

1.1TB HBM3e内存!NVIDIA奉上全球第一GPU:可惜无缘中国
描述
NVIDIA GPU已经在AI、HPC领域遥遥领先,但没有最强,只有更强。
现在,NVIDIA又发布了全新的HGX H200加速器,可处理AIGC、HPC工作负载的海量数据。
NVIDIA H200的一大特点就是首发新一代HBM3e高带宽内存(疑似来自SK海力士),单颗容量就多达141GB(原始容量144GB但为提高良率屏蔽了一点点),同时带宽多达4.8TB/s。
对比H100,容量增加了76%,带宽增加了43%,而对比上代A100,更是容量几乎翻番,带宽增加2.4倍。
得益于NVLink、NVSwitch高速互连技术,H200还可以四路、八路并联,因此单系统的HBM3e内存容量能做到最多1128GB,也就是1.1TB。
只是相比于AMD Instinct MI300X还差点意思,后者搭载了192GB HBM3,带宽高达5.2TB/s。

性能方面,H200再一次实现了飞跃,700亿参数的Llama2大语言模型推理性能比H100提高了多达90%,1750亿参数的GTP-3模型推理性能也提高了60%,而对比前代A100 HPC模拟性能直接翻番。
八路H200系统下,FP8深度学习计算性能可以超过32PFlops,也就是每秒3.2亿亿次浮点计算,堪比一台大型超级计算机。
随着未来软件的持续升级,H200还有望继续释放潜力,实现更大的性能优势。
此外,H200还可以与采用超高速NVLink-C2C互连技术的NVIDIA Grace CPU处理器搭配使用,就组成了GH200 Grace Hopper超级芯片,专为大型HPC、AI应用而设计的计算模块。
NVIDIA H200将从2024年第二季度开始通过全球系统制造商、云服务提供商提供。
另外,NVIDIA第一次披露了下一代AI/HPC加速器的情况,架构代号Blackwell,核心编号GB200,加速器型号B100。
NVIDIA第一次公开确认,B100将在2024年发布,但未出更具体的时间表。
此前曝料称,B100原计划2024年第四季度推出,但因为AI需求太火爆,已经提前到第二季度,现已进入供应链认证阶段。
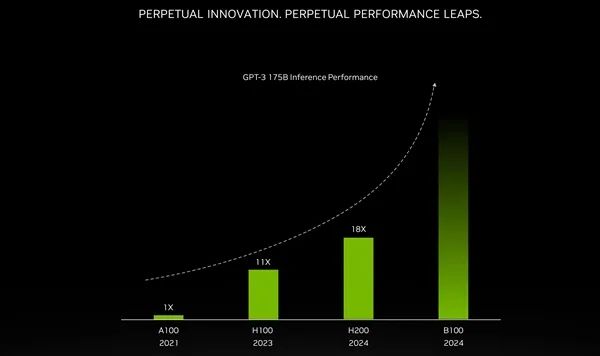
NVIDIA表示,B100加速器可以轻松搞定1730亿参数的大语言模型,是现在H200的两倍甚至更多。
虽然这不代表原始计算性能,但也足以令人望而生畏。
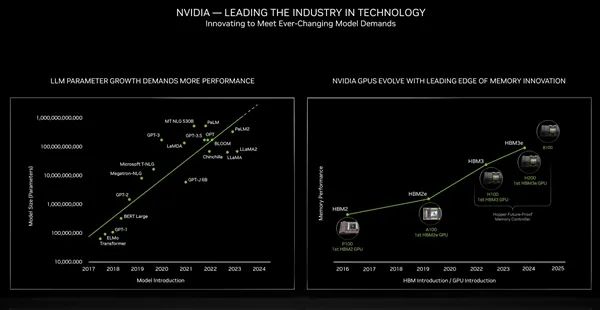
同时,B100还将带来更高级的HBM高带宽内存规格。
回顾历史,Pascal P100、Ampere A100、Hopper H100、H200分别首发应用HBM2、HBM2e、HBM3、HBM3e。
接下来的B100肯定赶不上HBM4(规范还没定呢),但必然会在堆叠容量、带宽上继续突破,大大超越现在的4.8TB/s。
Blackwell架构同时也会用于图形工作站和桌面游戏,传闻有GB202、GB203、GB205、GB206、GB207等不同核心,但是对于RTX 50系列,NVIDIA始终三缄其口,几乎肯定到2025年才会发布。
2024年就将是RTX 40 SUPER系列的天下了,明年初的CES 2025首发三款型号RTX 4080 SUPER、RTX 4070 Ti SUPER、RTX 4070 SUPER。
-
NVIDIA CPU+GPU超级芯片大升级!2023-08-10 957
-
SK海力士推全球最高性能HBM3E内存2023-08-22 607
-
HBM3E明年商业出货,兼具高速和低成本优点2023-10-10 455
-
追赶SK海力士,三星、美光抢进HBM3E2023-10-25 2227
-
英伟达大量订购HBM3E内存,抢占市场先机2023-12-29 657
-
英伟达斥资预购HBM3内存,为H200及超级芯片储备产能2024-01-02 303
-
AMD发布HBM3e AI加速器升级版,2025年推新款Instinct MI2024-02-25 179
-
三星电子成功发布其首款12层堆叠HBM3E DRAM—HBM3E 12H2024-02-27 292
-
三星发布首款12层堆叠HBM3E DRAM2024-02-27 444
-
美光新款高频宽记忆体HBM3E将被用于英伟达H2002024-02-28 191
-
美光开始量产行业领先的 HBM3E 解决方案,加速人工智能发展2024-03-04 583
-
美光量产行业领先的HBM3E解决方案,加速人工智能发展2024-03-04 784
-
SK海力士HBM3E内存正式量产,AI性能提升30倍,成本能耗降低96%2024-03-19 349
-
什么是HBM3E内存?Rambus HBM3E/3内存控制器内核2024-03-20 597
-
NVIDIA预定购三星独家供应的大量12层HBM3E内存2024-03-25 122
全部0条评论

快来发表一下你的评论吧 !
