

大模型学习笔记
描述
Apple最近发表了一篇文章,可以在iphone, MAC 上运行大模型:【LLM in a flash: Efficient Large Language Model Inference with Limited Memory】。
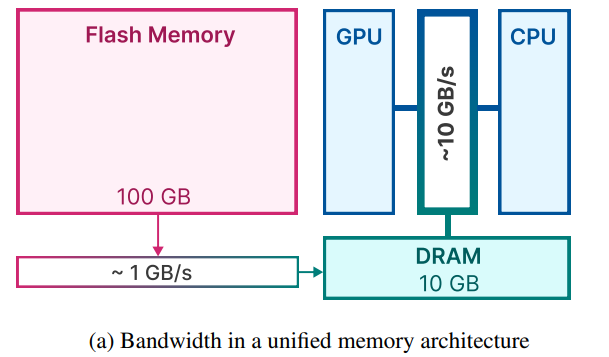
主要解决的问题是在DRAM中无法存放完整的模型和计算,但是Flash Memory可以存放完整的模型。但是Flash带宽较低,LLM in Flash通过尽量减少从Flash中加载参数的数量,优化在DRAM中的内存管理,实现在Flash带宽有限的条件下提高计算速度的目的。
这篇文章很多都是工程上的细节,很少理论。下面是这篇论文的总结,如有不对的地方,欢迎私信。
利用FeedForward 层的稀疏度,只加载FeedForward层输入非0和预测输出非0的参数
通过Window Sliding 只加载增量的参数,复用之前的计算,减少需要加载的参数。
将up-projection的row和down-projection的column放在一起存放,这样在flash中可以一次读取比较大的chunk,提高flash的带宽利用效率。
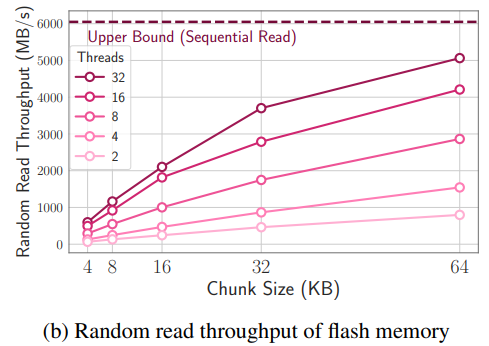
如下图所示,chunk越大,带宽也就越大,初始加载chunk的latency可以被平摊。
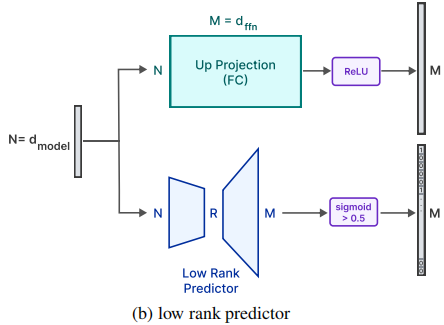
1. 大模型在FeedForward layer有超过90%的稀疏度。将embedding和attention 矩阵一直保存在DRAM中。Attention 的权重占据了model总量的1/3。对于FeedForward Layer,只有非稀疏的部分被动态的加载进去DRAM。
2. 预测Relu层的稀疏性。在attention层的输出后面增加low-rank predictor,预测在relu层之后可能是0的元素。
经过优化后,最终只需要加载2%的FeedForward层的参数到DRAM中。
3. Sliding Window
每次滑动窗口,在生成新的token后,删掉不在window内的neuron,增加新的neuron。
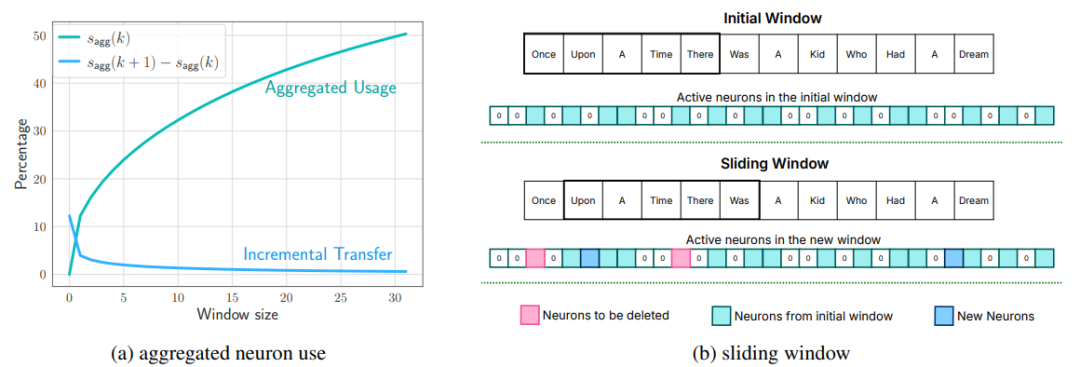
上图右侧为一个window size为5的示意图,粉色的是要删除的元素,蓝色的是新加入的元素。
上图左侧是如何在aggregated usage和incremental transfer中保持平衡,window设置的越大,每次新需要加载neruon也就越少,但是需要在memory中累计保存的空间占用的也就越大。
上图左侧的目标就是如何让aggregated usage和incremental transfer都比较小。
译者疑问:这个window就是Longformer: The Long-Document Transformer 中的sliding window吗?欢迎私信。
4. 内存管理
内存管理也是因为sliding window引入的。
译者注:
就像c++中vector的维护一样,如果每次删除vector中间的一个元素,都需要导致该元素后面所有元素的移动。
下图描述的就是删除和加入新neuron的内容。
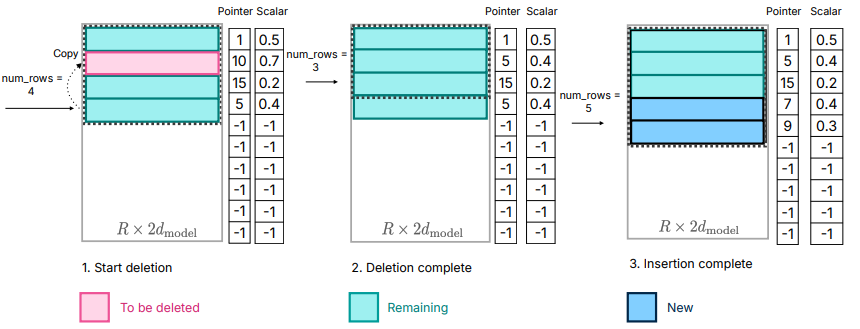
最后文章还提出了比较有意思的一点,他们主要进行了稀疏化的优化,在计算和加载参数方面。他们也尝试了通过和当前neuron关系紧密的 “closest friend”绑定,每次加载neuron时,也都加载他的closest friend。
作者说但是这样带来了负面作用,因为存在一些closest friend是很多neuron的closest friend (译者注:类似于大众之友),这些neuron被频繁的加载到DRAM中,反而降低了性能。
审核编辑:汤梓红
-
TensorFlow的学习笔记2020-06-12 0
-
深度学习模型是如何创建的?2021-10-27 0
-
记录一下Linux设备模型学习历程2022-02-17 0
-
Allegro学习笔记2015-11-23 547
-
模拟电路学习笔记2016-09-20 670
-
PADS_2007学习笔记2017-01-16 640
-
Ansoft学习笔记2017-03-23 1318
-
Java设计模式学习笔记2017-09-08 746
-
ARM学习笔记2017-10-13 688
-
Altera FPGA CPLD学习笔记2021-09-18 1180
-
OpenStack之Cinder学习笔记2021-09-23 591
-
【学习笔记】单片机汇编学习2021-11-14 517
-
Linux设备模型学习笔记(1)2021-12-22 281
-
Sentaurus TCAD学习笔记2023-08-07 408
-
Allegro学习笔记.zip2022-12-30 177
全部0条评论

快来发表一下你的评论吧 !
