

低比特量化技术如何帮助LLM提升性能
描述
作者:杨亦诚
针对大语言模型 (LLM) 在部署过程中的性能需求,低比特量化技术一直是优化效果最佳的方案之一,本文将探讨低比特量化技术如何帮助 LLM 提升性能,以及新版 OpenVINO 对于低比特量化技术的支持。
大模型性能瓶颈
相比计算量的增加,大模型推理速度更容易受到内存带宽的影响(memory bound),也就是内存读写效率问题,这是因为大模型由于参数量巨大、访存量远超内存带宽容量,意味着模型的权重的读写速度跟不上硬件对于算子的计算强度,导致算力资源无法得到充分发挥,进而影响性能。
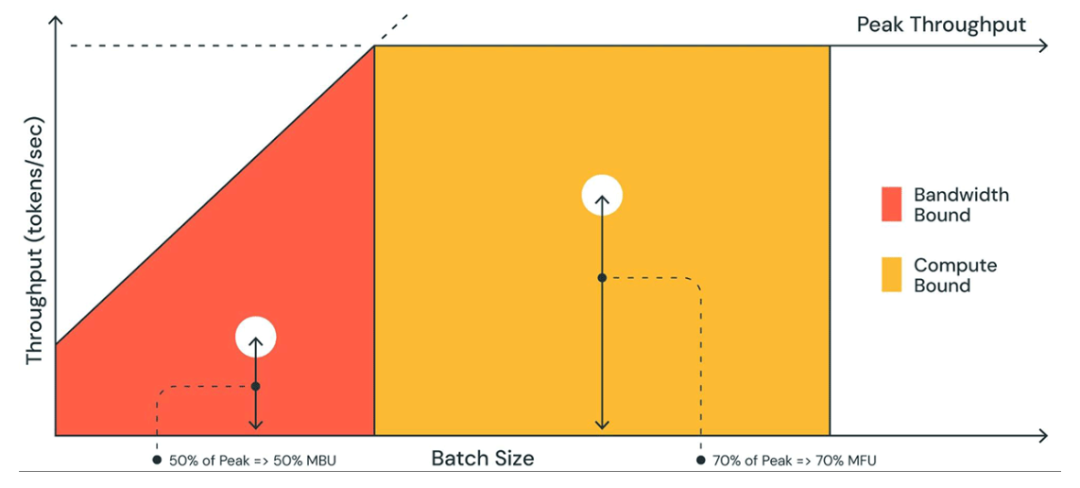
图:memory bound与compute bound比较
低比特量化技术
低比特量化技术是指将模型参数从 fp32/fp16 压缩到更低的比特位宽表达,在不影响模型输出准确性和参数量的情况下,降低模型体积,从而减少缓存对于数据读写的压力,提升推理性能。由于大模型中单个 layer 上的权重体积往往要远大于该 layer 的输入数据(activation),因此针对大模型的量化技术往往只会针对关键的权重参数进行量化 (WeightOnly),而不对输入数据进行量化,在到达理想的压缩比的同时,尽可能保证输出结果,实现最高的量化“性价比”。
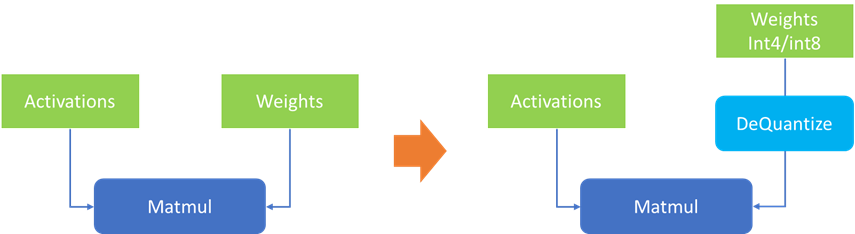
图:权重压缩示意
经验证常规的 int8 权重量化,对大模型准确性的影响极低,而为了引入像 int4,nf4 这样的更极致的压缩精度,目前在权重量化算法上也经过了一些探索,其中比较典型的就是 GPTQ 算法,简单来说,GPTQ 对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。GPTQ 量化需要准备校准数据集,因此他也是一种 PTQ(Post Training Quantization)量化技术。
OpenVINO 2023.2
对于 int4 模型的支持
OpenVINO 2023.2 相较 2023.1 版本,全面引入对 int4 模型以及量化技术的支持。主要有以下 2 个方面:
01CPU 及 iGPU 支持原生 int4 模型推理
OpenVINO 工具目前已经可以直接读取经 NNCF 量化以后的 int4 模型,或者是将 HuggingFace 中使用 AutoGPTQ 库量化的模型转换后,进行读取及编译。由于目前的 OpenVINO 后端硬件无法直接支持 int4 数据格式的运算,所以在模型执行过程中,OpenVINO runtime 会把 int4 的权重反量化的到 FP16 或是 BF16 的精度进行运算。简而言之:模型以 int4 精度存储,以 fp16 精度计算,用计算成本换取空间及 IO 成本,提升运行效率。这也是因为大模型的性能瓶颈主要来源于 memory bound,用更高的数据读写效率,降低对于内存带宽与内存容量的开销。
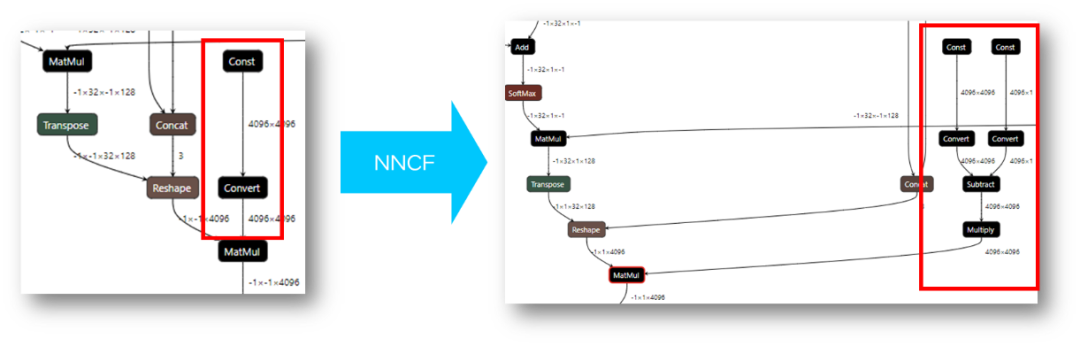
图:经 NNCF 权重压缩后的模型结构
02NNCF 工具支持 int4 的混合精度量化策略(Weights Compression)
刚提到的 GPTQ 是一种 data-based 的量化方案,需要提前准备校验数据集,借助 HuggingFace 的 Transformers 和 AutoGPTQ 库可以完成这一操作。而为了帮助开发者缩短 LLM 模型的压缩时间,降低量化门槛,NNCF 工具在 2.7.0 版本中引入了针对 int4 以及 nf4 精度的权重压缩模式,这是一种 data-free 的混合精度量化算法,无需准备校验数据集,仅对 LLM 中的 Linear 和 Embedding layers 展开权重压缩。整个过程仅用一行代码就可以完成:
compressed_model = compress_weights(model, mode=CompressWeightsMode.NF4, group_size=64, ratio=0.9)
左滑查看更多
其中 model 为 PyTorch 或 OpenVINO 的模型对象;mode 代表量化模式,这里可以选择 CompressWeightsMode.NF4,或是 CompressWeightsMode.INT4_ASYM/INT4_SYM 等不同模式;为了提升量化效率,Weights Compression 使用的是分组量化的策略(grouped quantization),因此需要通过 group_size 配置组大小,例如 group_size=64 意味 64 个 channel 的参数将共享同一组量化参数(zero point, scale value);此外鉴于 data-free 的 int4 量化策略是比带来一定的准确度损失,为了平衡模型体积和准确度,Weights Compression 还支持混合精度的策略,通过定义 ratio 值,我们可以将一部分对准确度敏感的权重用 int8 表示,例如在 ratio=0.9 的情况下,90% 的权重用 int4 表示,10% 用 int8 表示,开发者可以根据量化后模型的输出结果调整这个参数。
在量化过程中,NNCF 会通过搜索的方式,逐层比较伪量化后的权重和原始浮点权重的差异,衡量量化操作对每个 layer 可能带来的误差损失,并根据排序结果以及用户定义的 ratio 值,将损失相对较低的权重压缩到 int4 位宽。
中文大语言模型实践
随着 OpenVINO 2023.2 的发布,大语言模型的 int4 压缩示例也被添加到了 openvino_notebooks 仓库中,这次特别新增了针对中文 LLM 的示例,包括目前热门模型 ChatGLM2和 Qwen。在这个 notebook 中,开发者可以体验如何从 HuggingFace 的仓库中导出一个 OpenVINO IR 格式的模型,并通过 NNCF 工具进行低比特量化,最终完成一个聊天机器人的构建。
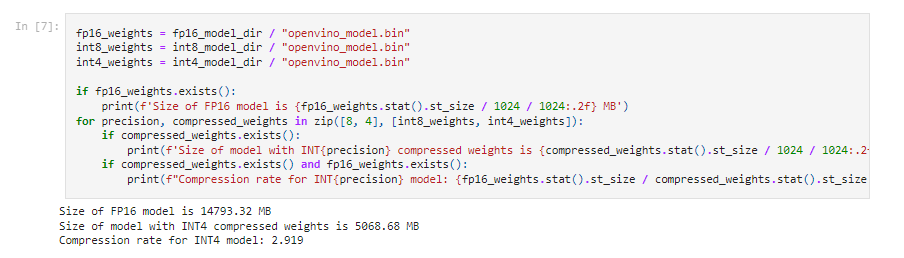
图:fp16 与 int4 模型空间占用比较
通过以上这个截图可以看到,qwen-7b-chat 经过 NNCF 的 int4 量化后,可以将体积压缩到原本 fp16 模型的 1/3,这样使得一台 16GB 内存的笔记本,就可以流畅运行压缩以后的 ChatGLM2 模型。此外我们还可以通过将 LLM 模型部署在酷睿 CPU 中的集成显卡上,在提升性能的同时,减轻 CPU 侧的任务负载。
图:Notebook 运行效果
总结
OpenVINO 2023.2 中对 int4 权重量化的支持,可以全面提升大模型在英特尔平台上的运行性能,同时降低对于存储和内存的容量需求,降低开发者在部署大模型时的门槛,让本地化的大语言模型应用在普通 PC 上落地成为可能。
审核编辑:汤梓红
-
基于RDMA技术的Spark Shuffle性能提升2019-10-28 0
-
Labview开发技术丛书--运行性能的提升技巧2016-09-02 0
-
求推荐一款单片机,量化比特大于等于12bit的ADC通道2019-05-29 0
-
多核和多线程技术怎么提升Android网页浏览性能?2020-03-25 0
-
LED产品性能的提升方法2020-11-02 0
-
如何利用物联网帮助光伏产业提升效率2021-03-11 0
-
求一种采用分段量化和比特滑动技术的流水并行式模数转换电路?2021-04-08 0
-
量化算法介绍及其特点分析2021-07-26 0
-
如何将抖动添加到信号以通过消除量化误差和失真来提高模数转换系统的性能2022-12-22 0
-
区块链比特币量化交易自动搬砖软件系统2019-01-12 865
-
量化交易在比特币市场的应用2019-04-20 1369
-
LLM性能的主要因素2023-05-22 1289
-
【比特熊充电栈】实战演练构建LLM对话引擎2023-09-19 798
-
基于MacroBenchmark的性能测试量化指标方案2023-10-17 404
-
Nvidia 通过开源库提升 LLM 推理性能2023-10-23 371
全部0条评论

快来发表一下你的评论吧 !
