

基于Transformer的可泛化人体表征设计方案
描述
作者:潘啸,论文第一作者
0. 笔者前言
可泛化人体重建旨在在多个人体视频上进行预训练,学习可泛化的重建先验。在测试阶段,给定新人物的稀疏视角参考图,在无需微调或者训练的情况下,可直接输出新视角。以往方法大部分使用基于稀疏卷积(SparseConvNet)的人体表征方式,然而,一方面,稀疏卷积有限的感受野导致其对人体的自遮挡十分敏感,另一方面,其输入为不断变化的观察空间姿势下的人体,导致训练和推理阶段的姿势不匹配问题,降低了泛化能力。
不同于此,本文工作TransHuman使用Transformer围绕SMPL表面构建了人体部位之间的全局联系,并且将输入统一在标准姿势下,显著的提升了该表征的泛化能力。在多个数据集上达到了新SOTA的同时,具有很高的推理效率。
本文专注于可泛化人体重建任务。为了处理动态人体的运动和遮挡,之前方法主要采用了基于稀疏卷积的人体表征。然而,该表征方式1)在多变的观察姿势空间进行优化,导致训练与测试阶段输入姿势不一致,从而降低泛化性; 2)缺少人体部位之间的全局联系,从而导致对人体的遮挡敏感。为了解决这两个问题,我们提出了一个新的框架TransHuman。TransHuman在标准姿势空间进行优化, 并且使用Transformer构建了人体部位之间的联系。具体来讲,TransHuman由三个部分组成:基于Transformer的人体编码(TransHE), 可形变局部辐射场(DPaRF), 以及细粒度整合模块 (FDI). 首先,TransHE在标准空间使用Transformer处理SMPL;然后,DPaRF将TransHE输出的每个Token视为一个可形变的局部辐射场来获得观察空间下某一查询点的特征。最后,FDI进一步从参考图中直接收集细粒度的信息。本文在ZJU-MoCap及H36M上进行大量实验,证明了TransHuman的泛化性显著优于之前方法,并具有较高的推理效率。
4. 算法解析
Pipeline概览 / 研究背景
TransHuman的pipeline如图4所示。整个pipeline可以抽象为:给定空间中一个查询点(Query Point),我们需要从多视角参考图中提取一个对应的 条件特征(Condition Feature) 输入NeRF,从而实现泛化能力(详细可参考PixelNeRF)。而条件特征主要由两部分组成:表面特征(Appearance Feature)及人体表征(Human Representation)。
表面特征:该特征可由将查询点通过相机参数进行反向投影后在参考图中进行插值得到,其直接反应参考图中的原始RGB信息,因此属于细粒度信息。但由于其缺少人体几何先验信息,仅使用此特征会导致人体几何的崩塌(详见Paper原文实验部分);
人体表征:为获得人体表征,首先通过现有的SMPL估计方法,从视频中拟合出一个SMPL模版(Fitted SMPL,数据集一般自带)。然后对于SMPL的每一个顶点,将其反向投影到参考图得到该顶点对应的CNN Feature,就得到了着色之后的SMPL(Painted SMPL)。从着色之后的SMPL提取出来的特征便是人体表征。人体表征包含了人的几何先验,因此在pipeline中起着关键作用,也是本文的研究重点。
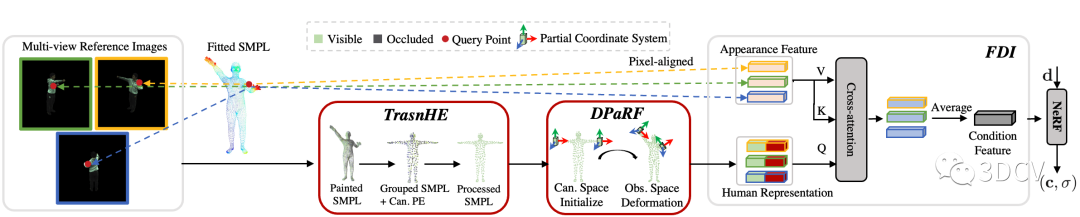
图4:Pipeline概览图
研究动机
之前的方法主要利用稀疏卷积(SparseConvNet) 来得到人体表征 ,如图5上半部分所示。该方法主要有两个问题:
多变的输入姿势问题。 稀疏卷积的输入为观察姿势下的SMPL,也就是说其输入的姿势会随着帧数的变化而变化。这导致了训练和推理阶段的输入姿势不一致问题(推理阶段的人的姿势可能是各种各样的),从而极大的增加了泛化的难度。
局部感受野问题。 由于我们所能获取的参考图往往是十分稀疏的(本文默认采用3个视角),所以着色之后的SMPL通常包含大量的被遮挡部分。而另一方面,稀疏卷积本质是3D卷积,其感受野比较有限,从而导致无法进行人体部位之间的全局的推理。具体举例来说,假设人的左手是可见的而右手是被遮挡的,如果有全局之间的关系,那么网络理论上可以推断出右手被遮挡的部分大概是什么样。基于此直觉,我们认为在人体不同部位之间构建全局关系是很重要的。
为了解决以上两个问题,我们提出了本文关键的两个创新点(如图5下半部分所示),即:
用Transformer在SMPL表面之间构建全局关系,即TransHE部分。
将网络输入先统一在标准空间(比如T-pose的SMPL),然后将输出通过SMPL形变的方式转化回观察姿势进行特征提取,即DPaRF部分。
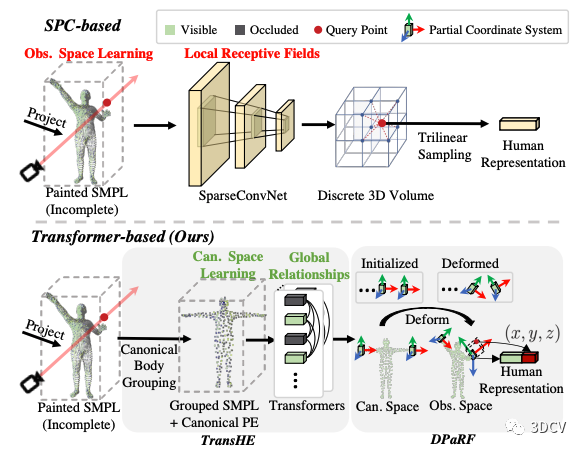
图5:研究动机。SPC-base (Previous) vs. Transformer-based (Ours)。
基于Transformer的人体编码 (TransHE)
接下来我们详细介绍TransHE的细节。
如图7左下角所示,TransHE模块的输入是Painted SMPL (6890 x d1,d1为CNN feature的维度)。一种直接的做法是将6890个Token输入Transformer(本文使用ViT-Tiny),然而这种做法:
会带来巨大的计算开销。
会引入细粒度误差(Fitted SMPL只是人体的粗略模版而不包含衣物等细节,因此其着色本身也存在一定的误差)。
基于这两个问题,我们需要降低输入Transformer的Token数量。
一种非常直接的想法是对Painted SMPL进行grid voxelization,即,将空间均匀划分为一个个小方块,在同一个方块内的顶点取平均算做一个Token,同时把方块中心作为Token对应的PE。但由于Painted SMPL是在观察姿势下的,而观察姿势随着输入帧的变化而变化,这就导致每次输入ViT的Token数量以及PE都在变化,使得优化变得十分困难,而且会将不同语义部分划分到同一个Token。图6举了一个人移动右手的例子,在这种情况下,grid voxelization对点的划分会随着姿势的变化而变化,并且将左手和右手的顶点划分在了同一个Token,这显然不是我们所希望的。
为了进一步解决这个问题,我们提出先对标准姿势SMPL(本文使用T-pose)进行K-Means聚类(本文默认聚300类)得到一个分组的字典。然后用该字典对Painted SMPL进行划分,同一类的特征取均值作为Token,同时将标准姿势SMPL下的聚类中心作为PE输入ViT。这样一来,Token数量和PE便不再受观察姿势的影响,极大的降低了学习的难度,如图6右侧所示。
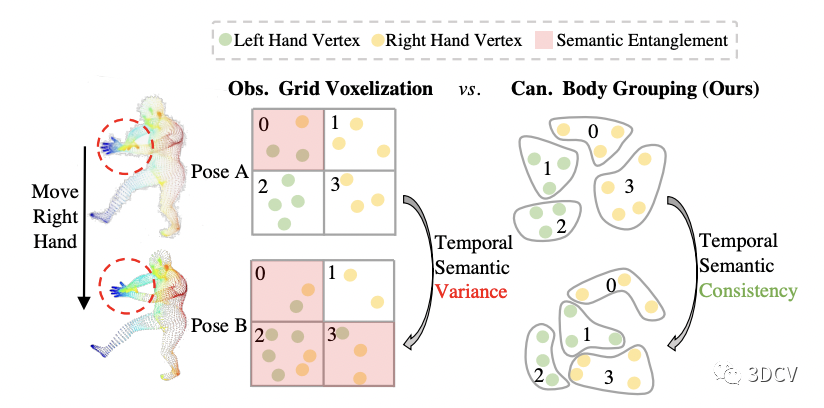
图6:简单的Grid Voxelization划分方式(左) vs. 我们的划分方式(右)。
可形变局部辐射场 (DPaRF)
由于我们在TransHE模块将输入统一在了标准姿势,而我们最终需要的是观察姿势 下给定查询点 对应的特征,因此,我们需要将TransHE的输出变回到观察姿势。这里我们的思路是,为每个Token(对应一个身体部位)维护一个局部辐射场,且该辐射场的坐标系随着观察姿势 一起旋转,如图7右下角所示。
然后对于每一个查询点, 我们将其分配到距离最近的K个局部辐射场。对于每个局部辐射场,我们将Token与该场下的局部坐标进行拼接得到该场下的人体表征。最终的人体表征 则是这K个场的所有人体表征的加权和(根据距离加权)。
细粒度整合模块 (FDI)
通过TransHE和DPaRF, 我们已经得到了给定查询点的人体表征,该表征包含了粗粒度的人体几何先验信息。接下来,和之前的工作类似,我们使用一个Cross-attention模块,将粗粒度的人体表征 视作Q,细粒度的表面特征 视为K和V,得到最终的条件特征。
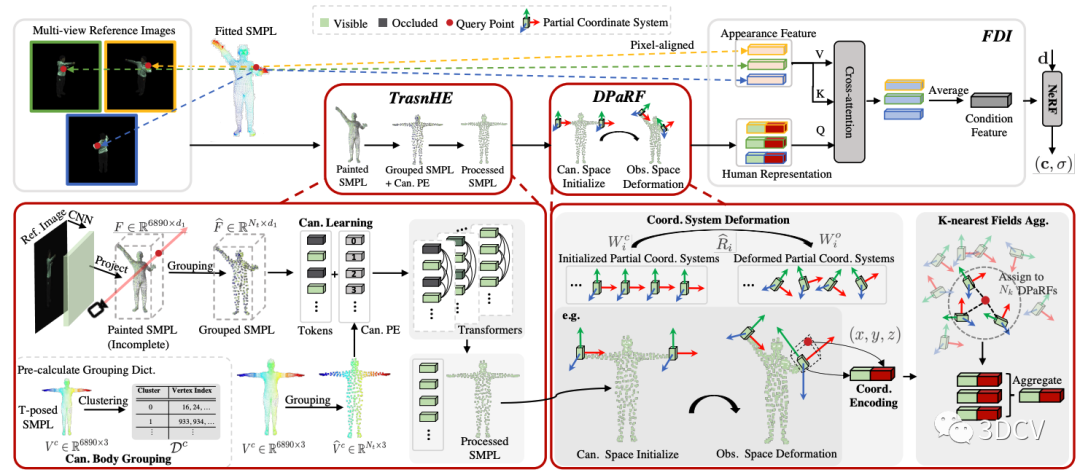
图7:Pipeline细节图。
5. 实验结果
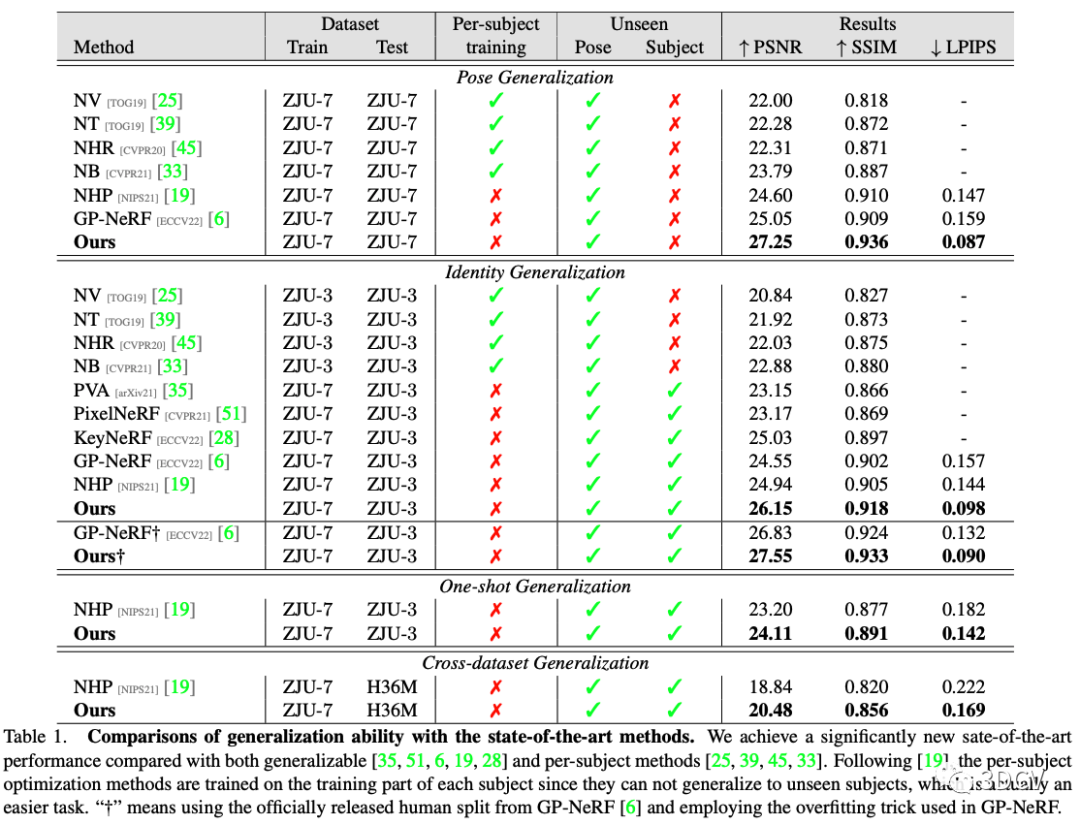
本文在ZJU-MoCap和H36M上进行了泛化性实验,结果如下图所示。主要分为四个setting: Pose的泛化,Identity的泛化,只给一张参考图的泛化,以及跨数据集的泛化。在四个setting上均显著高于之前方法,达到了新的SOTA。
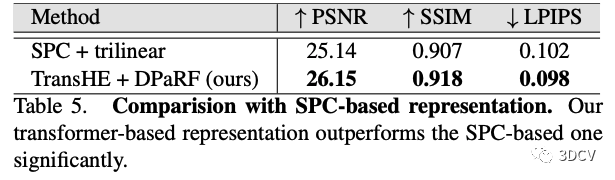
同时,作者还给出了在其代码中直接将TransHE + DPaRF模块替换成原来的SPC-based方法,以争取尽量公平的对比。结果如下图所示,本文方法仍明显领先。
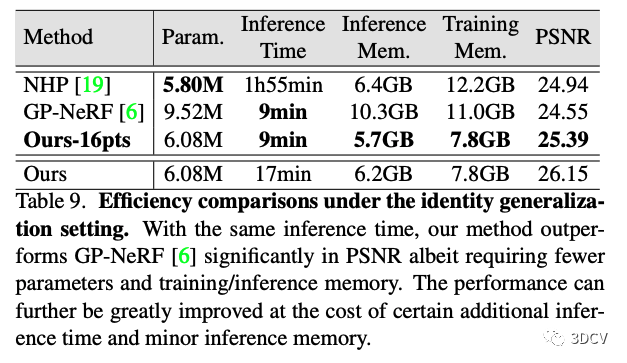
另外,作者对本文方法的效率也给出了分析。在使用相同推理时间的情况下,本文方法性能仍然明显高于之前的方法,并且推理消耗的内存更小。可见本文方法具有比较高的推理效率。
更多详细的Ablation以及可视化推荐大家阅读原文及观看项目主页的视频DEMO。
6. 总结
本文为可泛化人体重建领域引入了一种新的基于Transformer的人体表征。该表征在人体部件之间构建了全局关系,并将优化统一在了标准姿势下。其泛化性能明显优于先前的基于稀疏卷积的表征,而且具有比较高的推理效率,为后续可泛化人体重建的研究提供了一个新的更高效的模块。
审核编辑:黄飞
- 相关推荐
- Transformer
-
智能人体心率检测装置的设计方案2010-04-20 1679
-
眼科超声波诊断仪的设计方案2009-11-30 0
-
小区智能化系统设计方案2012-08-18 0
-
笨人的创意,创意智能插座设计方案,绝对可实现2014-09-07 0
-
品佳:适用于家庭智能照明的无线控制设计方案2015-01-28 0
-
大神求助tps333热电堆传感器为主的人体表面温度检测电路2015-04-08 0
-
ABBYY FineReader 和 ABBYY PDF Transformer+功能比对2017-09-01 0
-
如何更改ABBYY PDF Transformer+界面语言2017-10-11 0
-
AMEYA360设计方案丨人体感应灯2018-05-08 0
-
ARM海思行人检测/行人识别/人体检测/人体识别解决方案2018-06-14 0
-
STM32设计方案与示例分享2018-09-03 0
-
分享一款不错的基于LM358的人体感应灯电路设计方案2021-04-14 0
-
医疗电子相关的设计方案2021-08-06 0
-
应用案例 I 人体及医用红外热像仪检测校准系统方案2023-04-04 621
全部0条评论

快来发表一下你的评论吧 !
