

谷歌Gemini自曝用文心一言训练,字节被OpenAI封号,大模型互薅羊毛是常态?
描述
电子发烧友网报道(文/吴子鹏)近两天,原本就火热的人工智能大模型再度被浇上了一桶油,话题热度更胜从前。不过,这一次大家探讨的并不是大模型前景和算力这些,而是大模型之间互薅羊毛的问题。根据微博知名博主@阑夕爆料,对谷歌Gemini进行测试时,如果用中文询问Gemini的身份,其回答竟然是百度文心一言。
更让人大跌眼镜的是,测试人员可以使用“小爱同学”“小度”等提示词唤醒Gemini。并且,Gemini还能够告诉测试人员,自己是如何获取到百度的训练数据的。

网传对话场景

网传对话场景
不过,此则消息应该是很快就引起了谷歌技术人员的关注,在消息曝光不久后,Gemini应对上述提示词和问题的方式就发生了改变。通过“小爱同学”“小度”等提示词无法再唤醒Gemini,且对于相关问题的阐述也发生了变化,显然谷歌技术人员很快修复了一些bug。
谷歌Gemini饱受质疑
当地时间12月6日,谷歌宣布推出“最大、最强、最通用”的新大型语言模型Gemini,我们对此也进行了专门的报道。在发布会上谷歌声称,在32项广泛使用的基准测试中,Gemini Ultra获得了30个SOTA(State of the art,特指领先水平的大模型)。这也就意味着,Gemini 1.0版本在文本、代码、音频、图像和视频处理能力方面,以及推理、数学、代码等方面都吊打GPT-4。
同时,在发布会上谷歌还展示了Gemini相关的能力。比如,Gemini可以非常高效地从数十万份文件中获取对科学家有用的数据,并创建数据集;Gemini可以在世界上最受欢迎的编程语言(如Python、Java、C++和Go)中理解、解释和生成高质量的代码。
不过,谷歌是通过视频展示的Gemini的相关能力,而不是通过现场实操。于是乎,就在谷歌发布会的次日,有视频制作人员质疑称,谷歌的演示视频并不是实录,而是剪辑的。随后,谷歌在博客文章中解释了多模态交互过程,并提到了视频演示中的猜拳,谷歌承认,不同于视频中对于猜拳手势的快速反应,只有在向Gemini同时展示这三个手势并提示其这是游戏时,Gemini才会得出猜拳游戏的结论。
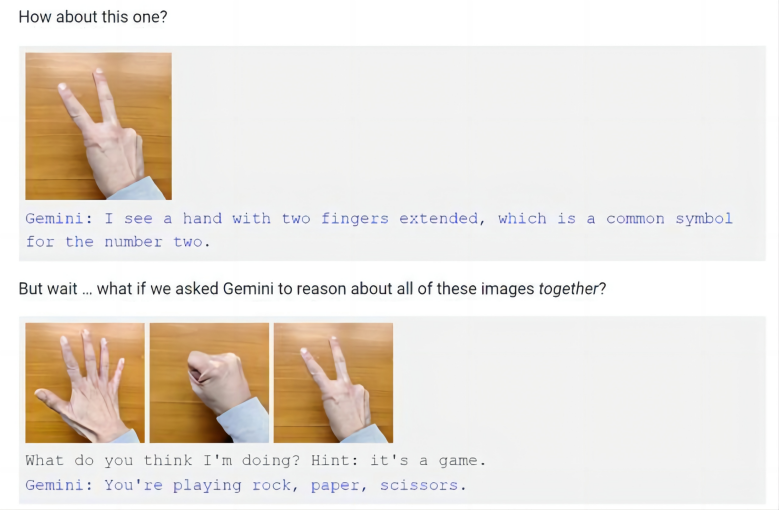
图源:谷歌博文
因此,现在很多人都认为谷歌夸大了Gemini的能力,只有使用静态图片和多段提示词拼凑,Gemini才能够显示出多模态的能力,这和谷歌宣称的实时多模态反应明显是不相符的。
大模型之间互薅羊毛
除了性能质疑之外,此次事件则揭露了大模型发展另一个规则——互薅羊毛。实际上,在Gemini自曝是百度文心一言之前,国内字节跳动就发生了相关问题。
近日,有外媒报道称,字节跳动在使用OpenAI技术开发自己的大语言模型,违反了OpenAI服务条款,导致账户被暂停。对此,字节跳动相关负责人向记者回应称:今年年初,当技术团队刚开始进行大模型的初期探索时,有部分工程师将GPT的API服务应用于较小模型的实验性项目研究中。该模型仅为测试,没有计划上线,也从未对外使用。4月公司引入GPT API 调用规范检查后,这种做法已经停止。字节跳动称,后续会严格遵守OpenAI的使用协议。
从Gemini调整之后的回复来看,其在训练过程中确实使用了百度文心一言的训练数据,这其实也无可厚非。百度文心一言在中文理解及相关的多模态生成能力方面确实处于领先的位置,那么背后的原因定然是因为百度掌握着质量相对更好的中文训练数据集,因此其他大模型如果想要在中文对话方面取得进展,使用文心一言的训练数据确实是最高效的方式。
另外,除了字节跳动,此前谷歌也被质疑使用OpenAI数据来训练Bard,最终谷歌的回应是Bard没有使用ShareGPT或是ChatGPT的任何数据来进行训练。另外,国内也有很多公司被质疑是采用OpenAI数据来完善自己的大模型。不过,这种行为大都见不得光,因此都被否认了。
为什么其他大模型频传借用OpenAI数据来训练呢,重要原因在于GPT-4性能领先一个重要的原因就是数据集质量更高。根据semianalysis发布的《GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE》文章,GPT-4是一个使用1.8万亿巨量参数训练的模型框架,而GPT-3只有约1750亿个参数,另外GPT-4拥有16个专家模型,每个MLP专家大约有1110亿个参数。这就是为什么在展示Gemini Ultra的MMLU训练时,谷歌将“CoT@32”进行小字注释,代表Gemini Ultra的MMLU测试使用了思维链提示技巧,尝试了32次并从中选择最好结果。与之对比,GPT-4无提示词技巧给5个示例。就这样,GPT-4的成绩为86.4%,依然高于Gemini Ultra的83.7%。
另外,OpenAI用13万亿的token训出了GPT-4。因为没有高质量的token,这个数据集还包含了许多个epoch。
综上所述,虽然GPT-4的训练数据规模没有官方说明,但是semianalysis文章可信度很高,这个规模比Gemini Ultra宣称的万亿似乎更强,也不怪大家都想用GPT调优自己的模型。
当然,每一个模型都有自己擅长的地方,尤其是那些垂直的行业模型,在行业数据方面肯定是优于一般多模态大模型的,因此被薅羊毛的概率也很大,但是这大都不会被公开。
大模型数据集背后的产业链
为了让GPT-4具有领先的性能,OpenAI的研发团队在模型优化、数据选择和硬件投入等方面做了大量工作。相信谷歌的Gemini Ultra和百度文心一言等大模型也是如此。对于大模型来说,预训练数据集是一个非常关键的元素,很大程度上决定了大模型最终的性能水平。
在这个大背景下,随着大模型产业发展,训练数据也逐渐成为一种产业。比如国内的云测数据,云测创立于2011年,是一家以人工智能技术驱动的企业服务平台,为全球超过百万的企业及开发者提供云测试服务、AI训练数据服务、安全服务。该公司的云测数据入选“北京市人工智能行业赋能典型案例(2023)”,在垂直大模型训练数据服务方面很有造诣。
再比如,海天瑞声作为国内领先基础数据服务商,是国内首家且是目前唯一一家A股上市的人工智能训练数据服务企业,为阿里巴巴、Meta、腾讯、百度、字节跳动等公司提供数据服务。
北京邮电大学科学技术研究院副院长曾雪云教授此前在受访时表示,“互联网上生成的这些数据,它是非结构化的数据,也是非标准化的数据。这样的数据就是一种原始的、比较杂乱的、没有规范的数据,它就需要在计算前进行颗粒度上的清洗,所以高质量数据通常都有从非结构化到结构化这样的一个加工过程。”
“现在从对数据科学的研究、国家对数据的治理,到学术界对数据的研究、产业界对数据的利用都是一个蓝海,都是一个刚开始的状态。”曾雪云教授提到。
当然不仅国内关注到这一块的产业价值,作为头部企业,OpenAI希望与机构合作建立新的人工智能训练数据集。OpenAI为此创立了“数据伙伴关系”(Data Partnerships)计划,该计划旨在与第三方机构合作,建立用于人工智能模型训练的公共和私有数据集。OpenAI 在一篇博文中表示,数据合作伙伴关系旨在“让更多组织能够帮助引导人工智能的未来”,并“从更有用的模型中获益”。
结语
人工智能大模型其实是大数据时代的典型产物,那么也就无法脱离对大数据的依赖。大模型的火爆让高质量训练数据成为高价值、紧俏的资源,而这些数据往往掌握在头部企业手里,这就是为什么大模型企业之间互相会薅羊毛。不过,相较于互联网海量的数据,目前科技巨头的训练数据集还只是九牛一毛,如何从海量互联网数据提取有价值的训练数据集,已经逐渐成为一个产业链。
-
用HarmonyOS元服务万能卡片训练一下文心一言的AIGC能力2023-04-18 0
-
谷歌Gemini被曝算力达GPT-4五倍,手握TPU王牌碾压OpenAI2023-09-04 636
-
谷歌Gemini模型AI网络及TPU拆解2023-12-14 673
-
谷歌推出Gemini 希望击败GPT-42023-12-14 516
-
新火种AI | 谷歌Gemini“抄袭”百度文心一言?AI训练数据陷难题2023-12-20 259
-
谷歌最新人工智能模型Gemini Pro已在欧洲上市2024-02-04 773
-
谷歌推出新一代大模型Gemini 1.52024-02-20 399
-
谷歌模型训练软件有哪些功能和作用2024-02-29 442
-
谷歌模型训练软件有哪些?谷歌模型训练软件哪个好?2024-03-01 355
-
谷歌计划将先进大模型Gemini明年嵌入安卓手机2024-03-06 376
-
微软自研AI大模型即将问世2024-05-07 198
-
微软准备推出新的AI模型与谷歌及OpenAI竞争2024-05-08 283
-
微软将推出自研AI大模型2024-05-13 344
-
谷歌Google Calendar、Tasks与Keep应用中成功整合Gemini模型2024-05-15 98
全部0条评论

快来发表一下你的评论吧 !
