

Lambda数据架构和Kappa数据架构——构建现代数据架构
描述
如何更好地构建我们的数据处理架构,如何对IT系统中的遗留问题进行现代化改造并将其转变为现代数据架构?该怎么为你的需求匹配最适合的架构设计呢,本文将分析两种最流行的基于速度的数据架构,为你提供一些思路。
文章速览:
什么是数据架构?
基于速度的数据架构
Lambda数据架构
Kappa数据架构
探索数据流模型
结语
一、什么是数据架构?
数据架构是企业架构中的一个元素,继承了企业架构的主要属性:流程、策略、变更管理和评估权衡。根据Open Group架构框架,数据架构是对“企业主要数据类型、来源、逻辑数据资产、物理数据资产和数据管理资源的结构和交互” 的描述。
根据数据管理知识体系,数据架构是“识别企业的数据需求(无论结构如何)并设计和维护核心蓝图以满足这些需求”的过程。它使用核心蓝图来指导数据集成、控制数据资产并使数据投资与业务战略保持一致。
然而,糟糕的数据架构是僵化且过度集中的。它使用了错误的工具来完成工作,这阻碍了开发和变更管理。
二、基于速度的数据架构
数据速度是指数据生成的速度、数据移动的速度以及将其处理为可用指导的速度。
根据处理数据的速度,数据架构通常分为两类:Lambda和Kappa。
Lambda数据架构✦
1.什么是Lambda
Lambda数据架构由Apache Storm的创建者Nathan Marz于 2011 年开发,旨在解决大规模实时数据处理的挑战。术语 Lambda 源自lambda演算 (λ),描述了在多个节点上并行运行分布式计算的函数。Lambda数据架构提供了一个可扩展、容错且灵活的系统来处理大量数据。它允许以混合方式访问批处理和流处理方法。
2.Lambda架构的使用场景
1)当您有各种工作负载和速度要求时,Lambda架构是理想的选择。由于它可以处理大量数据并提供低延迟查询结果,因此适合仪表板和报告等实时分析应用程序。Lambda架构对于批处理(清理、转换、数据聚合)、流处理任务(事件处理、开发机器学习模型、异常检测、欺诈预防)以及构建集中存储库(称为“数据湖”)非常有用。
2)Lambda架构的关键区别在于,它使用两个独立的处理系统来处理不同类型的数据处理工作负载。第一个是批处理系统,它将结果存储在集中式数据存储(例如数据仓库或数据湖)中。第二个系统是流处理系统,它在数据到达时实时处理数据并将结果存储在分布式数据存储中。
3.Lambda架构的组成
Lambda架构由摄取层、批处理层、速度层(或流层)和服务层组成。
· 批处理层:批处理层处理大量历史数据并将结果存储在集中式数据存储中,例如数据仓库或分布式文件系统。该层使用Hadoop或Spark等框架进行高效的数据处理,使其能够提供所有可用数据的总体视图。
· 速度层:速度层处理高速数据流,并使用Apache Flink或Apache Storm等事件处理引擎提供最新的信息视图。该层处理传入的实时数据并将结果存储在分布式数据存储中,例如消息队列或NoSQL数据库。
· 服务层:无论底层处理系统如何,Lambda架构服务层对于为用户提供一致的数据访问体验至关重要。它在支持需要快速访问当前信息(例如仪表板和分析)的实时应用程序方面发挥着重要作用。
4.Lambda架构的使用场景
Lambda架构解决了计算任意函数的问题,系统必须评估任何给定输入的数据处理函数(无论是慢动作还是实时)。此外,它还提供容错功能,确保在一个系统出现故障或不可用时,任一系统的结果都可以用作另一个系统的输入。在高吞吐量、低延迟和近实时应用程序中,这种架构的效率是很明显的。

Lambda架构示意图
5、Lambda架构的缺点
Lambda架构提供了许多优势,例如可扩展性、容错性以及处理各种数据处理工作负载(批处理和流)的灵活性。但它也有缺点:
· Lambda架构很复杂,它使用多种技术堆栈来处理和存储数据。
· 设置和维护可能具有挑战性,尤其是在资源有限的组织中。
· 每个阶段的批处理和速度层中都会重复底层逻辑。这种重复有一个代价:数据差异。因为尽管具有相同的逻辑,但一层与另一层的实现不同。因此,错误/错误的概率较高,并且您可能会遇到批处理层和速度层的不同结果。
Kappa数据架构✦
2014年,Jay Kreps指出了Lambda架构的一些缺点。这次讨论使大数据社区找到了一种使用更少代码资源的替代方案——Kappa数据架构。
1、什么是Kappa数据架构
Kappa(以希腊字母 ϰ 命名,在数学中用于表示循环)背后的主要思想是单个技术堆栈可用于实时和批量数据处理。该名称反映了该体系结构对连续数据处理或再处理的重视,而不是基于批处理的方法。
Kappa 的核心依赖于流式架构。传入数据首先存储在事件流日志中。然后,它由流处理引擎(例如 Kafka)连续实时处理或摄取到另一个分析数据库或业务应用程序中。这样做需要使用各种通信范例,例如实时、近实时、批处理、微批处理和请求响应等。
2、Kappa数据架构的组成
数据重新处理是 Kappa的一项关键要求,使源端的任何更改对结果的影响可见。因此,Kappa 架构仅由两层组成:流处理层和服务层。
在Kappa架构中,只有一层处理层:流处理层。该层负责采集、处理和存储直播数据。这种方法消除了对批处理系统的需要。相反,它使用先进的流处理引擎(例如 Apache Flink、Apache Storm、Apache Kafka 或 Apache Kinesis)来处理大量数据流并提供对查询结果的快速、可靠的访问。
流处理层有两个组件:
· 摄取组件:该层从各种来源收集传入数据,例如日志、数据库事务、传感器和 API。数据被实时摄取并存储在分布式数据存储中,例如消息队列或NoSQL数据库。
· 处理组件:该组件处理大量数据流并提供对查询结果的快速可靠的访问。它使用事件处理引擎(例如 Apache Flink 或 Apache Storm)来实时处理传入数据和历史数据(来自存储区域),然后将信息存储到分布式数据存储中。
对于几乎所有用例,实时数据都胜过非实时数据。尽管如此,Kappa架构不应该被视为 Lambda 架构的替代品。反之,在不需要批处理层的高性能来满足标准服务质量的情况下,您应该考虑 Kappa架构。
3、Kappa架构的优势
Kappa架构旨在提供可扩展、容错且灵活的系统,用于实时处理大量数据。它使用单一技术堆栈来处理实时和历史工作负载,并将所有内容视为流。Kappa 架构的主要动机是避免为批处理层和速度层维护两个独立的代码库(管道)。这使得它能够提供更加精简的数据处理管道,同时仍然提供对查询结果的快速可靠访问。
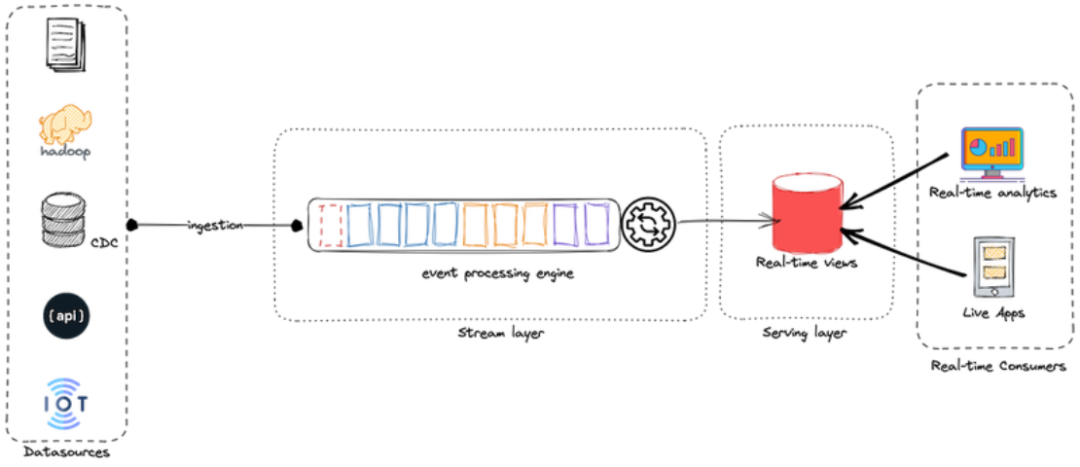
Kappa架构示意图
4、Kappa架构的缺点
Kappa架构承诺可扩展性、容错性和简化的管理。然而,它也有缺点。
· Kappa架构理论上比 Lambda更简单,但对于不熟悉流处理框架的企业来说,技术上仍然可能很复杂。
· 扩展事件流平台时的基础设施成本。在事件流平台中存储大量数据可能成本高昂,并会引发其他可扩展性问题,尤其是当数据量达到TB或PB级时。
· 事件时间和处理时间之间的滞后不可避免地会产生数据延迟。因此,Kappa 架构需要一套机制来解决这个问题,例如水印、状态管理、重新处理或回填。
探索数据流模型✦
1、为什么会出现数据流模型
Lambda和Kappa试图通过集成本质上不兼容的复杂工具来克服2010年代Hadoop生态系统的缺点。这两种方法都难以解决协调批处理和流数据的根本挑战。然而,Lambda和Kappa 为进一步的改进提供了灵感和基础。
统一多个代码路径是管理批处理和流处理的一项重大挑战。即使有了Kappa架构的统一队列和存储层,开发人员也需要使用不同的工具来收集实时统计数据并运行批量聚合作业。今天,他们正在努力应对这一挑战。
2、什么是数据流模型
数据流模型的基本前提是将所有数据视为事件并在不同类型的窗口上执行聚合。实时事件流是无界数据,而批量数据是具有自然窗口的有界事件流。
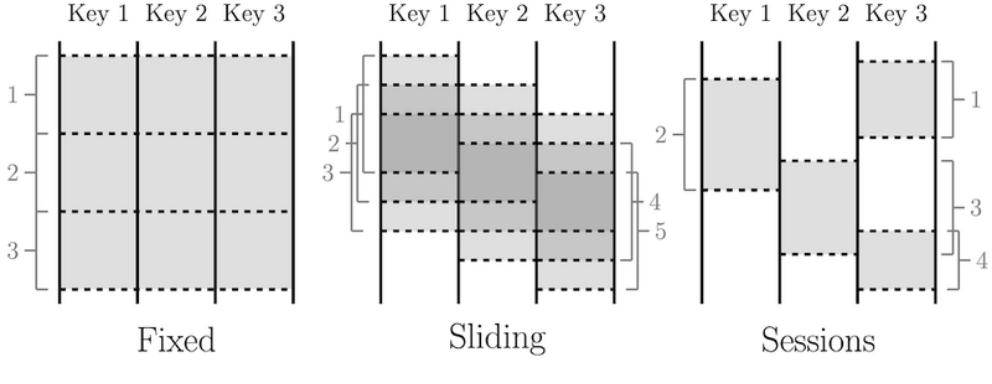
窗口模式示意图
数据工程师可以选择不同的窗口,例如滑动窗口或会话窗口,以进行实时聚合。数据流模型允许使用几乎相同的代码在同一系统内进行实时和批处理。
“批处理作为流处理的一个特例”的想法已经变得越来越普遍,Flink和Spark等框架也采用了类似的方法。
结语
当然,关于速度模型的数据架构讨论还有另一个用处:适合物联网 (IoT) 的设计选择,在本篇文章中,我们就不再赘述。如何最好地构建我们处理数据的架构,如何对僵化且缓慢的IT遗留系统,进行现代化改造并将其转变为现代数据架构,显然,关于这个问题还尚未有定论。欢迎与我们共同探讨。
-
基于阿里云数加MaxCompute的企业大数据仓库架构建设思路2018-03-15 0
-
大数据时代数据库-云HBase架构&生态&实践2018-05-29 0
-
图解大数据处理架构2019-05-09 0
-
数据基础架构的未来2019-07-29 0
-
ARM架构的数据类型定义是什么2021-10-09 0
-
下一代数据包处理技术架构选择2010-12-01 1020
-
大数据操作系统转型分析smack堆栈2017-09-30 572
-
美创科技发布新一代数据安全架构,护航千行百业数字时代2020-10-28 1530
-
各种典型的数据中台架构2022-04-24 5089
-
高性能领导力:为下一代数据中心和汽车架构提供动力2023-07-14 129
-
用于亿级实时数据分析Lambda架构分析2023-07-15 242
-
湖仓一体:揭秘数据湖架构现代化之道2023-07-17 361
-
什么是数据架构,如何理解数据架构?2023-11-15 752
-
Lambda数据架构和Kappa数据架构——构建现代数据架构2023-11-15 269
全部0条评论

快来发表一下你的评论吧 !
