

开源风波后在AlpacaEval直追GPT4,零一靠技术如何重建生态信心
描述
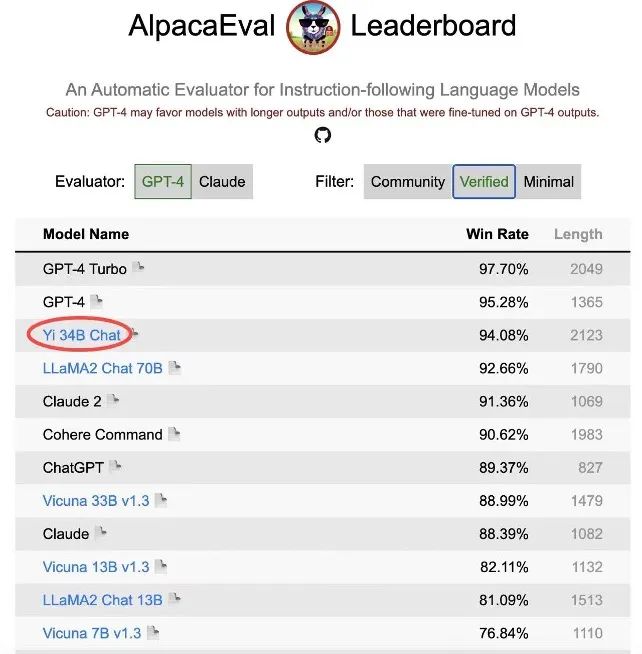
斯坦福大学研发的大语言模型评测 AlpacaEval Leaderboard 备受业内认可,在 2023 年 12 月 7 日 更新的排行榜中,Yi-34B-Chat 以 94.08% 的胜率,超越 LLaMA2 Chat 70B、Claude 2、ChatGPT,在 Alpaca 经认证的模型类别中,成为仅次于 GPT-4 英语能力的大语言模型。
同一周,在加州大学伯克利分校主导的 LMSYS ORG 排行榜中,Yi-34B-Chat 也以1102 的 Elo 评分,晋升最新开源 SOTA 开源模型之列,性能表现追平 GPT-3.5。
多个 Benchmark 遥遥领先
在五花八门的大模型评测中,伯克利 LMSYS ORG 排行榜采用了一个最为接近用户体感的 「聊天机器人竞技场」 特殊测评模式,让众多大语言模型在评测平台随机进行一对一 battle,通过众筹真实用户来进行线上实时盲测和匿名投票,11 月份经 25000 的真实用户投票总数计算了 20 个大模型的总得分。
Elo 评分越高,说明模型在真实用户体验上的表现越出色,可说是众多大模型评测集中最能展现 「Moment of Truth」真实关键一刻” 的用户导向体验对决。
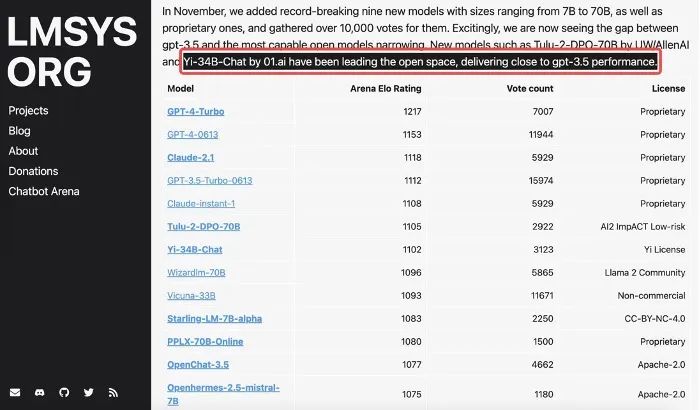
在开源模型中,Yi-34B-Chat 成为当之无愧的「最强王者」 之一(英语能力),LMSYS ORG 在 12 月 8 日官宣 11 月份总排行时评价:「Yi-34B-Chat 和 Tulu-2-DPO-70B 在开源界的进击表现已经追平 GPT-3.5」。
风波终结,争议理清
Yi-34B 开源发布后,开发者 Eric Hartford 发现了模型存在的一个问题,就简略留言在 Yi 的项目页面。然而 Eric 自己也没有预想到,他的留言引发了后续舆论关于 Yi 模型「抄袭」 LLaMA 的质疑。
他在邮件中写道,「感谢你们提供了一个优秀的模型。Yi 模型使用了与 LLaMA 模型完全相同的架构,只是将两个张量改了名字。由于围绕 LLaMA 架构有很多投资和工具,保持张量名称的一致性是有价值的。」Eric 建议,在 Yi 被广泛传播前,及时恢复张量名称。 客观来说,一个模型核心技术护城河是在架构之上,通过数据训练获得的参数和代码。大多数有志于参与基座大模型竞争的团队,也多是从零开始,用高质量的数据集再进行训练,普遍都是在沿用 LLaMA 架构。零一后来解释他们为了执行对比实验的需要,对部分推理参数进行了重新命名,原始出发点是为了充分测试模型,而非刻意隐瞒来源。
身处这场舆论风暴的中心,Eric 意识到了可能给一些人带来了误解,开始解释自己之前的发言。
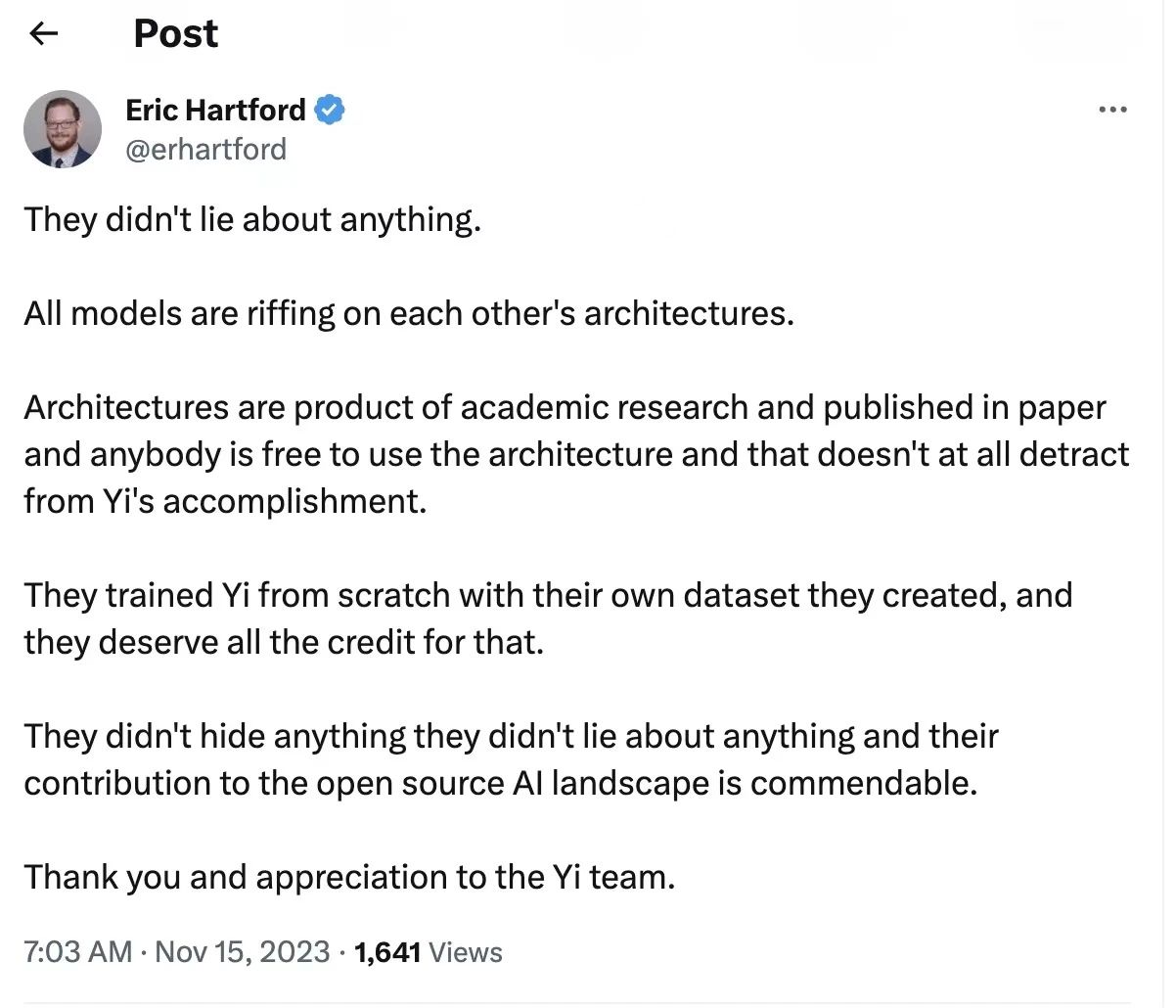
他在 X(twitter)上写道,「他们没有在任何事情上撒谎。所有的模型都是在相互借鉴架构。架构是学术研究的产物,已经发表在论文中,任何人都可以自由使用,这丝毫不减损 Yi 团队的成就。他们从零开始使用自己创建的数据集训练Yi,对开源领域的贡献是值得赞扬的。使用 Llama 架构没有任何问题。训练才是关键。Yi 给了我们目前可获得的最佳模型,没有任何可抱怨的。」 现在,Eric 自己也在使用 Yi-34B 系列,用 Yi-34b-200k 数据集训练其他的模型产品。 Yi 模型开源首月,数据也很亮眼。在 Hugging Face 社区下载量为 16.8 万,魔搭社区下载量 1.2 万。在 GitHub 获得超过 4900 个 Stars。
由于性能表现强劲,多家知名公司和机构推出了基于Yi模型基座的微调模型,比如猎豹旗下的猎户星空公司推出的 OrionStar-Yi-34B-Chat 模型,南方科技大学和粤港澳大湾区数字经济研究院(简称 IDEA 研究院)认知计算与自然语言研究中心(简称 CCNL 中心)联合发布的 SUS-Chat-34B 等,均性能表现优异。 而 AMD 和 Hugging Face 合作的GPU加速大模型的实验中,也选择了 Yi-6B 作为范例项目。
模型好不好,开发者最知道在大模型实际使用体验上,最有发言权的还是一线的开发者。 知名技术作者苏洋表示,在他观察的近期 Hugging Face 榜单中,前三十名有一半多都是 Yi 和其他用户微调的 Yi-34B 的变体模型,原本占据榜单头部的 68B 和 70B 模型的数量目前只留有几个,「从这点看 Yi 对于开源生态的帮助还是非常巨大的。」 他会时不时的浏览下 HF 的榜单,在最近榜单中的前三十名,有一半多都是 Yi 和其他用户微调的 Yi-34B 的变体模型,原本占据榜单头部的 68B 和 70B 模型的数量目前只留有几个,从这点看 Yi 对于开源生态的帮助还是非常巨大的。
苏洋还将他的训练经验和心得在CSDN上做了分享(https://blog.csdn.net/soulteary/article/details/134904434)。
苏洋认为 34B 普通用户努努力还是能自己相对低成本跑起来的,68 和 70B 的模型想要本地运行,需要更多的资源。但其实目前分数其实相比较 34B 拉不开太多,也就三四分平均分,但参数量差了一倍。换言之,企业想部署使用,所需要的成本也可以得到非常大的节约。
目前国产大模型在开源榜单上已经是第一梯队,但如果把竞争范围追加到闭源模型、尤其是海外的模型,仍有很大的距离要去追赶。目前的普遍体验是开源模型最多只有 GPT-3.5 + 的水平。
苏洋认为国产大模型,是能够很快追赶至第一梯队的。时间也会证明大模型自身的价值,以及验证出团队是否对开源有真的持续投入。
-
瑞芯微在开源支持中使用GPT作为其主要分区表2022-04-21 0
-
OpenHarmony技术日举办,华秋电子助力开源生态繁荣2022-04-26 0
-
华秋电子成为开放原子开源基金会OpenDACS捐赠人,共建 OpenDACS开源生态2022-07-08 0
-
华秋电子成为开放原子开源基金会openDACS捐赠人,共建openDACS开源生态2022-07-08 0
-
共建 openDACS开源生态 华秋电子成为开放原子开源基金会openDACS捐赠人2022-07-08 0
-
共建开源人才生态,2022 开放原子全球开源峰会聚焦“产学研用”2022-07-08 0
-
上海站报名启动! 2023年开源产业生态大会OpenHarmony生态分论坛2023-11-24 0
-
浅谈ChatGPT的最新“升级版本”——GPT4模型2023-03-22 2678
-
用GPT4搞电机?2023-04-06 1221
-
GPT4做Leetcode的能力2023-04-28 2072
-
你考虑用GPT4搞电机吗?2023-07-05 241
-
gpt-4怎么用 英特尔Gaudi2加速卡GPT-4详细参数2023-07-21 682
-
chatGPT和GPT4有什么区别2023-08-09 2060
-
ChatGPT Plus怎么支付 GPT4得订阅吗?2023-10-10 1445
-
股价久违飙涨,商汤要用自己的Scaling law挑战GPT42024-05-08 184
全部0条评论

快来发表一下你的评论吧 !
