

内存内核中发生页面迁移的典型场景
描述
1. 概述
页面迁移(page migrate)最早是为 NUMA 系统提供一种将进程页面迁移到指定内存节点的能力用来提升访问性能。后来在内核中广泛被使用,如内存规整、CMA、内存hotplug等。
页面迁移对上层应用业务来说是不可感知的,因为其迁移的是物理页面,而应用只访问的是虚拟内存。内核迁移完成后,更新修改对应页表指向迁移后的页面即可。当然了这里说的不可感知是指业务不太关注,也不需要做对应修改。实际上有些场景发生页面迁移是业务性能是有影响的,下面会详细描述。
2. 典型场景
我们列举2个内核中发生页面迁移的典型场景。
2.1 NUMA Balancing引起的页面迁移
在典型 NUMA 中,存在多个 node, 本地 CPU 访问本地 node 节点对应的 memory 性能会快一些。
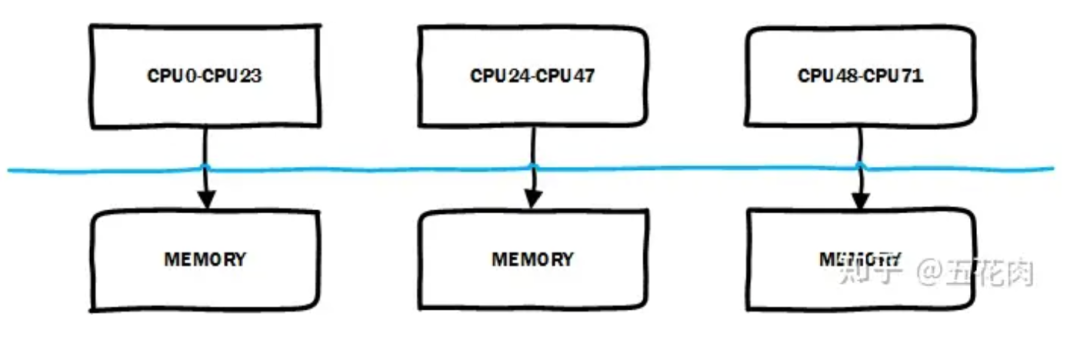
Linux 的 NUMA 自动均衡机制会尝试将内存迁移到正在访问它的 CPU 节点所在的 node。如下图所示, CPU24 ~ CPU47 访问不是本地 node 对应的 memory,性能会比较慢,系统会将其迁移到本地 node 对应的 memory 以提升访问性能。
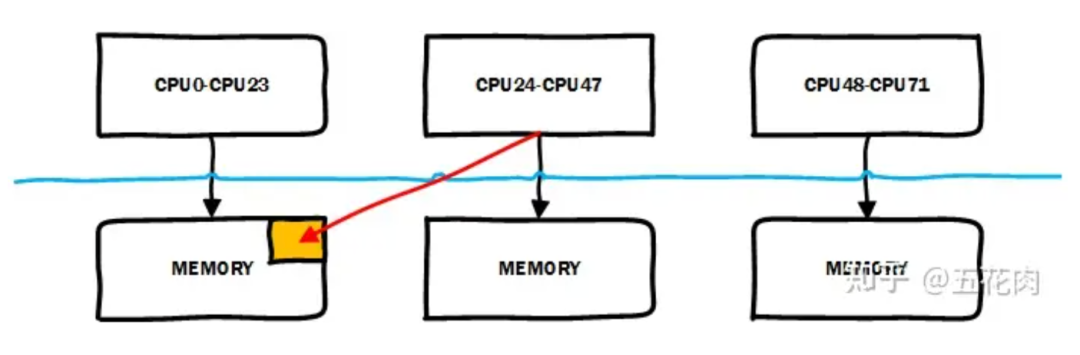
迁移后如下图:
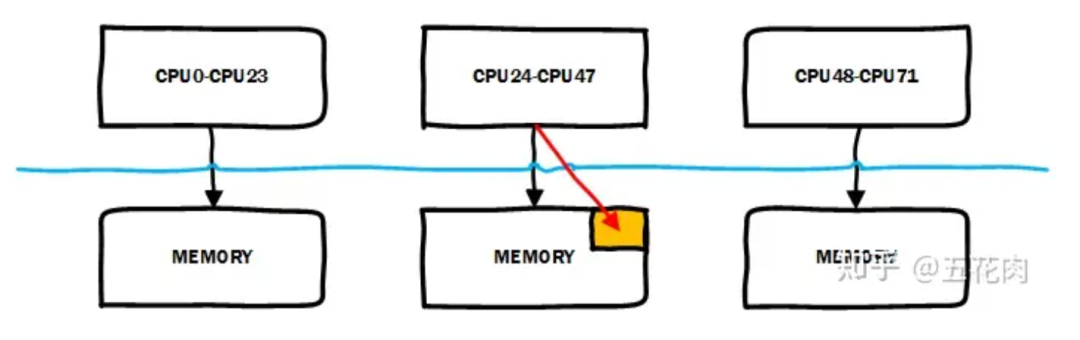
2.2 内存碎片整理
系统使用一段时候后,由于内存碎片的原因,较难满足连续内存需求,如果需要分配连续大块内存,需要进行内存规整以形成大块连续内存,页面迁移是内存碎片整理的基础。
3. 实现分析
3.1 迁移模式
内核中通过接口 migrate_pages 实现页而迁移, 分为3个模式。
| 模式 | 简介 | 应用场景 |
|---|---|---|
| MIGRATE_ASYNC | 异步迁移,过程中不会发生阻塞 | 内存分配slowpath |
| MIGRATE_SYNC_LIGHT | 轻度同步迁移,允许大部分的阻塞操作,唯独不允许脏页的回写操作 | kcompactd触发的规整 |
| MIGRATE_SYNC | 同步迁移,迁移过程会发生阻塞,若需要迁移的某个page正在writeback或被locked会等待它完成 | sysfs主动触发的内存规整 |
| MIGRATE_SYNC_NO_COPY | 同步迁移,但不等待页面的拷贝过程。页面的拷贝通过回调migratepage(),过程可能会涉及DMA | migrate_vma_pages |
3.2 实现流程
内核文档有描述这个API是怎么工作的。不过这个描述着实是不太友好, 不容易在脑海形成画面。

我们通过结合代码实现,把这个转化为流程图:
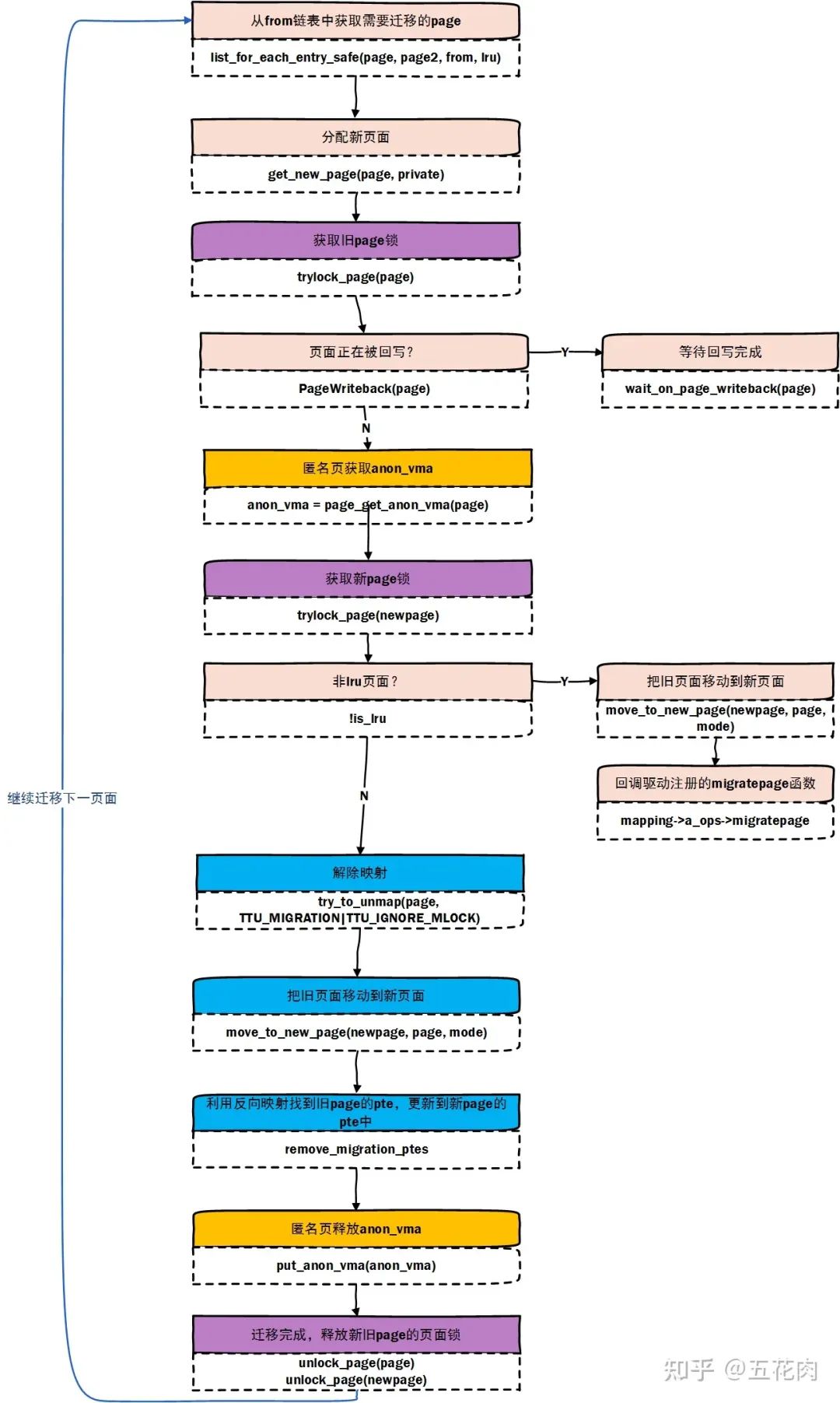
总结一下,页面迁移过程本质就是分配一个 new_page, 解除原有 page 映射,把旧 page 复制到新 page 并建立新 page 的映射。
4. 页面迁移过程用户态访问处理
到这里可能会有疑问:如果在页面迁移过程中,应用发生发访问这个迁移中的页面,会发生什么?
情景1: 旧页面的页表还未解映射, 此时发生缺页可以正常访问原来页面。
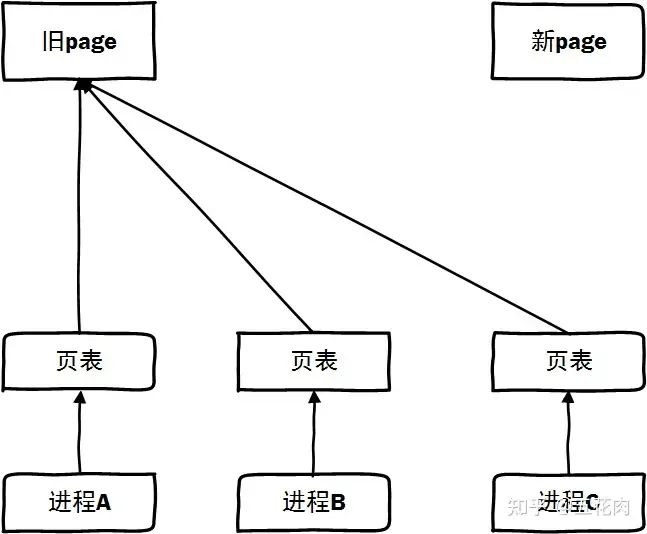
情景2: 旧页面解除了映射,但新页面还未建立映射。这时访问会发生等待,需要等新页面建立映射并copy完成页面后才能访问。
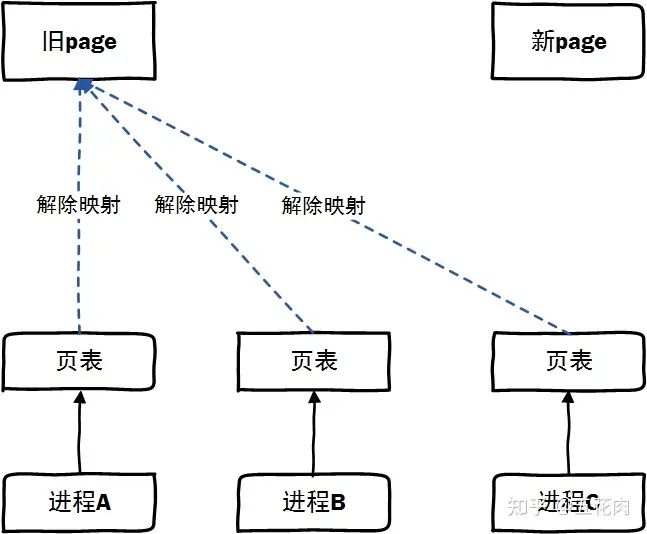
情景3: 完成了页面迁移动作,可以正常访问新页面了。
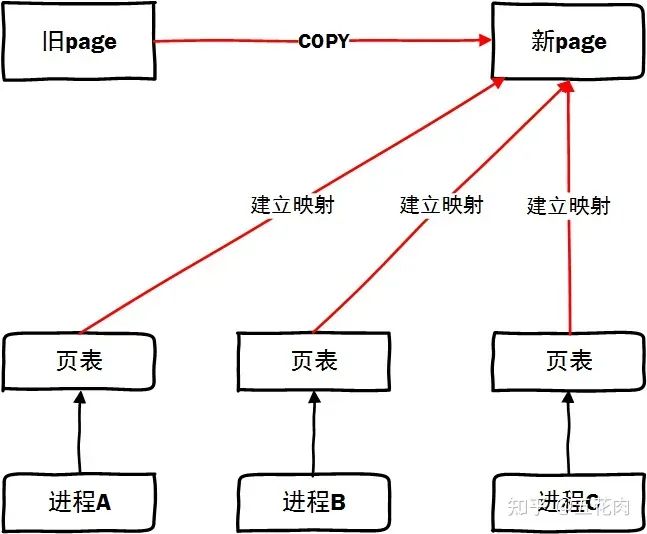
下面我们重点分析一下,当旧页面解除了映射,且新页面未建立映射这个过程中发生了用户态访问,内核的处理流程是怎样的。
首先我们看一下旧页面解除了映射的过程:
static bool try_to_unmap_one(struct page *page, struct vm_area_struct *vma,
unsigned long address, void *arg)
{
...
if (PageHWPoison(page) && !(flags & TTU_IGNORE_HWPOISON)) {
...
} else if (pte_unused(pteval) && !userfaultfd_armed(vma)) {
...
} else if (IS_ENABLED(CONFIG_MIGRATION) &&
(flags & (TTU_MIGRATION|TTU_SPLIT_FREEZE))) {
// 页面迁移会设置TTU_MIGRATION标记,走到这个分支来
swp_entry_t entry;
pte_t swp_pte;
if (arch_unmap_one(mm, vma, address, pteval) < 0) {
set_pte_at(mm, address, pvmw.pte, pteval);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
/*
* Store the pfn of the page in a special migration
* pte. do_swap_page() will wait until the migration
* pte is removed and then restart fault handling.
*/
// 迁移中的页面, 生成了一个swap entry, 并写到PTE页表项中
// 当再次发生缺页时会走进do_swap_page等待直到迁移完成.
entry = make_migration_entry(subpage, pte_write(pteval));
swp_pte = swp_entry_to_pte(entry);
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
if (pte_uffd_wp(pteval))
swp_pte = pte_swp_mkuffd_wp(swp_pte);
// 当设置了迁移标记的Swap entry到pte后, 这个旧页面就不能像原来那样的顺利被访问了
set_pte_at(mm, address, pvmw.pte, swp_pte);
/*
* No need to invalidate here it will synchronize on
* against the special swap migration pte.
*/
} else if (PageAnon(page)) {
swp_entry_t entry = { .val = page_private(subpage) };
pte_t swp_pte;
/*
* Store the swap location in the pte.
* See handle_pte_fault() ...
*/
if (unlikely(PageSwapBacked(page) != PageSwapCache(page))) {
WARN_ON_ONCE(1);
ret = false;
/* We have to invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm, address, address + PAGE_SIZE);
page_vma_mapped_walk_done(&pvmw);
break;
}
...
}
解除映射后,再次发生映射就走到 do_swap_page 中了。
vm_fault_t do_swap_page(struct vm_fault *vmf)
{
...
// 获取到这是一个在迁移过程的的PTE的标识
entry = pte_to_swp_entry(vmf->orig_pte);
if (unlikely(non_swap_entry(entry))) { // 不是传统的Swap entry
if (is_migration_entry(entry)) { // 是迁移标记进来的
/* 等待migration的完成。本质是在等待旧page释放其page lock
* 最终调用到 wait_on_page_bit_common
*/
migration_entry_wait(vma->vm_mm, vmf->pmd, vmf->address);
}
...
}
总结一下:
页面迁移前,首先会获取旧页面和新页面的页面锁 PG_lock,在解除映射的时候传入了由于页面迁移导致的解映射标记 TTU_MIGRATION,设置了此标记会生成一个带页面迁移标识的 swap_entry 设置到 pte 中。在设置好的那一刻走,应用进程无法很顺利地访问这个页面了,需要通过 do_swap_entry 路径。
假如此时应用进程访问了这个页面,会走进到 do_swap_entry,取出带迁移标识的 swap_entry,识别到这个标识,会等待页面锁释放。页面锁只有在页面迁移完成后才会被释放,也就是会发生等待直到页面迁移完成。
5. 用户态如何避免发生页面迁移
上面我们已经知道,如果有页面迁移过程中发生用户态访问,很可能是需要发生等待其迁移完成, 这个过程需要一定耗时。而有时的场景我们是需要避免此种时延抖动,那有什么办法呢?
方法就是让这个页面短时间内变得不可移动。
int migrate_page_move_mapping(struct address_space *mapping,
struct page *newpage, struct page *page, int extra_count)
{
...
if (page_count(page) != expected_count)
return -EAGAIN;
...
return MIGRATEPAGE_SUCCESS;
}
可以看到当发生页面复制过程中,如果 page 的引用计数不符合预期(期望为0)时,这时系统认为有人在使用,不适用做迁移。那么,我们只需要增加 page 的引用计数就可以。
可以在不想被迁移的时间段开始前通过 pin_user_pages 这样的接口,结束时 unpin 就可以了。接口最终会调到 try_grab_page 增加引用计数。
bool __must_check try_grab_page(struct page *page, unsigned int flags)
{
...
refs = GUP_PIN_COUNTING_BIAS; // #define GUP_PIN_COUNTING_BIAS (1U << 10)
page_ref_add(page, refs);
}
return true;
}
编辑:黄飞
-
Linux内存系统:内存使用场景2020-08-25 0
-
新能力让数据多端协同更便捷,数据跨端迁移更高效!2022-01-11 0
-
内存之旅——如何提升CMA利用率?2022-03-22 0
-
LINUX内核中的内存是如何进行分配的2022-11-04 0
-
一种基于内存关联分析的预拷贝迁移策略2021-05-14 656
-
LINUX源代码分析-内存管理2011-12-19 845
-
一文解析Linux内存系统2020-09-01 2242
-
基于内存关联分析的内存预拷贝迁移策略2021-05-24 711
-
Linux内存管理之页面回收2022-05-19 894
-
Linux内核虚拟内存管理中的mmu_gather操作2022-05-20 1614
-
走进Linux内存系统探寻内存管理的机制和奥秘2023-01-05 1385
-
Linux内核内存泄漏怎么办2023-07-04 602
-
Linux内核内存管理架构解析2024-01-04 333
-
Linux内核内存管理之内核非连续物理内存分配2024-02-23 400
全部0条评论

快来发表一下你的评论吧 !
