

一种利用几何信息的自监督单目深度估计框架
人工智能
描述
作者:lovelypanda
1. 笔者总结
本文方法是一种自监督的单目深度估计框架,名为GasMono,专门设计用于室内场景。本方法通过应用多视图几何的方式解决了室内场景中帧间大旋转和低纹理导致自监督深度估计困难的挑战。GasMono首先利用多视图几何方法获取粗糙的相机姿态,然后通过旋转和平移/尺度优化来进一步优化这些姿态。为了减轻低纹理的影响,该框架将视觉Transformer与迭代式自蒸馏机制相结合。通过在多个数据集上进行实验,展示了GasMono框架在室内自监督单目深度估计方面的最先进性能。
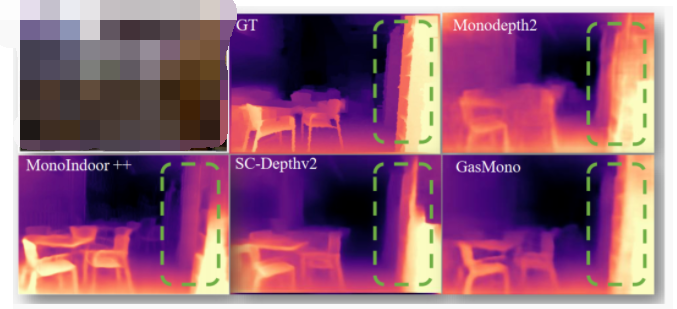
图1. 现有方法和GasMono的比较。我们的框架在薄物体和全局结构上展现出了卓越的精度。
2. 原文摘要
本文针对室内场景中存在的大旋转和低纹理等挑战,提出了一种单目自监督深度估计的框架。我们通过利用多视几何方法从单目序列中估计粗略的相机姿态来缓解大旋转的问题。然而,我们发现由于训练集中不同场景间的尺度不确定性,直接使用几何粗略姿态并不能提升深度估计的性能,这与直觉相悖。为了解决这个问题,我们提出在训练过程中对这些姿态进行旋转和平移/尺度优化。为了应对低纹理的问题,我们将视觉Transformer的全局推理能力与迭代式自蒸馏机制相结合,提供来自网络自身的更准确的深度指导。在NYUv2、ScanNet、7scenes和KITTI数据集上的实验验证了我们框架中每个组件的有效性,我们的方法在室内自监督单目深度估计方面达到了最先进的水平,并展现了优异的泛化能力。
3. GasMono框架
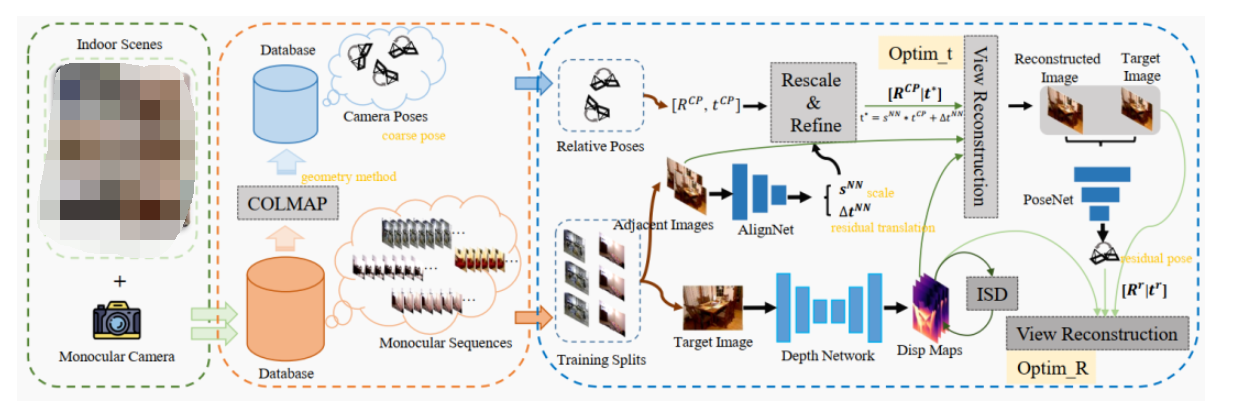
图2. GasMono: 一种基于几何的自监督单目深度估计框架,用于室内场景。注意,在训练过程中没有使用真实标签。通过从多个室内场景中选择的单目图像序列,使用结构从运动(structure-from-motion)软件包COLMAP来估计每个序列上相机的粗略姿态。然后,使用图像序列和粗略姿态来训练深度模型。为了改善粗略的平移,设计了一个AlignNet来估计尺度sNN和残差平移∆t。此外,还设计了一个PoseNet来进一步改善姿态,特别是基于重建和目标图像的粗略旋转。AlignNet和PoseNet只在训练过程中使用。
3.1. 几何辅助姿态估计
自监督单目深度估计框架对于训练视频序列的标准监督协议包括根据估计的深度Dt和相对相机姿态Et→s = Rt→s|tt→s将像素从源图像Is重投影到目标It。这意味着对于目标视图中的像素pt,它在源视图中的坐标ps可以得到
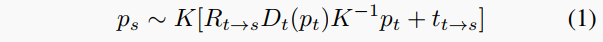
鉴于在图像之间学习准确的相对姿态存在大旋转的挑战,我们提出摆脱通常使用的PoseNet,并用传统姿态估计算法替换它。为此,我们利用COLMAP为训练集中每个单独的室内序列的图像Ii获得相机姿态ECPi = RCPi |tCPi。然后,对于给定的图像对It,Is,分别是目标和源帧,我们可以获得两者之间的相对姿态 Et→s = RCPt→s|tCPt→s = ECPsECPt−1。与两帧姿态估计不同,COLMAP等结构从运动管道可以在整个序列上进行全局推理。我们认为,由于姿态估计是学习单目深度的一个边缘任务,利用整个序列是值得的。
尽管如此,COLMAP估计的姿态,我们将称之为粗略姿态,有一些问题,特别是1)在训练集的不同序列之间存在尺度不一致性和由于单目歧义导致的尺度漂移,2)由于缺乏纹理导致的旋转和平移中的噪声。这使得COLMAP本身无法无缝地替代PoseNet来训练单目深度网络。
3.1.1 平移缩放和精炼
为了解决前一个问题,我们部署一个浅层网络AlignNet来在训练过程中精炼平移并重新缩放它,以克服跨训练集中的不同序列的尺度不一致性。
因此,AlignNet处理目标和源图像,并预测应用于COLMAP估计的平移分量tCPt→s的尺度因子sNN和残差移位ΔtNN。然后,从目标视图到源视图的估计平移tt→s得到为
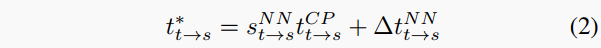
这向量用于方程1,导致仅在学习估计单目深度图时调整训练图像的尺度,使用RCPt→s|t∗t→s。
我们可以将AlignNet视为一个训练优化工具,在训练过程中精炼粗略姿态以使其整体尺度一致。因此,一旦完成训练,它就失去了效用。

图3. 不同编码器对低纹理深度估计的影响。
3.1.2 旋转优化
前面部分仅关注平移优化,尽管粗略姿态估计的旋转也可能不准确和嘈杂,所以也提出了旋转优化。为了进一步展示训练中旋转优化的效果,在图3中,我们分别报告了不准确粗略旋转(顶部样本)和准确粗略旋转(底部样本)的样本。对于两者,我们基于“Optim t”和“Optim R”计算重构损失,并在第3列中给出。对于第一个样本,由于不准确的粗略旋转,仅优化平移(“Optim t”,第1行)无法补偿错误旋转,从而产生高的重投影误差。在精炼旋转之后,基于“Optim R”的重构(第2行)产生了更低的光度误差。相反,在第二个样本中显示准确的粗略姿态,基于“Optim t”的重构已经可以达到合理的重构图像。
3.2 低纹理区域
在自监督训练中,反向传播行为回复到RGB图像的光度渐变变化。那些具有有效光度变化的区域为深度学习提供强大的渐变,而低纹理区域,如墙壁和地板,无法提供有效的监督信号,因为对深度的多个假设导致光度误差接近零,从而使网络陷入局部最小值。因此,对于低纹理区域,深度估计过程主要依赖于网络自身的推理能力。使用某些额外约束可能有助于缓解这个问题,这些约束来自诸如光流或平面法线之类的提示。尽管如此,这需要额外的监督,并且由于低纹理而在光流的情况下也可能遭受同样的问题。因此,我们选择在架构方面解决它,特别是通过Transformer超越CNN的有限感受野。此外,以前的工作证明了标签蒸馏的有效性,以提高深度网络的准确性。
3.2.1 网络架构
我们的框架由三个网络组成,一个用于单目深度估计的Depth Network,一个用于尺度校正和残差平移预测的Alignment Network(AlignNet),以及一个用于残差姿态估计的PoseNet。整体训练架构如图2所示。
考虑到Transformer在特征之间建模长程关系的出色性能,为了增强低纹理区域的全局特征提取,我们引入了一个Transformer编码器MPViT作为深度编码器。编码器中的自注意力机制以一种高效的因素化方式实现:
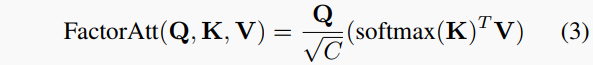
其中C指的是嵌入维度。查询(Q)、键(K)和值(V∈R^{N×C})向量是从视觉标记投影的。此外,对于深度解码器,我们用Convex upsampling 替换了Monodepth2等使用的标准上采样,将4个缩放度图像映射带到全分辨率,在此它们用于下面描述的迭代自我蒸馏操作。
算法1 迭代式自蒸馏系统ISD

3.2.2 迭代自我蒸馏
我们提出一个过拟合驱动的迭代自我蒸馏(ISD)过程,以获得最小像素重投影误差的深度图,为任何特定训练样本提供更准确的标签。ISD的关键步骤在算法1中列出。对于每张训练图像,我们多次迭代此过程(行4)。在第一次迭代中,我们在所有尺度上选择每个像素的最小重建误差及其对应的预测深度(第6-14行)。然后,我们通过最小化当前最佳深度图与每个尺度上的预测之间的深度损失来更新网络(第15-16行)。重复此过程多次迭代。
3.3 训练损失
训练损失的关键项由最小视图重建损失组成。
视图重建损失。对于重构图像I~的误差相对于目标图像I,我们采用结构相似性指数度量(SSIM)和L1差异的组合进行衡量:
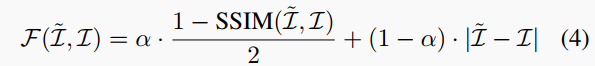
其中α通常设置为0.85 。此外,为了减轻两视图之间的遮挡效应,相对于前向和后向相邻帧进行变形的损失的最小值被计算:
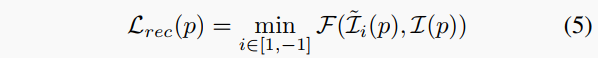
其中‘1’和‘-1’分别指前向和后向相邻帧。
光滑损失。边缘感知平滑损失用于进一步改进反深度映射d:
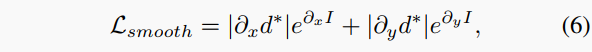
其中表示平均归一化的反深度。并计算一个自动掩码μ来过滤静止帧和一些重复的纹理区域。
迭代自我蒸馏损失。如前所述,GasMono自我蒸馏伪标签以提供额外的监督。给定根据算法1获得的伪标签,我们最小化预测深度d相对于它的对数误差:
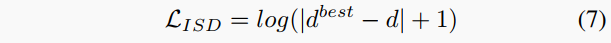
总损失。最后,在任何给定尺度上计算视图重建损失、光滑损失 和蒸馏项(均带到全分辨率),以获得总损失项。更具体地说,计算两个重建损失,即 和 :
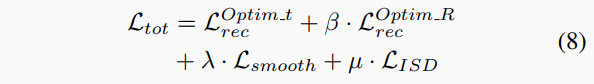
其中和分别基于平移和旋转优化后得到的姿态进行图像重建计算,β、λ和μ分别设置为0.2、0.001和0.1。最后,在所有尺度上平均总损失。
4. 实验结果
本文的实验结果主要通过在多个数据集上分析和比较GasMono框架的性能来进行评估。在实验部分,作者使用了三个室内数据集(NYUv2、7scenes和ScanNet)和一个室外数据集(KITTI)。作者对GasMono的行为进行了详细的研究,分析了使用COLMAP位置和姿态优化策略训练的GasMono的效果。此外,作者还对模型的各个组件进行了消融实验,评估了它们对解决室内单目深度估计挑战的贡献。最后,作者还与现有的先进方法进行了比较,证明了GasMono在室内自监督单目深度估计中的优势。
表1. 消融研究。
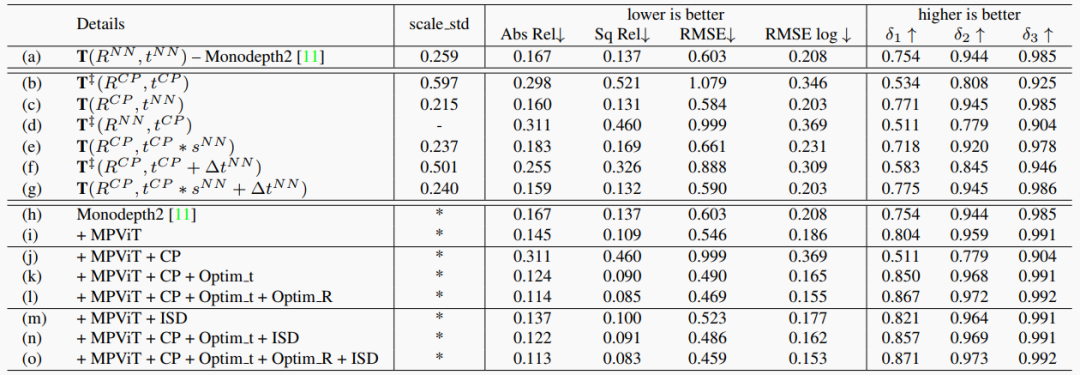
表2. 在室外KITTI数据集上测试了我们的ISD和不同基线方法。
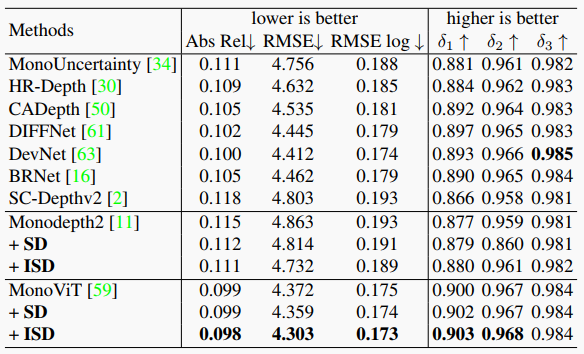
表3. 在NYUv2上的评估结果。
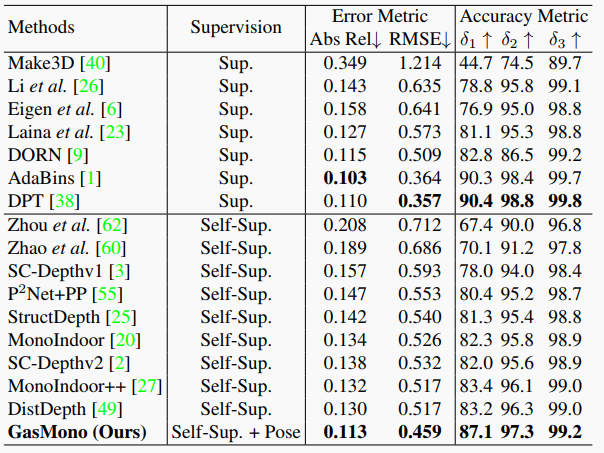
表4. 在ScanNet上的零测量泛化结果。
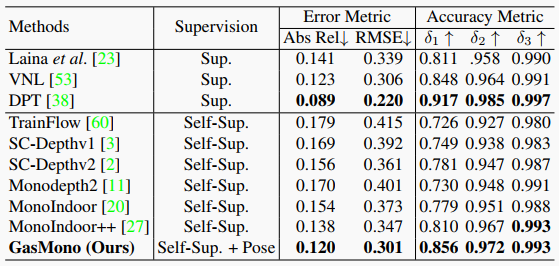
表5. 在RGB-D 7场景上的零测量泛化结果。注意,Monoindoor++从每个视频序列中提取每30帧的第一张图像作为测试集,而我们遵循SC-Depthv2,从每10帧中提取第一张图像。
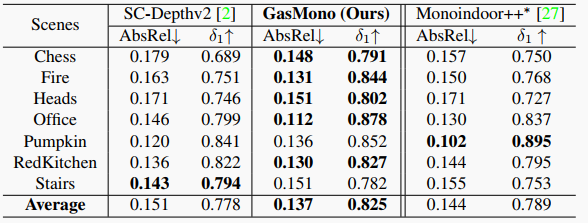
表6. 在RGB-D 7场景上微调后的结果。
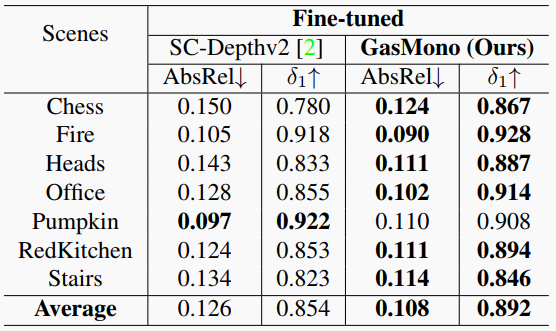
可视化结果如下:

图4. 深度评估中的低纹理区域。

图5. 在NYUv2上的定性比较。我们的GasMono相比于基线方法Monodepth2和最近的工作SC-Depthv2,获得了更细致和更准确的深度估计。

图6. 在ScanNet和7scenes上的泛化比较。与TrainFlow、Monodepth2和SC-Depthv2相比,GasMono在新场景上显示出更准确和更细致的深度估计。

5. 结论
本文提出了GasMono,一种利用几何信息的自监督单目深度估计框架,适用于复杂的室内场景。我们的方法通过缩放和精炼两个步骤,解决了自监督训练中由于姿态估计不准确而导致的尺度不一致和深度不精确的问题,并有效地利用了几何方法提供的粗略姿态。实验结果表明,我们的方法在NYUv2和KITTI数据集上显著并稳定地超越了所有现有方法。此外,我们的方法在ScanNet和7Scenes数据集上也表现出了优异的泛化能力。
编辑:黄飞
-
一种基于图像平移的目标检测框架2021-08-31 0
-
一种基于综合几何特征和概率神经网络的HGU轴轨识别方法2021-09-15 0
-
如何去实现一种ThreadX内核框架的设计呢2021-11-29 0
-
如何利用STM32去实现一种两轮自平衡车呢2021-12-20 0
-
在RK3399开发板上如何去实现一种人工智能深度学习框架呢2022-03-07 0
-
基于深度学习的多尺幅深度网络监督模型2017-11-28 851
-
一种自监督同变注意力机制,利用自监督方法来弥补监督信号差异2020-05-12 7421
-
一种基于光滑表示的半监督分类算法2021-04-08 494
-
采用自监督CNN进行单图像深度估计的方法2021-04-27 794
-
一种有效的无监督深度表示器(Mix2Vec)2022-03-24 1331
-
用于弱监督大规模点云语义分割的混合对比正则化框架2022-09-05 1061
-
基于几何单目3D目标检测的密集几何约束深度估计器2022-10-09 715
-
一种用于自监督单目深度估计的轻量级CNN和Transformer架构2023-03-14 1543
-
深度学习框架和深度学习算法教程2023-08-17 718
-
动态场景下的自监督单目深度估计方案2023-11-28 277
全部0条评论

快来发表一下你的评论吧 !
