

了解亚马逊云科技搭建智能搜索大语言模型增强方案的快速部署流程
描述
背景
知识库需求在各行各业中普遍存在,例如制造业中历史故障知识库、游戏社区平台的内容知识库、电商的商品推荐知识库和医疗健康领域的挂号推荐知识库系统等。为保证推荐系统的实效性和准确性,需要大量的数据/算法/软件工程师的人力投入和包括硬件在内的物力投入。那么在自己的环境中搭建智能搜索大语言模型增强方案是必不可少的。因此,本篇内容主要为大语言模型方案的快速部署。该方案部署流程并不复杂,只需要您对于亚马逊云科技相关服务有一个基本的了解即可。
方案架构图与功能原理
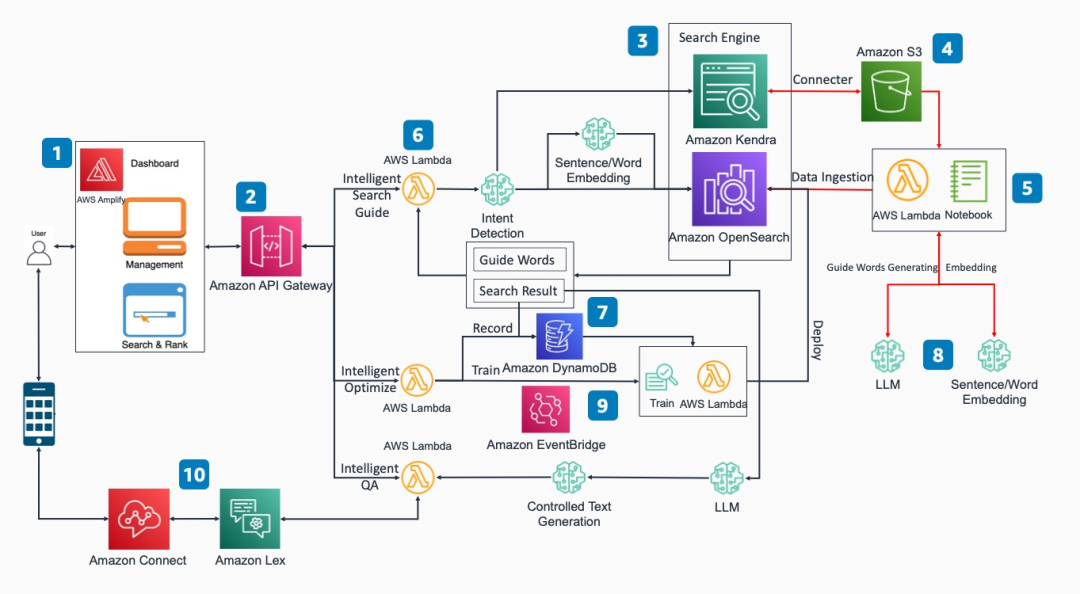
该方案分为以下几个核心功能模块:
前端访问界面:该方案提供了基于React的前端访问界面。用户可以通过网页以REST API的形式进行智能文档搜索等功能的操作。
REST API:通过集成了相应Amazon API Gateway和Amazon Lambda函数的实现和后端搜索引擎,数据库和模型推理端点交互。
企业搜索引擎:基于Amazon OpenSearch或Amazon Kendra。可以基于双向反馈的学习机制,自动持续迭代提高输出匹配精准度。同时采用引导式搜索机制,提高搜索输入描述的精准度。
数据源存储:可选用多种存储方式如数据库,对象存储等,在这里Amazon Kendra通过连接器获取Amazon S3上的对象。
向量化数据注入:采用Amazon SageMaker的Notebook模块或者Amazon Lambda程序将原始数据向量化后的数据注入Amazon OpenSearch。
智能搜索/引导/问答等功能模块:采用Amazon Lambda函数实现和后端搜索引擎,数据库和模型推理端点交互。
记录数据库:用户反馈记录存储在数据库Amazon DynamoDB。
机器学习模型:企业可以根据自身需要构建大语言模型和词向量模型,将选取好的模型托管到Amazon SageMaker的endpoint节点。
反馈优化:用户在前端页面反馈最优搜索结果,通过手动或事件触发器Amazon EventBridge触发新的训练任务并且重新部署到搜索引擎。
插件式应用:利用该方案核心能力可以与Amazon Lex集成以实现智能会话机器人功能,也可以与Amazon Connect集成实现智能语音客服功能。
实施步骤介绍
以smart-search v1版本为例,为大家讲解方案的整个部署流程。
1、环境准备
首先您需要在您的开发环境中安装好python 3、pip以及npm等通用工具,并保证您的环境中拥有16GB以上的存储空间。根据您的使用习惯,您可以在自己的开发笔记本(Mac OS或Linux环境)上部署,也可以选择EC2或者Cloud9进行部署。
2、CDK自动部署
2.1 获取代码安装Amazon CDK包
获取代码后把代码拷贝到指定目录下。打开终端窗口,进入smart_search的软件包,并切换到名为deployment文件夹下:

进入到deployment目录后,相应的CDK部署操作均在该目录下进行。然后安装Amazon CDK包。
2.2 安装CDK自动化部署脚本所需的所有依赖项和环境变量
在deployment目录下运行以下命令安装依赖库:

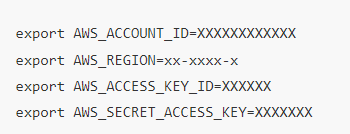
然后将您的12位亚马逊云科技账号信息、Acess Key ID、Secret Access Key、以及需要部署的Region ID导入到环境变量中:
然后运行“cdk bootstrap”安装账户和目标区域内的CDK工具包,例如:

2.3 在cdk.json可以进行自定义配置
该方案的默认配置文件在deployment目录下的cdk.json文件中,如果想要自行配置需要部署哪些功能模块,可以根据需要修改cdk.json的“context”部分。例如,如果需要修改部署哪些功能函数,可以对“selection”值进行修改。
默认的参数如下所示:

如果仅需要使用“支持knn的文档搜索功能”,可以仅保留“knn_doc”。除此之外,还可以选择通过修改cdk.json的其他相应参数来自定义部署方式、部署哪些插件和名称和路径等配置。
2.4 CDK命令自动化署
运行下面的命令将验证环境并生成Amaon CloudFormation的json模版:

如果没有报错,则运行以下命令部署全部堆栈。

CDK部署将提供相关Amazon CloudFormation堆栈以及相关资源,例如Amazon Lambda、Amazon API Gateway、Amazon OpenSearch实例和Amazon SageMaker的notebook实例等,预计安装的部署时间大约为30分钟左右。
3、利用Amazon SageMaker的Notebook实例部署模型与数据导入
3.1 部署模型
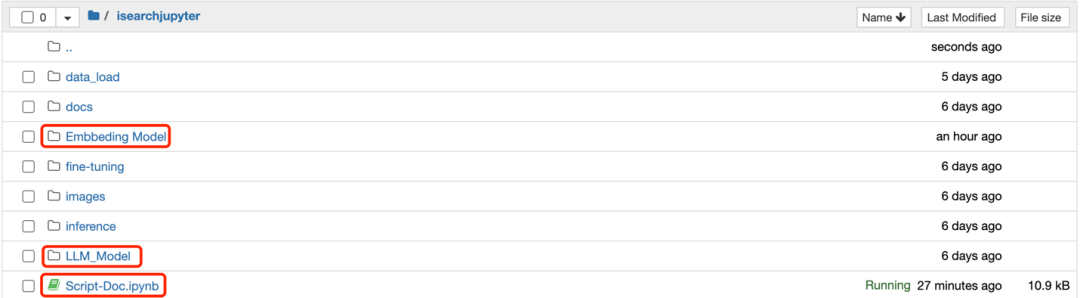
3.1.1进入Amazon SageMaker控制台,进入NoteBook Instances,选择SmartSearchNoteBook实例,点击“Open Jupyter”,进入SmartSearch的代码主目录,点击“isearchjupyter”目录进入,能看到包括Embbeding Model、LLM_Model等目录,这两个目录包含模型部署脚本,而Script-Doc.ipynb脚本则会用于后面的文档上传,目录如下图所示:
3.1.2首先安装Embbeding Model,进入“/isearchjupyter/Embbeding Model”目录,能看到对应的几个脚本。其中“EmbbedingModel_shibing624_text2vec-base-chinese.ipynb”为中文的词向量模型,其他两个为英文,打开相应脚本依次运行单元格,开始部署embbeding model。等待script部署完毕,成功部署后会在Amazon SageMaker的endpoint中看到名为“huggingface-inference-eb”的endpoint,状态为“InService”。
3.1.3然后部署大语言模型,LLM_Model目录下当前包含了中文和英文的大语言模型库。这里先为大家介绍中文的大语言模型的部署方法,找到isearchjupyter/LLM_Model/llm_chinese/code/inference.py,该文件定义了大语言模型的统一部署方法。大语言模型可以通过唯一的名称进行部署,把该唯一名称声明为“LLM_NAME”的参数值,作为参数传递给部署脚本。可以根据大语言模型的文档来确定“LLM_NAME”的值。打开网址后对照该文档找到该模型部署的唯一名称,然后粘贴到为“LLM_NAME”赋值的位置即可,可以参照该方法举一反三,指定项目中需要使用的大语言模型。修改inference.py文件后进入“isearchjupyter/LLM_Model/llm_chinese/“目录,运行该目录的script。等待script 部署完毕,成功部署后会在Amazon SageMaker的endpoint中看到名为“pytorch-inference-llm-v1”的endpoint。
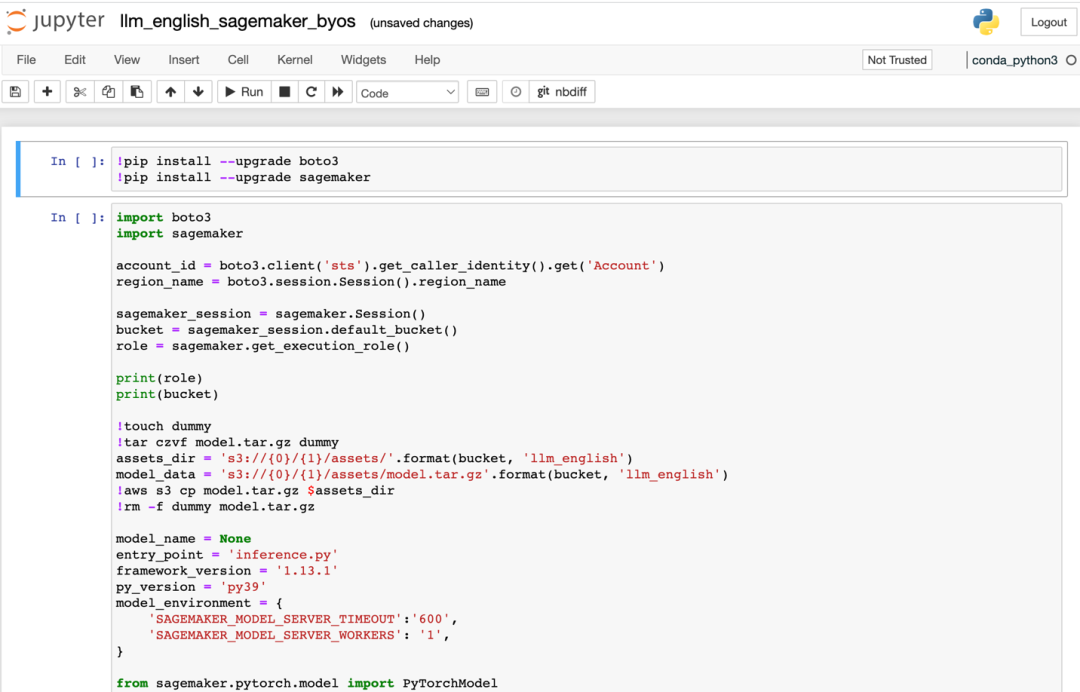
如果选择部署英文大语言模型,部署方式类似,需要将英文大语言模型的参数填入LLM_Model/llm_english/code/inference.py文件的“LLM_NAME”参数中。找到该大语言模型项目名称,则然后复制该名称再粘贴到为“LLM_NAME”赋值的位置,可以用该方法进行举一反三,指定任意一个满足业务需求的大语言模型。进入“isearchjupyter/LLM_Model/llm_english/”的目录下,依次运行该目录下英文大语言模型的脚本的部署单元格。如下图所示:
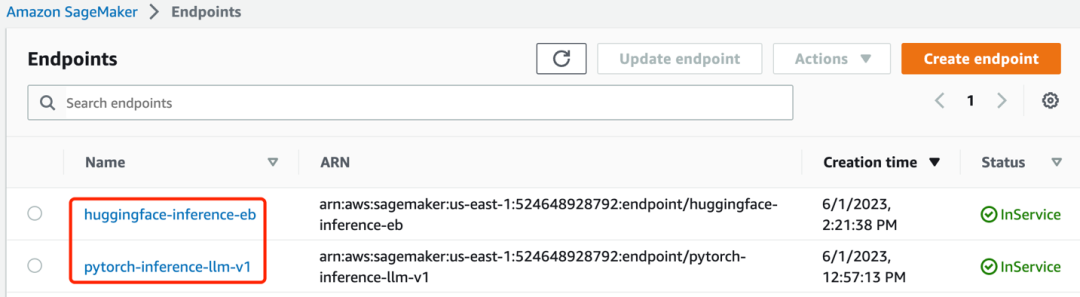
3.1.4安装完成后,看到两个endpoint已经在”InService”状态,如下图:
3.2 知识库数据上传
3.2.1数据准备。进入jupyter的目录“/isearchjupyter”,在“docs”目录,将上传所需要的word、excel或pdf等格式的文档进行上传,该文件夹下已经提供了用于测试的样例文件“sample.docx”。
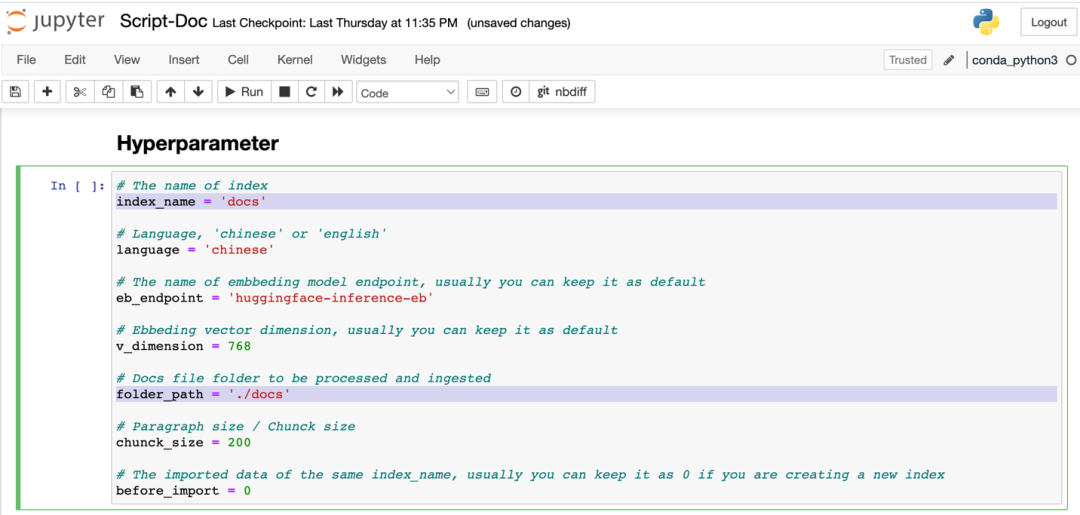
3.2.2 进入Script-Doc.ipynb,修改单元格“Hyperparameter”的如下参数,folder_path为指定的docs目录,index_name为Amazon OpenSearch的index名称,如下图:
然后从头运行这个script,完成数据导入。
4、配置Web UI
4.1 进入smart_search/ search-web-knn目录,该目录包含基于React的前端界面代码。然后对/src/pages/common/constants.js文件进行编辑,如下图所示:
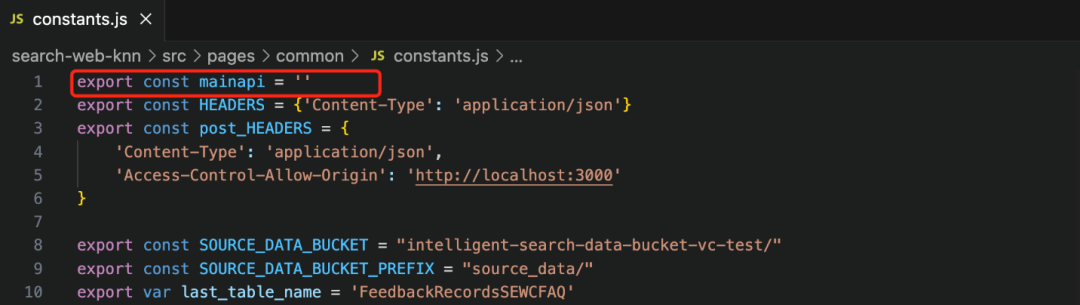
Mainapi常变量指定了前端调用的API入口。该值可以从网页端进入API Gateway中获取,进入“smartsearch-api”的Stages侧边栏,将prod stage的involke URL赋值给constants.js的mainapi常变量。
4.2 检查主页面参数配置。smart_search/search-web-knn/src/pages/MainSearchDoc.jsx为功能展示页面,在该文件的last_index参数设置了页面自动填充的默认index值,将上文Notebook实例部署的index name填入,如“docs”。
4.3 运行前端界面。进入目录 search-web-knn,执行如下两条命令:

然后运行以下命令启动前端界面:

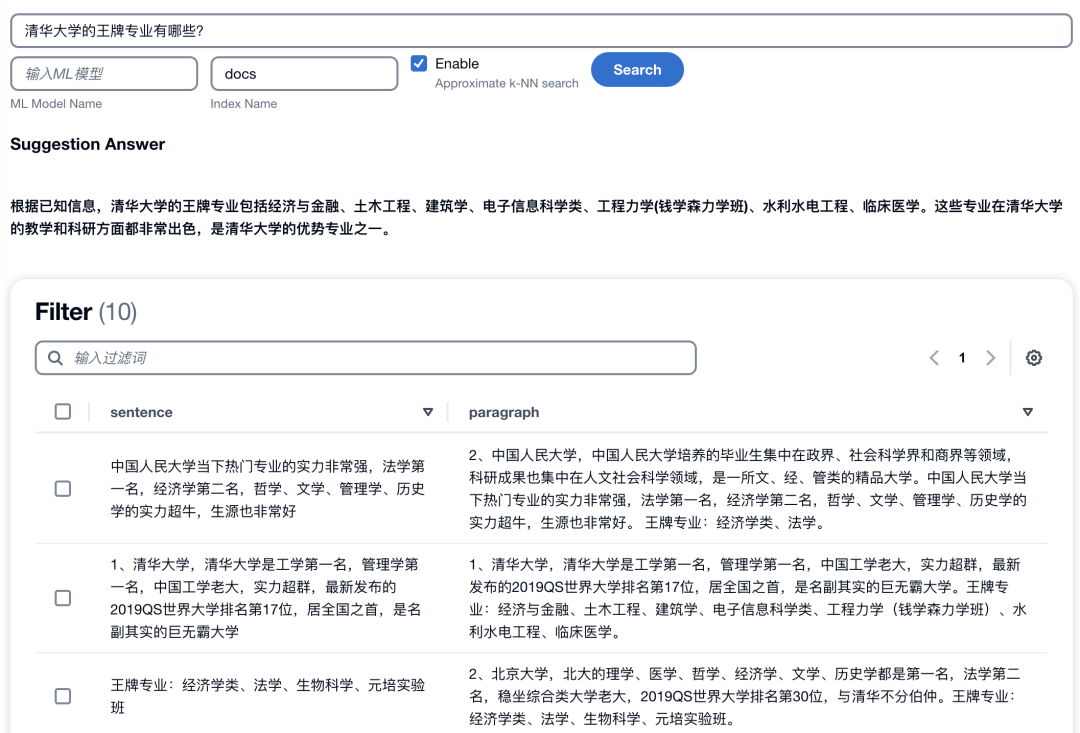
一切顺利的话,将得到一个网页版界面。在本地开发笔记本部署的默认访问地址和端口号是localhost:3000,如果是EC2部署,需要启用对应端口访问的安全组策略,通过EC2的公网地址加端口号进行访问。该前端页面的使用方法为:将问题输入搜索栏,配置index名称和k-NN选项,点击“Search”按钮后您可以得到一个基于企业知识库的大语言模型汇总回答。如下图所示:
5、安装扩展插件
5.1 与Amazon Lex集成实现智能聊天机器人
本方案已经集成了Amazon Lex的会话机器人功能,Amazon Lex当前在海外区可用。在cdk.json文件中,将“bot”加入extension键值处。
cdk部署成功后进入管理界面可以看到名为“llmbot”的对话机器人,如下图:
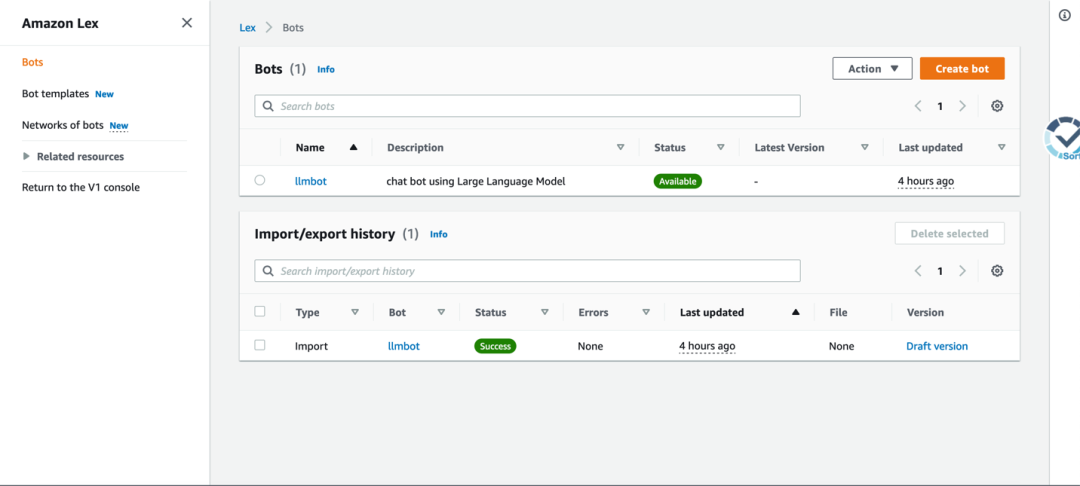
该机器人可以方便地进行前端页面的集成。
5.2 与Amazon Connect集成实现智能语音客服
Amazon Connect为亚马逊云科技的云呼叫中心服务,该服务当前在海外区可用。该方案可以通过Amazon Lex机器人将大语言模型能力集成到Amazon Connect云呼叫中心中,通过以下几个步骤可以使您获得一个支持语音呼叫功能的智能客服机器人。
5.2.1 将上一步生成的llmbot机器人集成到现有Amazon Connect实例中。
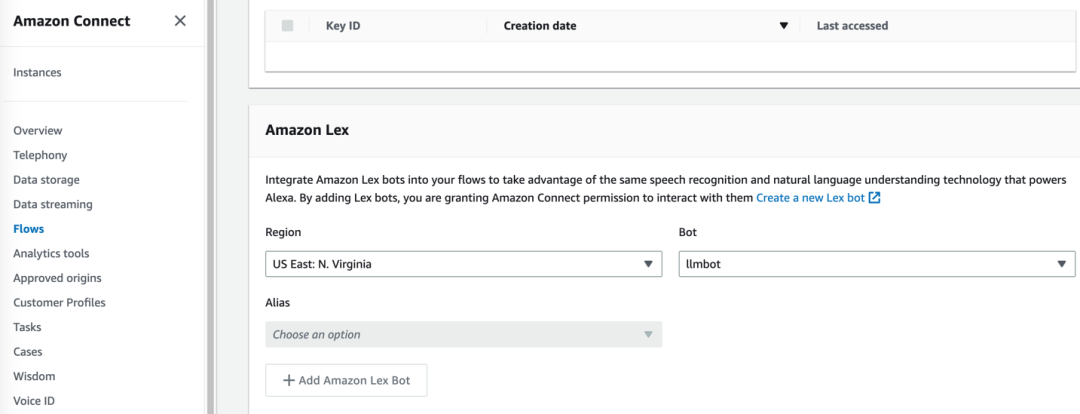
5.2.2 然后进入Amazon Connect实例中,将smart-search/extension/connect里面的文件导入到Contact Flow中,并保存和发布。
5.2.3 最后在Amazon Connect中将呼入号码与上一步配置的Contact Flow进行关联。则所有呼入该号码的语音通话将会连接到智能客服的呼叫服务流程。
正常情况下,智能客服将会识别呼入人的语音输入,随后集成到Amazon Connect的智能客服机器人会基于企业知识库信息和大语言模型的能力进行以接近人类的逻辑方式进行语音回答。
6、资源清理
想要将资源进行清理时,请使用以下命令将所有堆栈进行删除:
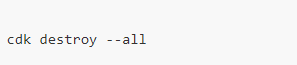
注意:通过Amazon SageMaker的Notebook实例创建的推理模型资源需要进行手动删除,在Amazon SageMaker的“inference”边栏进入“endpoint”,点击“delete”,将所有endpoint进行删除。
当堆栈创建的Amazon S3桶中已经有了数据或者存在其他手动创建或修改的资源时,则也需要手动删除。
总结
通过此次部署,已经成功掌握了该方案的部署方法,也对该方案有了更深的了解。亚马逊云科技将会对该方案进行持续的迭代与优化以支持更多的数据类型、模型库与扩展功能,进而将方案的能力延伸到更多的业务场景中去。该方案可以解决许多行业和领域的专业或通用场景,通过使用该方案可以使用人工智能的最新进展和亚马逊云科技的产品来为行业发展注入新的活力。
审核编辑 黄宇
-
五分钟了解机智云2016-12-27 0
-
轻松搞定亚马逊Echo控制智能设备2017-02-24 0
-
亚马逊Echo控制智能家居的原理2017-03-08 0
-
玩 High API 系列之:智能云相册2018-02-05 0
-
机智云提供的智能照明方案简单介绍2018-09-03 0
-
安森美半导体开发方案助力客户快速开发及部署物联网设备2018-10-26 0
-
简化针对云服务的语音检测算法的部署2021-03-03 0
-
企业云桌面要如何部署2021-09-23 0
-
如何快速搭建STM32应用模型?2022-02-10 0
-
重磅!华秋第八届硬创赛与亚马逊云科技达成战略合作2022-07-01 0
-
天使赋能,科技智造:华秋第八届硬创赛与亚马逊云科技达成战略合作2022-07-01 0
-
通过Cortex来非常方便的部署PyTorch模型2022-11-01 0
-
虹科分享 | 谷歌Vertex AI平台使用Redis搭建大语言模型2023-09-18 369
-
开启智能时代:亚马逊云科技倾力打造大语言模型前沿应用2023-12-06 507
全部0条评论

快来发表一下你的评论吧 !
