

AI 模型构建的五个过程详解
人工智能
描述
AI 模型构建的过程 模型构建主要包括 5 个阶段,分别为模型设计、特征工程、模型训练、模型验证、模型融合。
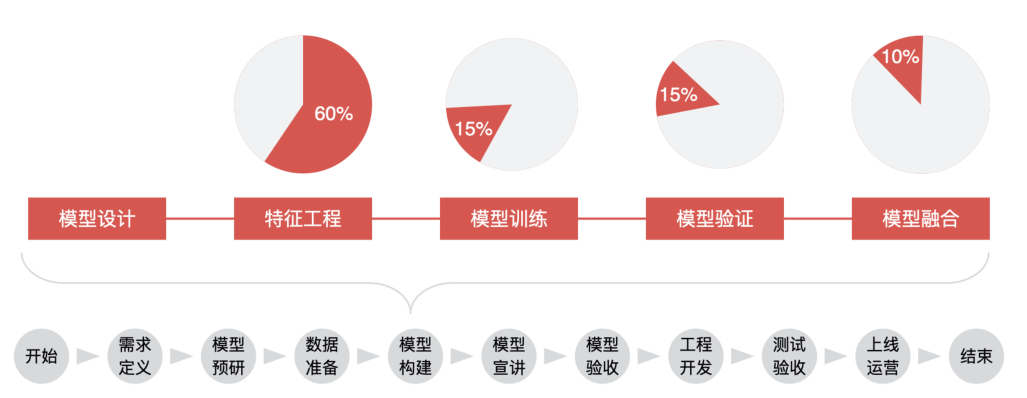
模型设计
在模型设计环节,产品经理要考虑的问题就是,在当前业务下,这个模型该不该做,我们有没有能力做这个模型,目标变量应该怎么设置、数据源应该有哪些、数据样本如何获取,是随机抽取还是分层抽样。
在模型设计阶段最重要的就是定义模型目标变量,以及抽取数据样本。
不同的目标变量,决定了这个模型应用的场景,以及能达到的业务预期。
接着,我们再来说说数据样本的抽取。模型是根据我们选择的样本来进行训练的,所以样本的选取决定了模型的最终效果。换句话说,样本是用来做模型的基础。在选取样本的时候,你需要根据模型的目标、业务的实际场景来选择合适的样本。
特征工程
我们可以把整个模型的构建理解为:从样本数据中提取可以很好描述数据的特征,再利用它们建立出对未知数据有优秀预测能力的模型。
在模型的构建过程中,特征工程是一个非常重要的部分。特征挑选得好,不仅可以直接提高模型的性能,还会降低模型的实现复杂度。
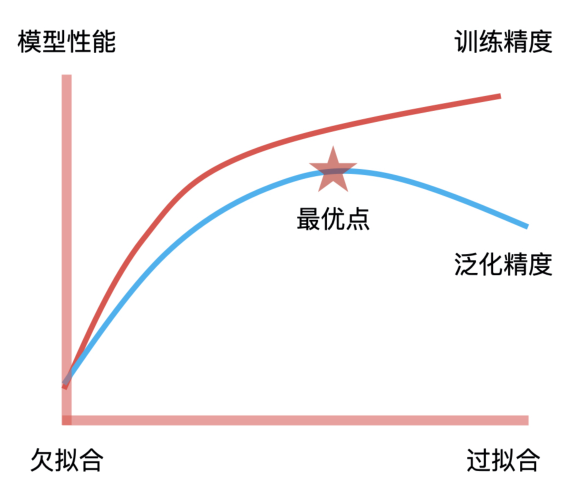
无论特征和数据过多或过少,都会影响模型的拟合效果,出现过拟合或欠拟合的情况。
当选择了优质的特征之后,即使你的模型参数不是最优的,也能得到不错的模型性能,你也就不需要花费大量时间去寻找最优参数了,从而降低了模型实现的复杂度。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
算法工程师们花费在特征工程建立上面的时间,基本上占整个模型构建的 60%。
那什么是特征工程?对一个模型来说,因为它的输入一定是数量化的信息,也就是用向量、矩阵或者张量的形式表示的信息。所以,当我们想要利用一些字符串或者其他类型的数据时,我们也一定要把它们先转换成数量化的信息。像这种把物体表示成一个向量或矩阵的过程,就叫做特征工程(Feature Engineering)。
那什么是建立特征工程呢?比较常见的,我们可以通过一个人的年龄、学历、工资、信用卡个数等等一系列特征,来表示这个人的信用状况,这就是建立了这个人信用状况的特征工程。同时,我们可以通过这些特征来判断这个人的信用好坏。
更具体点来说,建立特征工程的流程是,先做数据清洗,再做特征提取,之后是特征筛选,最后是生成训练 / 测试集。
1. 数据清洗

在建立特征工程的开始阶段,算法工程师为了更好地理解数据,通常会通过数据可视化(Data Visualization)的方式直观地查看到数据的特性,比如数据的分布是否满足线性的?数据中是否包含异常值?特征是否符合高斯分布等等。然后,才会对数据进行处理,也就是数据清洗,来解决这些数据可能存在的数据缺失、有异常值、数据不均衡、量纲不一致等问题。
数据缺失
在数据清洗阶段是最常见的问题。在遇到数据缺失问题时,算法工程师可以通过删除缺失值或者补充缺失值的手段来解决它。
至于数值异常的问题,可以选择的方法就是对数据修正或者直接丢弃,当然如果你的目标就是发现异常情况,那就需要保留异常值并且标注。
对于数据不均衡的问题,因为数据偏差可能导致后面训练的模型过拟合或者欠拟合,所以处理数据偏差问题也是数据清洗阶段需要考虑的。
针对量纲不一致的问题,也就是同一种数据的单位不同,比如金额这个数据,有的是以万元为单位,有的是以元为单位,我们一般是通过归一化让它们的数据单位统一。
2. 特征提取

一般提取出的特征会有 4类常见的形式,分别是数值型特征数据、标签或者描述类数据、非结构化数据、网络关系型数据。 数值型特征数据
数据一般包含大量的数值特征。
这类特征可以直接从数仓中获取,操作起来非常简单
一系列聚合函数也可以去描述特征,比如总次数、平均次数,当前次数比上过去的平均次数等等。
标签或描述类数据
这类数据的特点是包含的类别相关性比较低,并且不具备大小关系。
这类特征的提取方法也非常简单,一般就是将这三个类别转化为特征,让每个特征值用0、1 来表示,如有房 [0, 1]、有车 [0, 1] 等等。
非结构化数据(处理文本特征)
非结构化数据一般存在于 UGC(User Generated Content,用户生成内容)内容数据中。比如我们的用户流失预测模型用到了用户评论内容,而用户评论都是属于非结构化的文本类数据。
提取非结构化特征的一般做法就是,对文本数据做清洗和挖掘,挖掘出在一定程度上反映用户属性的特征。
网络关系型数据
前三类数据描述的都是个人,而网络关系型数据描述的是这个人和周围人的关系。
提取这类特征其实就是,根据复杂网络的关系去挖掘任意两人关系之间的强弱,像是家庭关系、同学关系、好友关系等等。
3. 特征选择

特征选择简单来说,就是排除掉不重要的特征,留下重要特征。
算法工程师会对希望入模的特征设置对应的覆盖度、IV 等指标,这是特征选择的第一步。
然后,再依据这些指标和按照经验定下来的阈值对特征进行筛选。
最后,还要看特征的稳定性,将不稳定的特征去掉。
4. 训练 / 测试集

这一步也是模型正式开始训练前需要做的,简单来说,就是算法同学需要把数据分成训练集和测试集,他们会使用训练集来进行模型训练,会使用测试集验证模型效果。
模型训练
模型训练是通过不断训练、验证和调优,让模型达到最优的一个过程。
决策边界是判断一个算法是线性还是非线性最重要的标准。
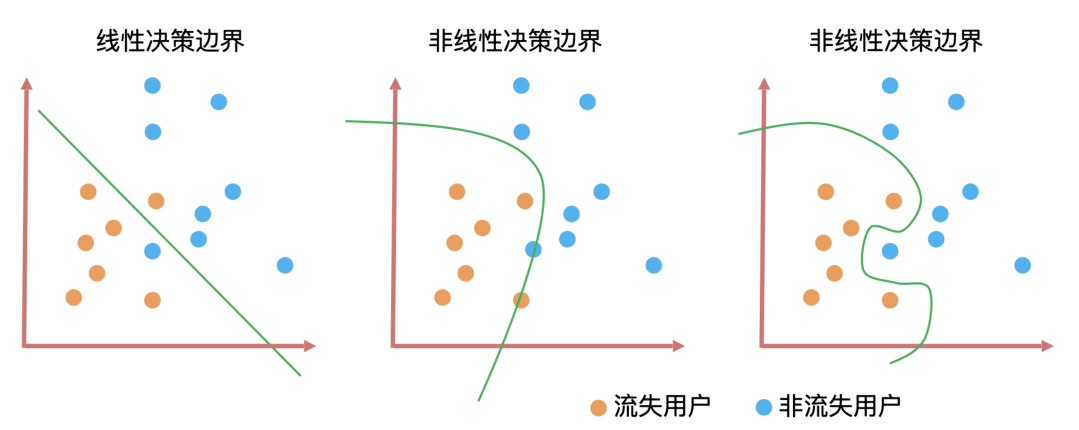
上图就是三种算法的决策边界。决策边界的形式无非就是直线和曲线两种,并且这些曲线的复杂度(曲线的平滑程度)和算法训练出来的模型能力息息相关。一般来说决策边界曲线越陡峭,模型在训练集上的准确率越高,但陡峭的决策边界可能会让模型对未知数据的预测结果不稳定。
模型训练的目标就是找到拟合能力与泛化能力的平衡点。拟合能力代表模型在已知数据上表现得好坏,泛化能力代表模型在未知数据上表现得好坏。它们之间的平衡点,就是我们通过不断地训练和验证找到的模型参数的最优解,因此,这个最优解绘制出来的决策边界就具有最好的拟合和泛化能力。这是模型训练中“最优”的意思,也是模型训练的核心目标。
一般情况下,算法工程师会通过交叉验证(Cross Validation)的方式,找到模型参数的最优解。
模型验证
模型验证主要是对待验证数据上的表现效果进行验证,一般是通过模型的性能指标和稳定性指标来评估。 模型性能 可以理解为模型预测的效果,你可以简单理解为“预测结果准不准”,它的评估方式可以分为两大类:分类模型评估和回归模型评估 。
分类模型评估
分类模型解决的是将一个人或者物体进行分类,例如在风控场景下,区分用户是不是“好人”,或者在图像识别场景下,识别某张图片是不是包含人脸。对于分类模型的性能评估,我们会用到包括召回率、F1、KS、AUC 这些评估指标。
回归模型评估
回归模型解决的是预测连续值的问题,如预测房产或者股票的价格,所以我们会用到方差和 MSE 这些指标对回归模型评估。 对于产品经理来说,我们除了要知道可以对模型性能进行评估的指标都有什么,还要知道这些指标值到底在什么范围是合理的。虽然,不同业务的合理值范围不一样,我们要根据自己的业务场景来确定指标预期,但我们至少要知道什么情况是不合理的。 模型稳定性 我们可以使用 PSI 指标来判断模型的稳定性,如果一个模型的 PSI > 0.2,那它的稳定性就太差了,这就说明算法同学的工作交付不达标。
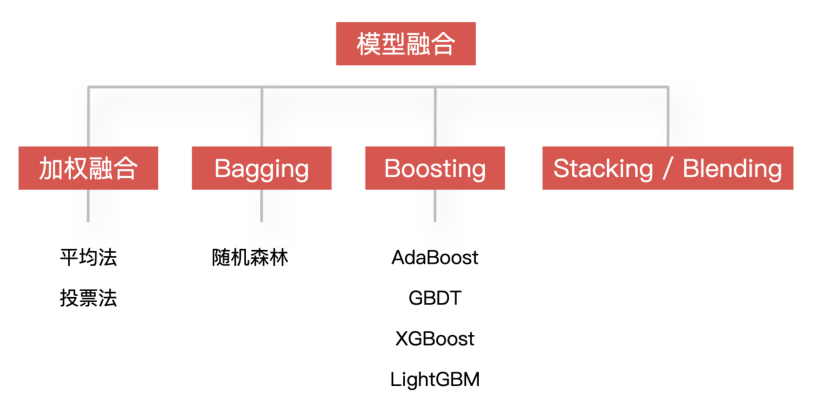
模型融合
同时训练多个模型,再通过模型集成的方式把这些模型合并在一起,从而提升模型的准确率。简单来说,就是用多个模型的组合来改善整体的表现。
模型部署
一般情况下,因为算法团队和工程团队是分开的两个组织架构,所以算法模型基本也是部署成独立的服务,然后暴露一个 HTTP API 给工程团队进行调用,这样可以解耦相互之间的工作依赖,简单的机器学习模型一般通过 Flask 来实现模型的部署,深度学习模型一般会选 TensorFlow Serving 来实现模型部署。
编辑:黄飞
-
使用cube-AI分析模型时报错的原因有哪些?2024-03-14 0
-
防止AI大模型被黑客病毒入侵控制(原创)聆思大模型AI开发套件评测42024-03-19 0
-
AI大模型可以设计电路吗?电子发烧友网官方 2024-01-02
-
AI大模型怎么解决芯片过剩?电子发烧友网官方 2024-01-02
-
AI大模型可以取代大学教育吗?电子发烧友网官方 2024-01-02
-
了解AI人工智能背后的科学?2017-09-25 0
-
Hexagon SDK之Audio APPI详解2018-09-20 0
-
【AI学习】AI概论:(Part-A)与AI智慧交流2020-10-30 0
-
如何构建词向量模型?2021-11-10 0
-
AI算法中比较常用的模型都有什么?2022-08-27 0
-
嵌入式边缘AI应用开发指南2022-11-03 0
-
【KV260视觉入门套件试用体验】Vitis AI 构建开发环境,并使用inspector检查模型2023-10-14 0
-
【KV260视觉入门套件试用体验】Vitis AI 进行模型校准和来量化2023-10-15 0
-
NVIDIA联合构建大规模模拟和训练 AI 模型2022-06-14 1564
全部0条评论

快来发表一下你的评论吧 !
