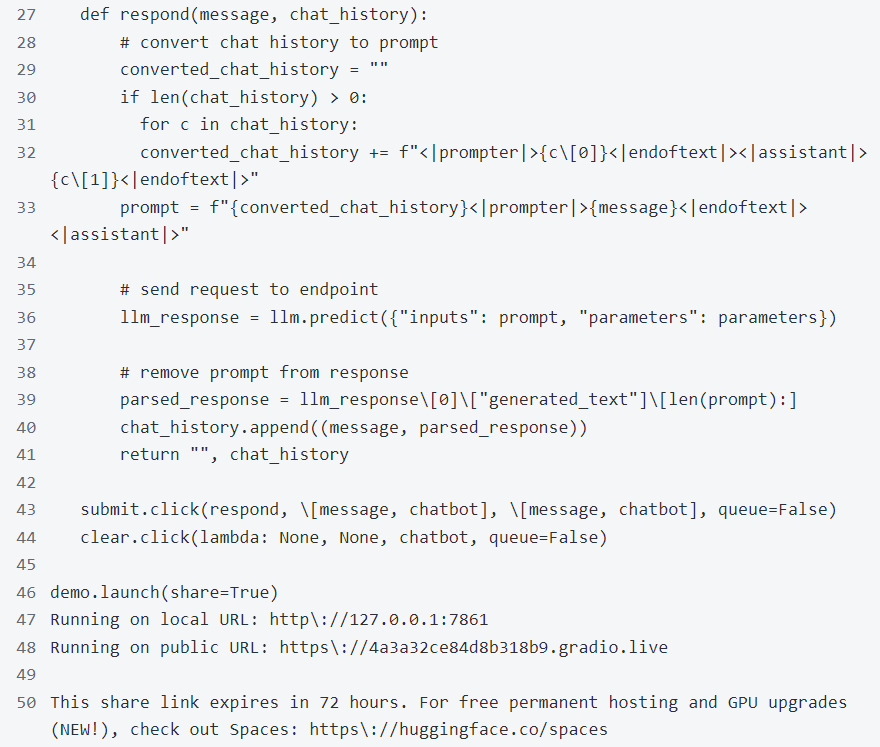
程序运行成功后,显示如下聊天窗口:
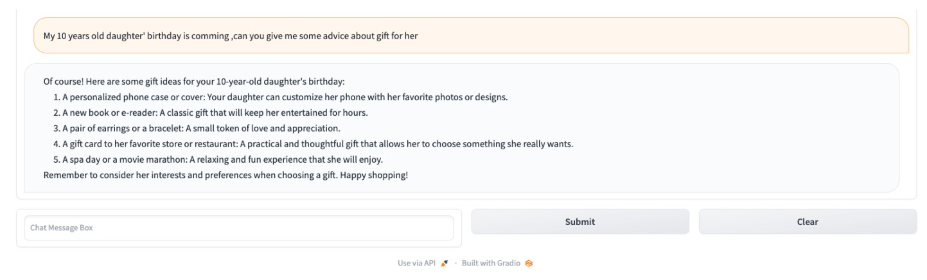
现在已经成功地将Open Assistant模型部署到亚马逊云科技Amazon SageMaker并对其进行了推理。此外,还构建了一个快速的gradio应用程序,可以与模型聊天。
现在,可以使用亚马逊云科技Amazon SageMaker上全新Hugging Face LLM DLC构建世代人工智能应用程序的时候了。
5.清理环境
删除模型和端点。

6.总结
从上面的部署过程,可以看到整个部署大语言模型的过程非常简单,这个主要得益于SageMaker Hugging Face LLM DLC的支持,还可以通过将Amazon SageMaker部署的端点与应用集成,满足实际的业务需求。
审核编辑 黄宇
-
机智云在Amazon Alexa平台发布Smarthome和Custom Skill,实现亚马逊Echo直接控制Gokit2017-03-31 0
-
通过Cortex来非常方便的部署PyTorch模型2022-11-01 0
-
中科创达成为Amazon SageMaker服务就绪计划首批认证合作伙伴2022-12-06 1038
-
使用AWS Graviton降低Amazon SageMaker推理成本2023-05-28 487
-
大型语言模型(LLM)的自定义训练:包含代码示例的详细指南2023-06-12 1969
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 1070
-
Hugging Face更改文本推理软件许可证,不再“开源”2023-07-31 424
-
NVIDIA 与 Hugging Face 将连接数百万开发者与生成式 AI 超级计算2023-08-09 730
-
mlc-llm对大模型推理的流程及优化方案2023-09-26 473
-
Hugging Face被限制访问2023-10-22 1231
-
怎样使用Accelerate库在多GPU上进行LLM推理呢?2023-12-01 682
-
亚马逊云科技推出五项Amazon SageMaker新功能2023-12-06 506
-
ServiceNow、Hugging Face 和 NVIDIA 发布全新开放获取 LLM,助力开发者运用生成式 AI 构建企业应用2024-02-29 166
-
Mistral Large模型现已在Amazon Bedrock上正式可用2024-04-08 290
全部0条评论

快来发表一下你的评论吧 !
