

无需微调,即插即用的占据预测模型—FlashOcc介绍
电子说
描述
1. 本文简介
占据预测是指在自动驾驶系统中,根据传感器的输入,预测三维空间中的每个体素是否被物体占据。占据预测可以有效地解决三维物体检测中的长尾问题和复杂形状的缺失问题。然而,占据预测也面临着一个挑战,即如何在保证准确性的同时,提高速度和降低内存消耗。现有的占据预测方法通常使用三维卷积来处理体素级别的特征,这会导致大量的计算和存储开销,不利于部署到不同的芯片上。为了解决这个问题,文章提出了一种快速和节省内存的占据预测方法,称为FlashOcc。FlashOcc的核心思想是利用一个通道到高度的变换,将二维的鸟瞰图特征转换为三维的占据概率,从而避免了使用三维卷积。FlashOcc的优点是,它可以作为一个插件,直接应用到现有的占据预测方法上,无需额外的训练或微调。文章在Occ3D-nuScenes数据集上进行了实验,证明了FlashOcc的有效性和高效性,在保持高精度的同时,显著提高了速度和降低了内存消耗,展示了其在自动驾驶场景中的潜力。
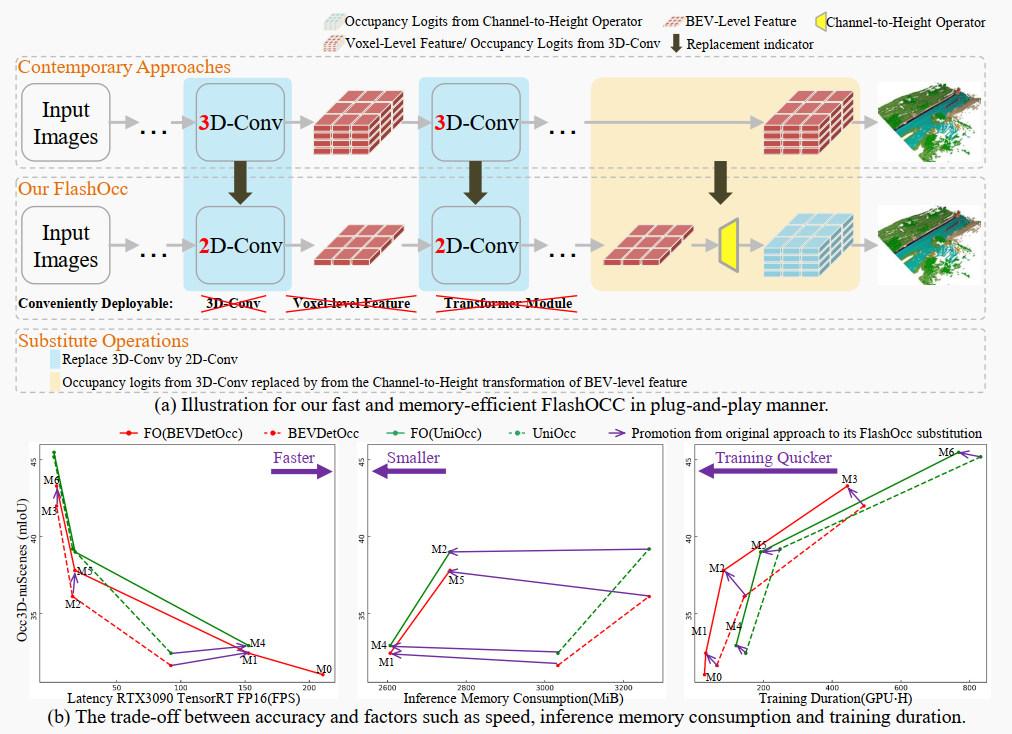
图1.(a) 说明了我们的FlashOcc如何以插即用的方式实现。当代方法使用由3D卷积处理的体素级特征预测占据情况。与之形成对比,我们的插件模型通过(1)用2D卷积替换3D卷积。(2)用通道与高度变换的BEV级特征替换3D卷积派生的占据logits,实现了快速和内存高效的占据预测。(b) 插件替代与原始方法之间在精度及速度、内存消耗和训练时间等因素上的权衡。
2. 原文摘要
由于具有减轻数据集长尾效应和复杂形状缺失的作用,占据预测已经成为自动驾驶系统中的重要组成部分。然而,使用三维体素级表示不可避免地导致了巨大的内存和计算开销,这限制了占据预测方法的部署。与当前使模型更大更复杂的趋势相反,我们认为理想的框架应该既能适应各种芯片以便部署,又能保持高精度。为此,我们提出了一个即插即用的范式,即FlashOCC,以实现快速和内存高效的占据预测,同时保持高精度。具体来说,我们的FlashOCC在现有的体素级占据预测方法的基础上做了两点改进。第一,特征保留在俯视图中,以利用高效的2D卷积层进行特征提取。第二,引入了一种通道与高度的变换,以将输出结果从俯视图映射到三维空间。我们在具有挑战性的Occ3D-nuScenes基准测试上将FlashOCC应用于不同的占据预测基线,并进行了广泛的实验来验证其有效性。结果表明,我们的即插即用范式在精度、运行时效率和内存成本方面都优于之前的最先进的方法,显示了其部署的潜力。代码将会开源。
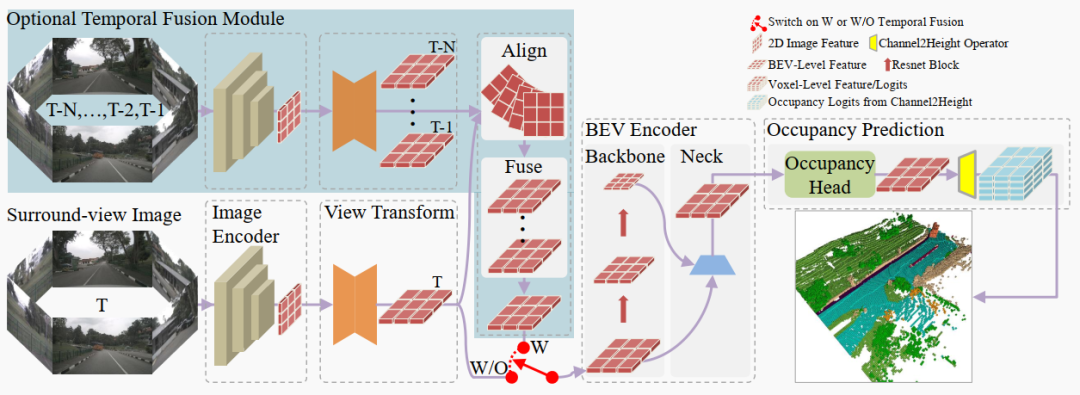
图2. 我们的FlashOcc的总体架构。虚线框标识的区域表示可替换模块。每个可替换模块的特征形状按图1和图2中的说明表示。浅蓝色区域对应可选的时序融合模块,其使用取决于红色开关的激活。
3. 方法详解
FlashOcc系统框架如图2所示。输入数据为环视图像,输出为密集的占据预测结果。它包括五个基本模块:(1)二维图像编码器;(2)视角变换模块;(3)BEV编码器;(4)占据预测模块;(5)时序融合模块(可选)。
3.1 图像编码器
图像编码器使用backbone网络提取输入图像的高层语义特征,然后馈入neck模块进行融合,从而充分利用不同粒度的语义信息。常用的backbone网络有经典的ResNet和强大的Swin Transformer。neck模块选择简洁的FPN-LSS,它将细粒度特征与直接上采样的粗粒度特征集成。
3.2 视角变换
视角变换模块的作用是将二维感知视角特征映射到BEV表示中。Lift-splat-shot (LSS)和Lidar Structure (LS)被广泛使用。LSS利用像素级密集深度预测和相机内在外参将图像特征投影到预定义的三维网格体素上。然后沿垂直维度(高度)应用汇聚操作以获得扁平的BEV表示。然而,LS依赖均匀分布的深度进行特征转换,这会导致沿相机光线方向的特征错配和后续的错误检测,尽管计算复杂度有所降低。
3.3 BEV编码器
BEV编码器通过视角变换获得的粗糙BEV特征,输出更详细的三维表示。其结构与图像编码器类似,包括backbone和neck。正如第3.1节所概述的,我们采用相同的设置。经过若干层后,特征扩散用于改善中心特征丢失的问题。如图2所示,两个不同尺度的特征被集成以增强表示质量。
3.4 占据预测头部

3.5 时序融合组件
时序融合组件通过整合历史信息来增强动态物体或属性的感知。它包含两个主要组件:空间-时序对齐模块和特征融合模块。对齐模块使用自身信息将历史BEV特征与当前激光雷达系统对齐。这种对齐过程确保历史特征得以正确插值和与当前感知系统同步。一旦完成对齐,对齐的BEV特征被传递到特征融合模块。该模块考虑它们的时序上下文,集成对齐特征以生成动态物体或属性的全面表示。融合过程组合相关的历史特征和当前感知输入的信息,以提高整体感知精度和可靠性。
4. 实验结果
我们对Talk2BEV在Talk2BEV-Bench上的问题进行了定量评估。我们报告了不同LVLM在不同任务子集和不同类型问题上的性能,以及它们的平均性能。MiniGPT-4在所有类型问题上都取得了最佳的平均性能。BEV中的误差对性能的影响较小,这表明随着更高性能的LVLM的出现,Talk2BEV的性能有望进一步提高。表II展示了Talk2BEV使用不同LVLM构建的语言增强地图(BLIP-2、InstructBLIP-2、MiniGPT-4)和BEV变体(LSS和GT)在多项选择问题(MCQs)上的性能。表III评估了空间操作符对系统性能的影响,显示了集成空间操作符带来的显著改进。此外,表IV报告了不同对象类别的性能,突出了车辆类别之间的性能差异。
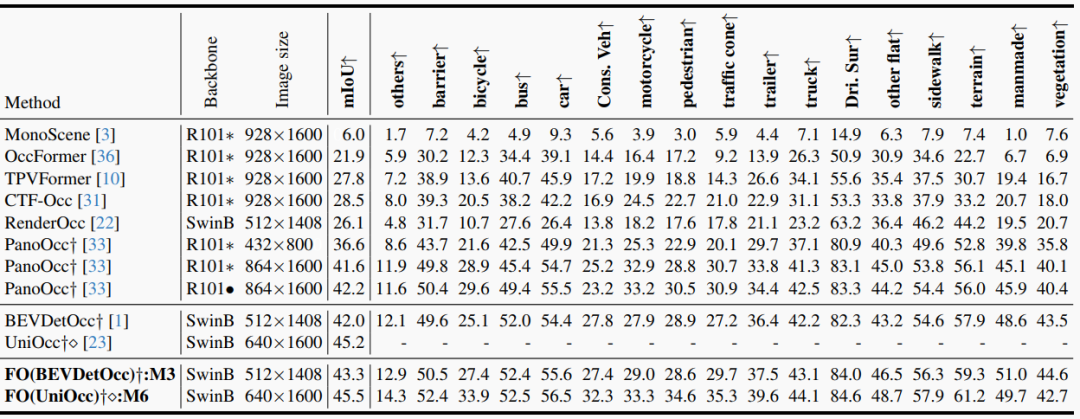
表1. Occ3D-nuScenes验证集上的三维占据预测性能。
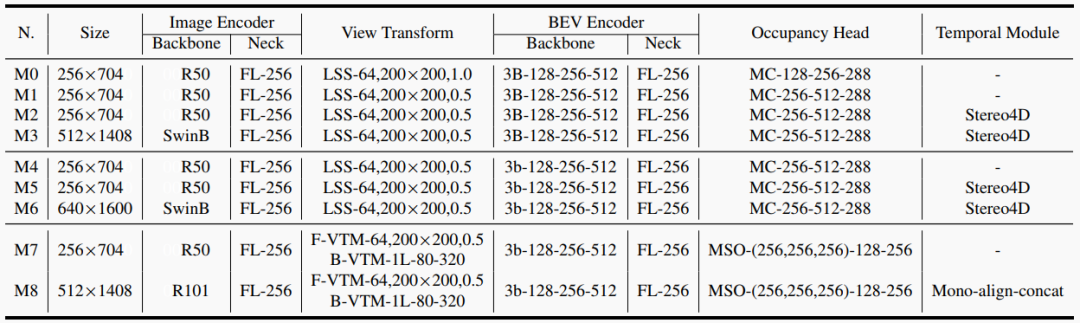
表2. 各种方法的详细设置。
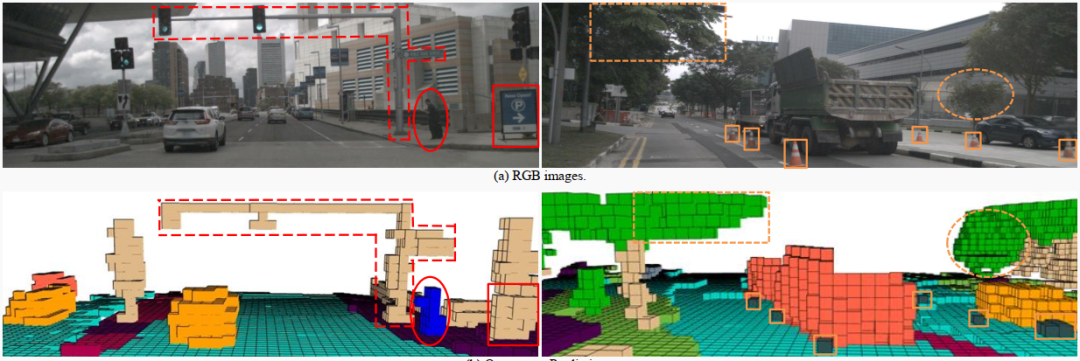
图3. Occ3D-nuScenes上的定性结果。

表3. 在各种流行的基于体素的占据方法论上普适性demonstration的FlashOcc。
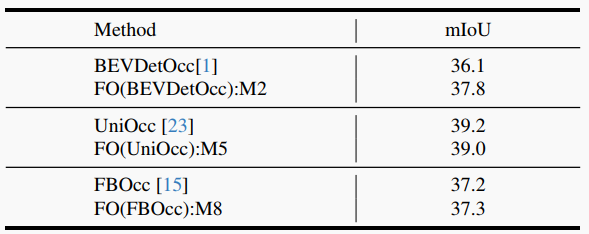
表4. 时序融合中的持续改进demonstration。
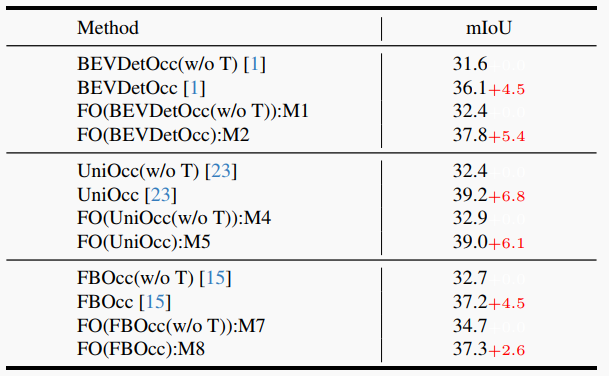
表5. 训练和部署期间的资源消耗分析。
5. 总结
在本文中,我们介绍了一种即插即用的方法,称为FlashOCC,它旨在实现快速和节省内存的占据预测。它直接用二维卷积替换了基于体素的占据方法中的三维卷积,并引入了通道到高度的变换,将扁平化的BEV特征重塑为占据logits。FlashOCC的有效性和泛化性已经在多种体素级占据预测方法上得到了验证。广泛的实验表明,该方法在精度、时间消耗、内存效率和部署友好性方面优于以前的最先进的方法。据我们所知,我们是第一个将子像素范式(通道到高度)应用于占据任务的工作,它仅利用BEV级特征,完全避免了使用计算复杂的三维(可变形)卷积或变换器模块。并且,可视化结果令人信服地证明了FlashOcc成功地保留了高度信息。在我们的未来工作中,我们将探索将我们的FlashOcc集成到自动驾驶的感知流程中,旨在实现高效的片上部署。
审核编辑:刘清
-
即插即用和热插拔的区别2012-10-23 0
-
————即插即用无需组网协议wifi模块————2014-03-25 0
-
即插即用移动电源管理芯片2015-11-25 0
-
多片段时序数据建模预测实践资料分享2021-06-30 0
-
模型预测控制介绍2021-08-18 0
-
PCI与即插即用2008-12-09 2015
-
什么是即插即用2009-12-28 2043
-
数据预测分析方法2016-01-15 741
-
详细剖析OPC和即插即用技术2018-01-26 5721
-
Bluetechnix演示即插即用摄像机系统2018-06-04 1854
-
神经网络在数据预测有怎么样的应用2020-02-29 660
-
季节性时空数据预测模型在城市中的应用2021-06-07 437
-
索引即插即用主板REV0002022-07-27 375
-
电源系统设计:非完全“即插即用”2022-11-07 261
-
四种微调大模型的方法介绍2024-01-03 6023
全部0条评论

快来发表一下你的评论吧 !
