

基于RGM的鲁棒且通用的特征匹配
描述
作者:泡椒味的口香糖
0. 笔者个人体会
特征匹配包括稀疏匹配和稠密匹配,这方面的深度模型这两年很多了,效果也都很好。但是同时实现稀疏匹配和稠密匹配的通用模型还比较少,主要是因为联合训练会引入大量噪声,模型架构不好设计。而且相关的训练数据不好找,直接把几个数据集堆一起训练又会出现各种各样的域问题。
最近,浙大就开源了一项工作,以一个通用模型同时实现稀疏匹配和稠密匹配。笔者认为,这篇文章的意义不是提出了一个最新的匹配模型,而在于通用模型的设计+训练思路。学习了这种思路,就可以将这种框架泛化到其他任务上。
1. 效果展示
浙大最新发布的RGM实现了一个通用模型,具体效果是同时实现稠密匹配和稀疏匹配。这里面的稠密匹配也就是光流匹配,还可以根据匹配关系投影RGB图像做两视角重建。
与其他SOTA方法相比,RGM估计的光流更细腻,边缘更完整。
目前这篇文章已经开放了github,但是暂时代码还没有开源,感兴趣的小伙伴可以跟踪一下。下面来看一下具体的论文信息。
2. 摘要
在一对图像中寻找匹配的像素是具有各种应用的基本计算机视觉任务。由于光流估计和局部特征匹配等不同任务的特定要求,以前的工作主要分为稠密匹配和稀疏特征匹配,侧重于特定的体系结构和特定任务的数据集,这可能在一定程度上阻碍了特定模型的泛化性能。在本文中,我们提出了一个稀疏和稠密匹配的深度模型,称为RGM (鲁棒通用匹配)。特别地,我们精心设计了一个级联的GRU模块,通过在多个尺度上迭代地探索几何相似性来进行细化,然后使用一个附加的不确定性估计模块来进行稀疏化。为了缩小合成训练样本和真实世界场景之间的差距,我们通过以更大的间隔生成光流监督,来构建具有稀疏匹配真值的新的大规模数据集。因此,我们能够混合各种稠密和稀疏匹配数据集,显著提高训练多样性。通过在大规模混合数据上以两阶段的方式学习匹配和不确定性估计,我们提出的RGM的泛化能力得到了极大的提高。跨多个数据集的zero-shot匹配和下游几何估计实现了卓越的性能,大大超过了以前的方法。
3. 算法解析
RGM这篇文章的目的是要设计一个统一的框架来同时实现稠密匹配和稀疏匹配,但本身两个任务的特性不同,直接设计多任务网络效果不好。所以作者的思想就很巧妙,先设计一个光流稠密匹配网络,再紧跟一个稀疏化网络。
整个Pipeline很直观,可以分成特征提取、稠密匹配、稀疏化三个部分。首先将输入图像利用CNN和Transformer提取特征金字塔,然后使用级联GRU的网络进行稠密匹配,之后通过不确定性估计来过滤得到稀疏匹配,匹配结果就可以直接用于位姿估计、两视角重建等下游任务。
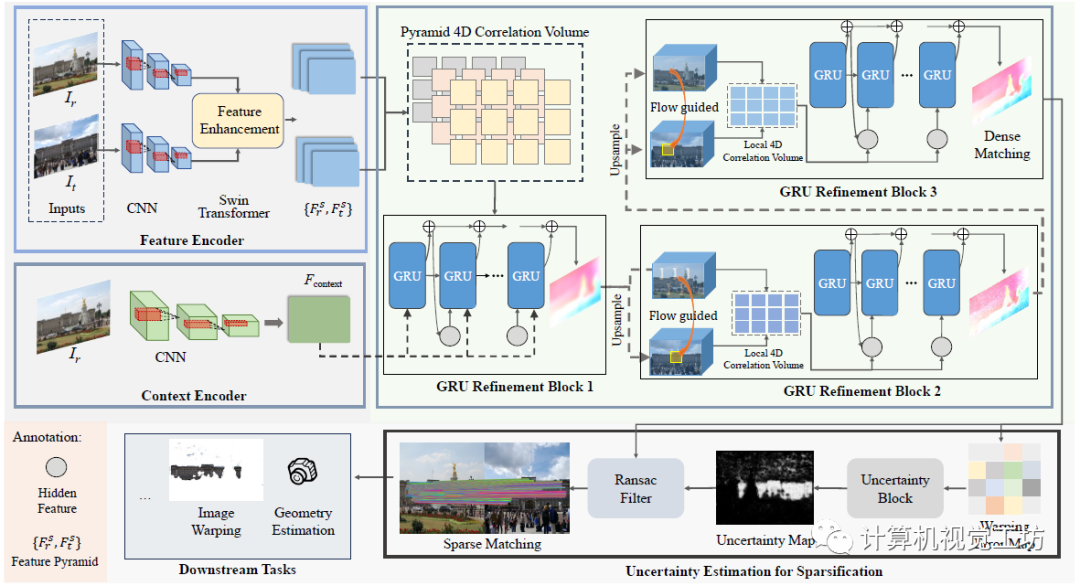
这里面还有几个细节需要注意:
1、为什么要提取特征金字塔,而不是使用某个特征层?
虽然感受野更大,但在1/8分辨率下会损失很多细节。作者这里使用的是{1/8,1/4,1/2}分辨率的三层金字塔,其中前两层使用Swin-Transformer的自我注意和交叉注意进行特征增强。
2、这个GRU模块是啥?
这里也是一个trick,就是不在每个尺度上都建立图像对的关联,而在金字塔的两个底层建立局部关联。对于1/8的低分辨率层执行点积运算:
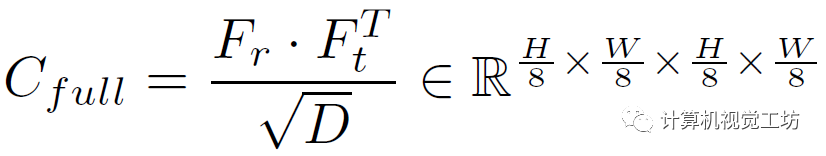
其中Fr和Ft是特征金字塔,D是维度。然后再用平均池化作为RAFT来构建相关金字塔,给定当前的光流估计f和半径r,就可以构建两个高分辨率的特征融合计算:
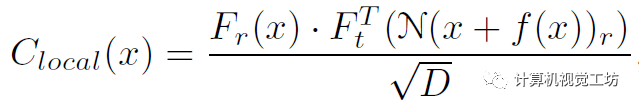
给定相关性和上下文信息,就可以估计运动信息并将其馈送给GRU优化光流残差,然后迭代得优化光流:
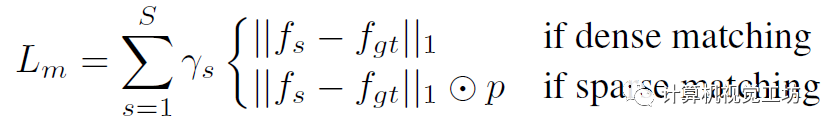
3、稀疏化如何实现?
在获得稠密匹配之后,可以直接冻结匹配网络并开始稀疏化。根据估计出的光流可以warp特征图和RGB图计算差异。然后将差值送给CNN计算损失,具体是根据mask真值计算的二进制交叉熵:
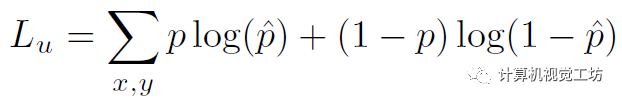
4、为什么要解耦训练?
具体训练过程是先训练匹配网络,然后冻结这部分,再单独训练稀疏化网络。作者认为直接联合训练的话,会引入大量噪声,导致光流预测不准确。
4. 实验
RGM的训练分匹配学习+不确定学习两阶段进行,也就是所谓的解耦训练。
在匹配学习阶段,首先使用带稀疏匹配真值的MegaDepth(1.4 M对图像)来训练(200k次迭代),然后使用ScanNet+FlyingThings3D+TartanAir+MegaDepth的混合数据集(4 M对图像)进行增强学习(240k次迭代)。Batch size为16,学习率从2e-4余弦退火至1e-5。在不确定学习阶段,直接冻结稠密匹配网络的参数。在MegaDepth和ScanNet上训练了2个epoch,batch size为4,学习率固定1e-4。注意,为了平衡不同数据集之间的差异,还对TartanAir进行了大间距采样。
评估也是一个零样本泛化实验。匹配估计使用ETH3D+HPatches+KITTI+TUM数据集,位姿估计(下游任务)使用TUM+YFCC数据集,光流估计使用Sintel数据集。
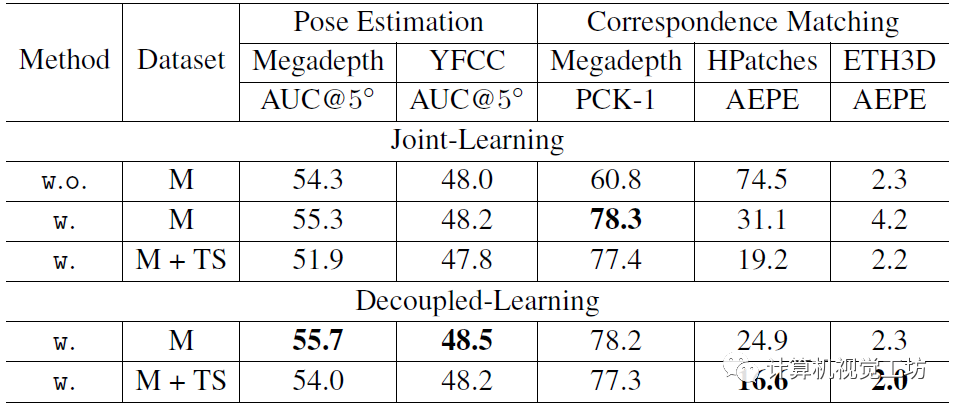
首先是解耦训练和联合训练的对比,证明他们做提出的解耦训练是有效的。看到这里笔者也有个疑问,有的模型是联合训练效果更好,有的模型却是解耦训练更好,希望有小伙伴能传授一下经验。
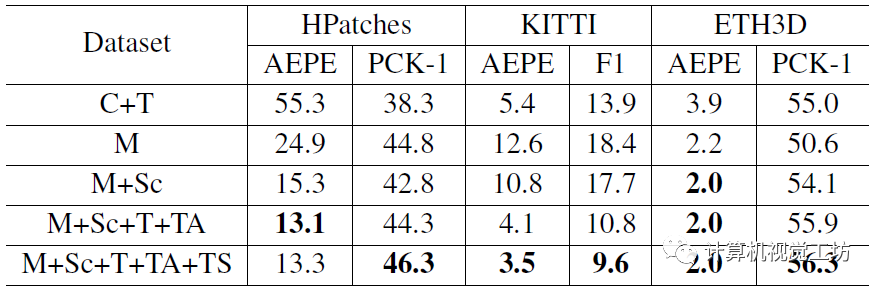
训练使用数据集的对比,显然使用的数据集越多效果越好。
特征匹配最直观的定性对比,相同颜色代表预测的匹配关系。相较于之前的SOTA方法可以取得更多的匹配关系,而且语义预测也更好(大部分匹配关系都集中在摩托车和人上)。
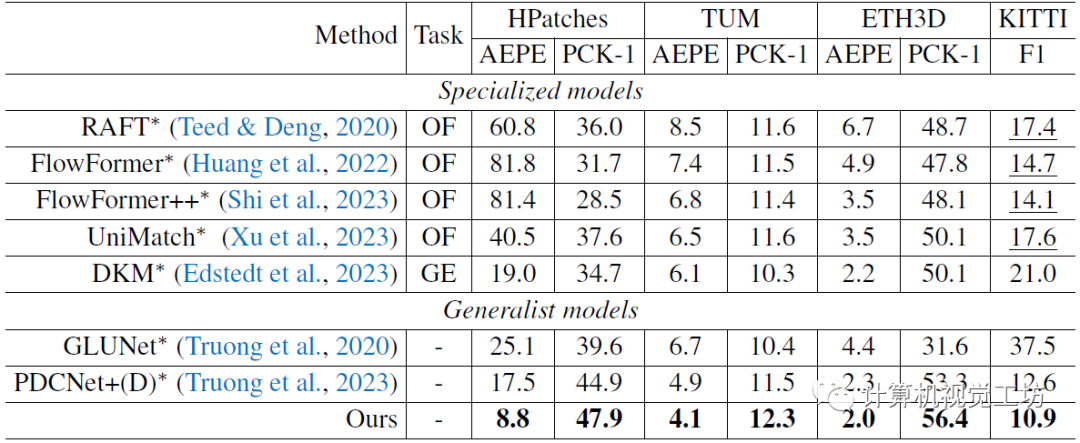
光流估计的对比,也是一个zero-shot实验。对比方案包括光流专用模型、稠密几何估计方法,还有通用匹配模型,RDM效果最优。这里也推荐「3D视觉工坊」新课程如何学习相机模型与标定?(代码+实战)》。
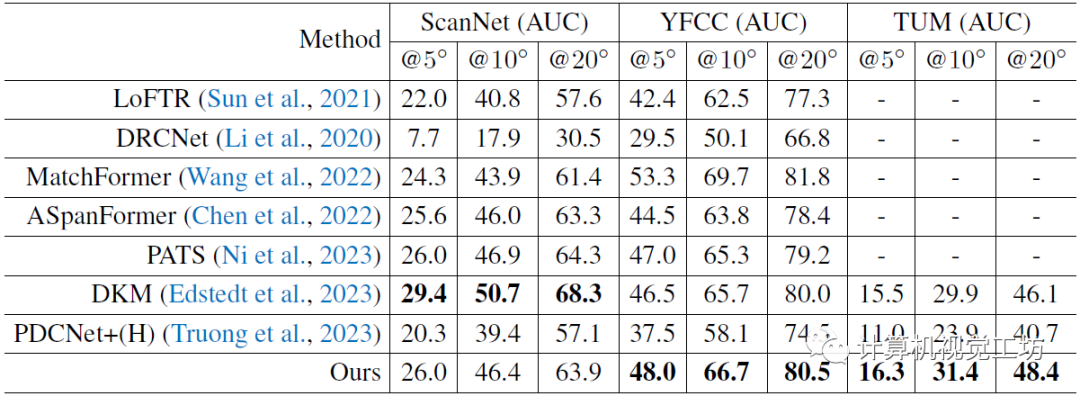
最后是一个在TUM和YFCC上进行位姿估计的zero-shot评估,也是匹配性能的进一步验证。
5. 总结
一句话总结:RGM以一个通用模型同时实现了稀疏和稠密匹配。具体创新点是级联GRU细化模块+用于稀疏化的不确定性估计模块+解耦训练机制。除了评估特征匹配的精度,作者还做了很多下游任务的评估,比如位姿估计、两视角重建。感觉这篇文章还在审稿中,后续应该会上传新版本的文章和代码。
审核编辑:黄飞
全部0条评论

快来发表一下你的评论吧 !
