

ECON:最新单图穿衣人三维重建SOTA算法
描述
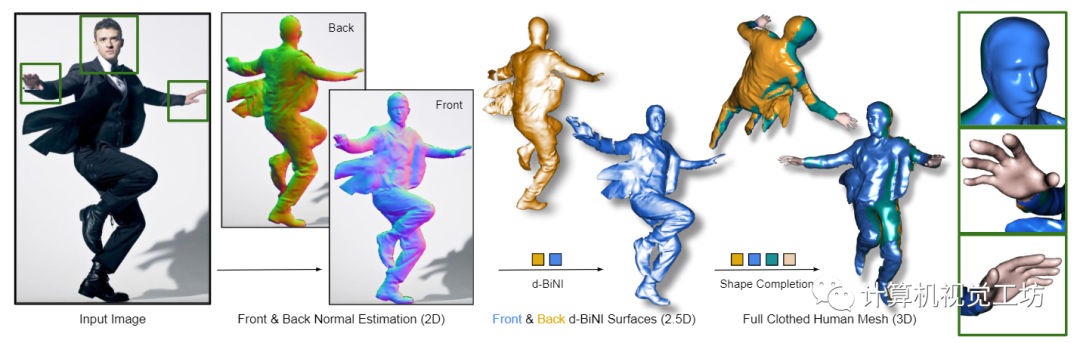
图1所示。从彩色图像进行人体数字化。ECON结合了自由形式隐式表示的最佳方面,以及明确的拟人化正则化,以推断高保真度的3D人类,即使是宽松的衣服或具有挑战性的姿势。
0.笔者个人体会
这篇文章讨论了单图像的穿着人类重建问题。
隐式方法可以用来表示任意3D穿着人类形状,因为它不依赖于拓扑结构,因此具有更高的灵活性。这种方法的缺点是难以扩展到多种服装样式,限制了其在真实场景中的应用。
相比之下,显式方法则使用网格或深度图或点云来重建3D人类。这些方法主要关注于估计或回归最小穿着的3D身体网格,而忽略了衣服。为了考虑穿着人类的形状,另一类工作通过添加3D偏移量到身体网格上来进行建模。这种方法与当前的动画管道兼容,因为它们继承了从统计身体模型中得出的层次化骨架和权重。然而,这种方法对于宽松的衣服来说不够灵活,因为它们与身体拓扑结构有很大的不同,例如衣服和裙子。为了增加拓扑灵活性,一些方法通过识别服装类型并使用适当的模型来重建它。但是,这种方法很难扩展到多种服装样式,限制了其在真实场景中的泛化能力。
这篇文章介绍了穿着人类重建的最新进展和挑战,通过将隐式方法和显式方法相结合实现了更好的单图穿衣人重建。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。
1.摘要
深度学习、艺术家策划的扫描和隐式功能(IF)的结合,使从图像中创建详细的、有衣的3D人体成为可能。然而,现有的方法还远远不够完美。基于隐式功能(IF)的方法恢复了自由几何形状,但会产生无实体的肢体或退化的形状,以实现新颖的姿势或衣服。为了增加这些情况的鲁棒性,现有工作使用显式的参数化的身体模型来约束表面重建,但这限制了自由形状表面的恢复,例如偏离身体的宽松衣服。我们想要的是一种结合隐式表示和显式体正则化的最佳特性的方法。为此,我们做了两个关键的观察:(1)目前的网络比全3d表面更擅长推断详细的2D地图,(2)参数化模型可以被看作是将详细的表面斑块拼接在一起的“画布”。基于这些,我们的方法ECON有三个主要步骤:(1)它推断出一个穿着衣服的人的正面和背面的详细2D法线图。(2)从中,它恢复2.5D前后表面,称为d-BiNI,这些表面同样详细,但不完整,并在SMPL-X的帮助下相互注册这些w.r.t.,在从照片恢复的SMPL-X身体面片的帮助下该方法通过在d-BiNI表面之间“修复”丢失的几何形状,可以推断出高保真的3D人物,即使在穿着宽松的衣服和摆出具有挑战性的姿势时也能做到。根据在CAPE和Renderpeople数据集上的定量评估,这超过了以前的方法。此外,感知研究还表明,ECON的感知现实主义也明显更好。
2.算法解析
给定RGB图像,ECON首先估计前后法线贴图(第2.1节),然后将它们转换为前后部分表面(第2.2节),最后在IF-Nets+(第2.3节)的帮助下“绘制”缺失的几何形状。参见图3中的ECON概述。
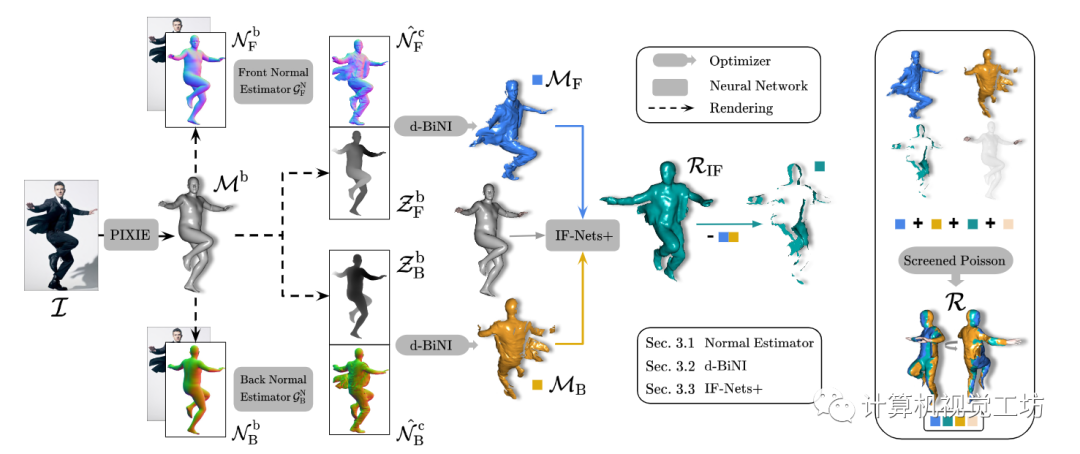
图3。概述。ECON以RGB图像I和SMPL-X主体M'作为输入。在渲染的前后车身法线图像N的条件下,ECON首先预测前后服装法线图N,这两个图,连同车身深度图2,被馈送到d-BiNI优化器中,以产生前后表面{Mr, MB)。基于这样的局部曲面,和身体估计M’。IF-Nets+隐式完成Rir。可选的Face或hands来自M’,经过筛选的泊松将一切结合为最终的水密R。
2.1.详细法线图预测
在大量RGB图像和法线图像对的训练下,使用图像到图像的转换网络可以从RGB图像中准确地估计出“前”法线映射 ,如PIFuHD或ICON。这两种方法还可以从图像中推断出一个“反向”法线贴图 。但是,缺少图像线索会导致 过于光滑。为了解决这个问题,我们对ICON的背面正常预测器 进行了微调,增加了额外的MRF损失,通过最小化特征空间中预测的 和ground truth (GT) 之间的差异来增强局部细节。
为了指导法线贴图预测并使其对各种身体姿态具有鲁棒性,ICON训练了法线映射预测模块,在身体法线贴图 ,从估计的身体 中渲染。因此,准确地对齐估计的身体和衣服轮廓是很重要的。除了ICON中使用的和外,我们还在额外的损失项中应用2D身体标志来进一步优化从PIXIE或PyMAF-X推断的SMPL-X身体M。
2.2.前后表面重建
现在我们将覆盖的法线贴图提升到2.5D表面。我们期望这些2.5D表面满足三个条件:(1)高频表面细节与预测的覆盖法线图一致;(2)低频表面变化(包括不连续面)与SMPL-X的一致;(3)前后轮廓的深度彼此接近。
与PIFuHD或ICON训练神经网络从法线图回归隐式表面不同,我们使用变分法正交积分方法,对深度与法线的关系进行显式建模。具体的,我们利用粗略先验、深度图和轮廓一致性,对最近提出的双向正常集成(BiNI)方法进行定制,用于全身网格重建。
为了满足这三个条件,我们提出了一种深度感知轮廓一致的双边法向积分(d-BiNI)方法,对前后服装深度图进行联合优化
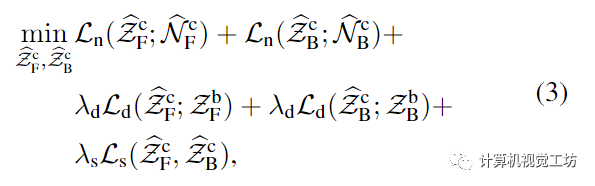
通过Eq.(3),我们做出了两个超出BiNI的技术贡献。首先,我们使用先前从SMPL-X体网格中渲染的粗深度来正则化BiNI:这解决了将前后表面以连贯的方式放在一起形成一个完整的身体的关键问题。其次,我们使用轮廓一致性项来鼓励前后轮廓边界处的深度值相同,在域中计算(图4):
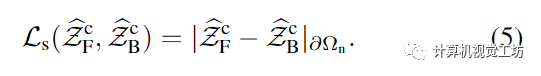
该项提高了重建的前后衣深图的物理一致性。
2.3.人形补全
对于没有自我遮挡的简单身体姿势,如FACSMILE和Moduling Humans中所做的那样,以直接的方式合并前后d-BiNI表面,可以产生完整的3D服装扫描。然而,通常会导致自咬合,从而导致大部分表面缺失。在这种情况下,泊松表面重建(PSR)会导致斑点状伪影。
使用SMPL-X ()完成PSR。“填充”缺失表面的一种简单方法是利用估计的SMPL-X体。我们从中移除前后摄像头可见的三角形。剩下的三角形“汤”包含侧视图边界和遮挡区域。我们将PSR应用于和d-BiNI曲面{}的并集,得到一个水密重建r。虽然避免了四肢或侧面的缺失,但由于SMPL-X与实际的衣服或头发之间的差异,它不能为原来缺失的衣服和头发表面产生一致的表面;见图5中的。
使用IF-Nets+ ()进行绘画。为了提高重建的一致性,我们使用学习的隐函数(IF)模型来“补绘”给定的前后缺失的几何形状d-BiNI表面。具体来说,我们将通用形状补全方法IF-Nets定制为SMPL-X引导的方法,称为IF-Nets+。IF-Nets从缺乏的3D输入(如不完整的3D人体形状或低分辨率体素网格)完成3D形状。受Li等人[44]的启发,我们通过在体素化的SMPL-X身体上调节IF-Nets来处理姿态变化。IF-Nets+以体素化的正面和背面地真深度图()和体素化(估计的)的身体网格()作为输入进行训练,并使用地真3D形状进行监督。在训练过程中,为了对遮挡的鲁棒性,我们随机屏蔽。在推理过程中,我们将估计的和输入IF-Nets+中以获得占用场,并从中提取入画网格,并使用Marching cubes。
用 ()完成PSR。为了获得我们最终的网格R,我们应用PSR来缝合(1)d-BiNI表面,(2)来自Rir的侧面和闭塞的三角形汤纹,以及(3)从估计的SMPL-X裁剪的脸或手,(3)的必要性源于的手/脸重建不佳,见图6的差异。该方法表示为。
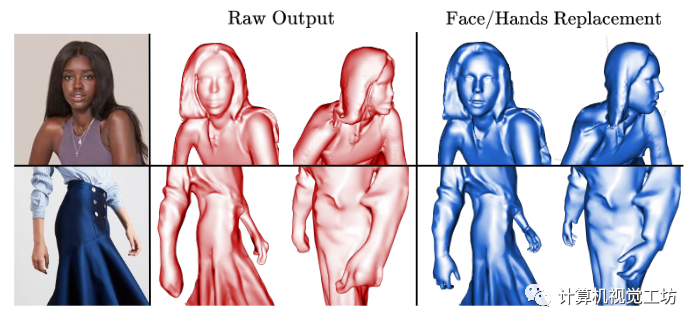
图6。脸部和手部细节。原始重建的脸和手可以换成SMPL-X身体的脸和手。
值得注意的是,尽管已经是一个完整的人体网格,但由于输入的有损体素化和Marching cubes算法的有限分辨率,它在某种程度上平滑了的细节,这些细节是通过d-BiNI优化的(见图5中的 vs )。虽然更好地保留了d-BiNI的细节,但的侧视图和遮挡部分在泊松步骤中被融合。
3.实验
在实验方面,作者将ECON与身体不可知论方法(即PIFu和PIFuHD)和身体感知方法(即PaMIR和ICON)进行比较,见表1。
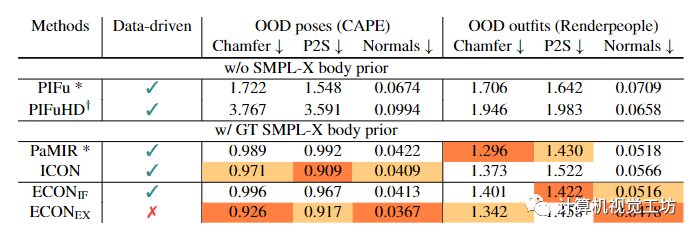
表1 对技术水平的评估。
为了公平比较,作者使用ICON中的PIFu和PaMIR的重新实现,因为它们具有相同的网络设置和输入数据。的性能与ICON相当,并且在包含偏离分布(OOD)姿势(CAPE)的图像上优于其他方法,距离误差低于1cm。在分发套件(Renderpeople)方面,的表现与PaMIR相当,比PIFuHD要好得多。当涉及到法线测量的高频细节时,在两个数据集上都达到了SOTA的性能。
为评估野外图像上的ECON。测试图像分为三类:“具有挑战性的姿势”、“宽松的衣服”和“时尚图像”。挑战性姿势和宽松服装的例子如图9所示。

图9。野外图像的定性结果。我们展示了8个从图像中重建详细的穿衣服的3D人的例子:(a)具有挑战性的姿势和(b)宽松的衣服。对于每个例子,我们都显示了输入图像以及重建的3D人体的两个视图(正面和旋转)。我们的方法对姿势变化具有鲁棒性,可以很好地推广到宽松的衣服,并包含详细的几何形状。
参与者被要求在基线方法和ECON之间选择他们认为更现实的重建方法。我们在表2中计算了每个基线优于ECON的可能性。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。
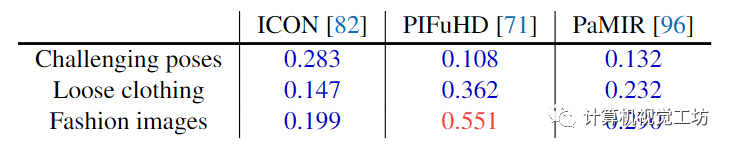
表2。知觉的研究。数字表示参与者更喜欢重建竞争方法而不是ECON重建野外图像的可能性。0.5的值表示相同的偏好。值< 0.5有利于ECON,而值< 0.5有利于竞争对手。
感知研究的结果证实了表1中的定量评估。对于“具有挑战性的姿势”图像,ECON明显优于PIFuHD,并且优于ICON。对于穿着宽松衣服的人的图像,ECON比ICON更受欢迎和优于PIFuHD。
最后在消融实验里作者将d-BiNI和BiNI,IF-Nets+和IF-Nets进行了比较,实验结果如下表所示:

表3。BiNI和d-BiNI。BiNI曲面与d-BiNI曲面w.r.t.重建精度和优化速度的比较。

同时作者也比较了比较了IF-Nets+和IF-Nets在遮挡情况下的几何“补绘”,结果如图5所示:
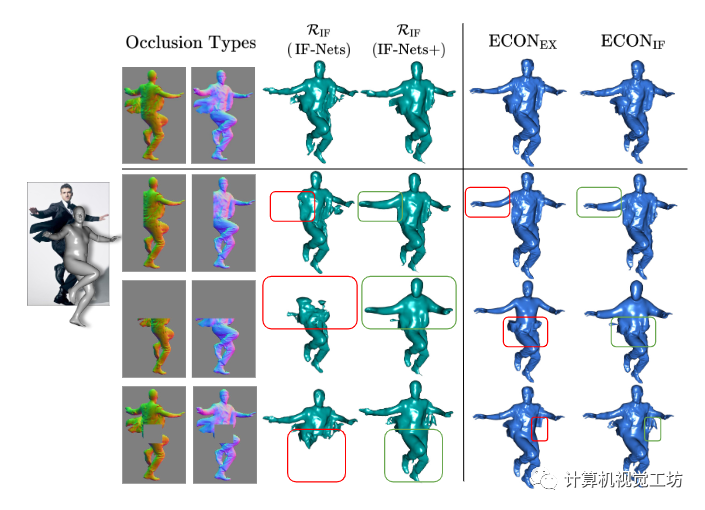
图5。“补绘”缺失的几何图形。我们通过屏蔽正常图像来模拟不同的遮挡情况,并呈现不同设计选择的中间和最终3D重建。虽然IF-Nets遗漏了某些身体部位,但IF-Nets+产生了一个合理的整体形状。由于经过学习的形状分布,ECONir产生的服装表面比ECONEx更一致。
4.展望
虽然ECON在单图人体三维重建上达到了一个全新的高度,但是从单个图像中恢复SMPL-X体(或类似模型)仍然是一个开放的问题,并没有完全解决。任何故障都可能导致ECON故障,如图8-A和图8-B所示。由于合成数据变得足够逼真,它们与真实数据的领域差距显著缩小,可以预见,这种限制将被消除。ECON的重建质量主要依赖于预测法线图的准确性。较差的法线贴图会导致前后表面过近甚至相交,如图8-C和图8-D所示。
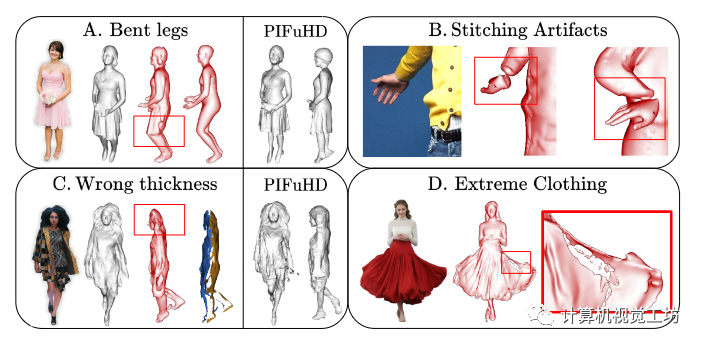
图8。ECON的失败案例。(A-B)恢复SMPL-X体结果的失效,例如,弯曲的腿或错误的肢体姿势,估计会为ECON提供错误的几何形状。扩展导致ECON故障。(C-D)法线映射中的失效
未来的工作。除了解决上述限制之外,其他几个方向对实际应用也很有用。目前,ECON只重建三维几何。人们还可以恢复底层骨骼和皮肤权重,以获得完全可动画的化身。此外,生成后视纹理将产生完全纹理的头像。从恢复的几何图形中分离服装、发型或配饰,将使模拟、合成、编辑和转移这些样式成为可能。ECON的重建,连同它下面的SMPL-X体,可以在学习神经化身之前作为3D形状使用。
-
怎样去设计一种基于RGB-D相机的三维重建无序抓取系统?2021-07-02 0
-
如何去开发一款基于RGB-D相机与机械臂的三维重建无序抓取系统2021-09-08 0
-
无人机三维建模的信息2021-09-16 0
-
基于纹理映射的医学图像三维重建2008-12-14 799
-
MC三维重建算法的二义性消除研究2010-01-22 687
-
一种新颖实用的基于视觉导航的三维重建算法2010-02-27 560
-
基于FPGA的医学图像三维重建系统设计与实现2011-03-15 929
-
基于MC算法的光刻仿真微结构的三维重建_宫珊珊2017-03-18 607
-
为什么说三维重建才是计算机视觉的灵魂?2019-07-02 30541
-
透明物体的三维重建研究综述2021-04-21 632
-
基于分布式传感的实时三维重建系统2021-06-25 524
-
深度学习背景下的图像三维重建技术进展综述2023-01-09 1480
-
如何使用纯格雷码进行三维重建?2023-01-13 850
-
三维重建:从入门到入土2023-03-03 740
-
如何实现整个三维重建过程2023-09-01 957
全部0条评论

快来发表一下你的评论吧 !
