

最佳开源模型刷新多项SOTA,首次超越Mixtral Instruct!「开源版GPT-4」家族迎来大爆发
描述
【导读】Mixtral 8x7B模型开源后,AI社区再次迎来一大波微调实践。来自Nous Research应用研究小组团队微调出新一代大模型Nous-Hermes 2 Mixtral 8x7B,在主流基准测试中击败了Mixtral Instruct。
Mixtral 8x7B开源模型的诞生,正如Llama一样,为开源社区了带来曙光。
前段时间,Mixtral刚刚发布了8x7B模型的论文。在基准测试结果中,其性能达到或超过 Llama 2-70B和GPT-3.5。
甚至,Mixtral在数学、代码生成和多语言理解任务方面表现亮眼。
最近,一个开源研究小组Nous Research推出了新一代旗舰大模型Nous-Hermes 2 Mixtral 8x7B。
这是首个通过RLHF训练的模型,并在主流基准测试中超越Mixtral Instruct,成为最佳开源模型。

此外,Nous Research团队发布的SFT和SFT+DPO模型,以及DPO适配器将为用户提供更多选择。

在所有的基准测试中,Nous-Hermes 2 Mixtral 8x7B模型也略不逊色。
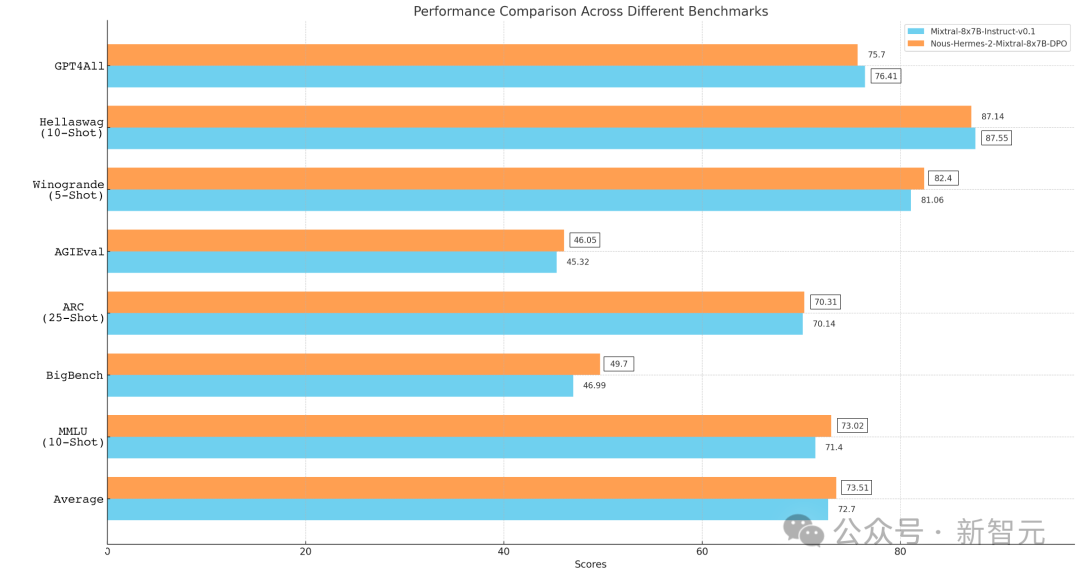
目前,这些模型同样在Hugging Face上开源上线。
最佳开源模型诞生
据介绍,最新模型是在Mixtral 8x7B MoeLLM微调训练而来。
具体来说,Nous-Hermes 2 Mixtral 8x7B是在1,000,000个条目进行了训练(主要是GPT-4生成的数据),以及整个AI领域开放数据集等其他高质量数据集。

研究人员同时还发布了SFT Only版本,以及SFT+DPO版本。


模型演示
那么,Nous Research团队最新的模型能力有多强?
编写可视化数据代码完全是小菜一碟。
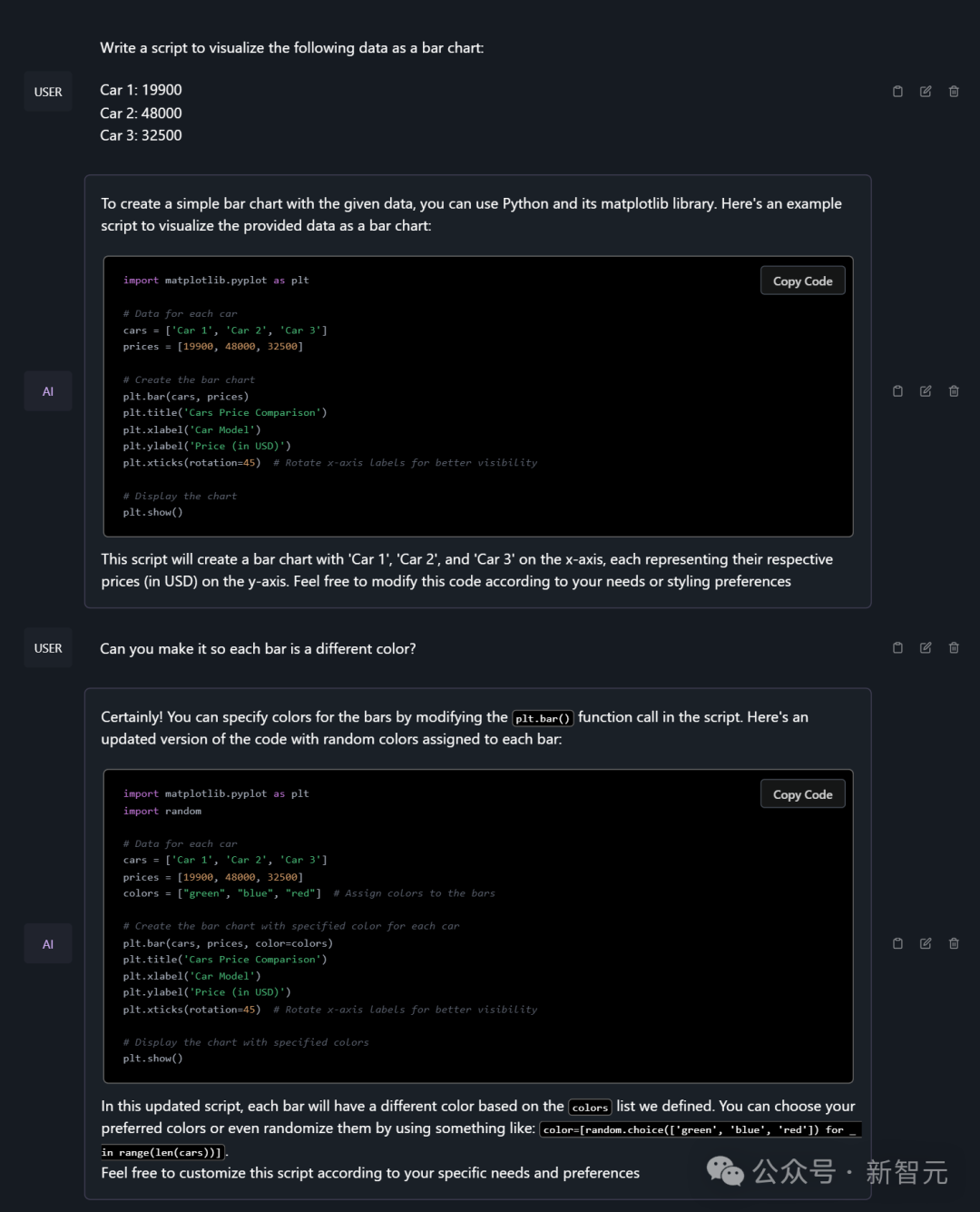
它还能写赛博朋克的迷幻诗。

可以执行反向翻译,从输入文本中创建提示信息。

基准测试
与Mixtral基础模型相比,Mixtral 8x7B上的Nous-Hermes 2在以下基准测试中取得了全面提升,也是MistralAI首次击败旗舰型号Mixtral Finetune。
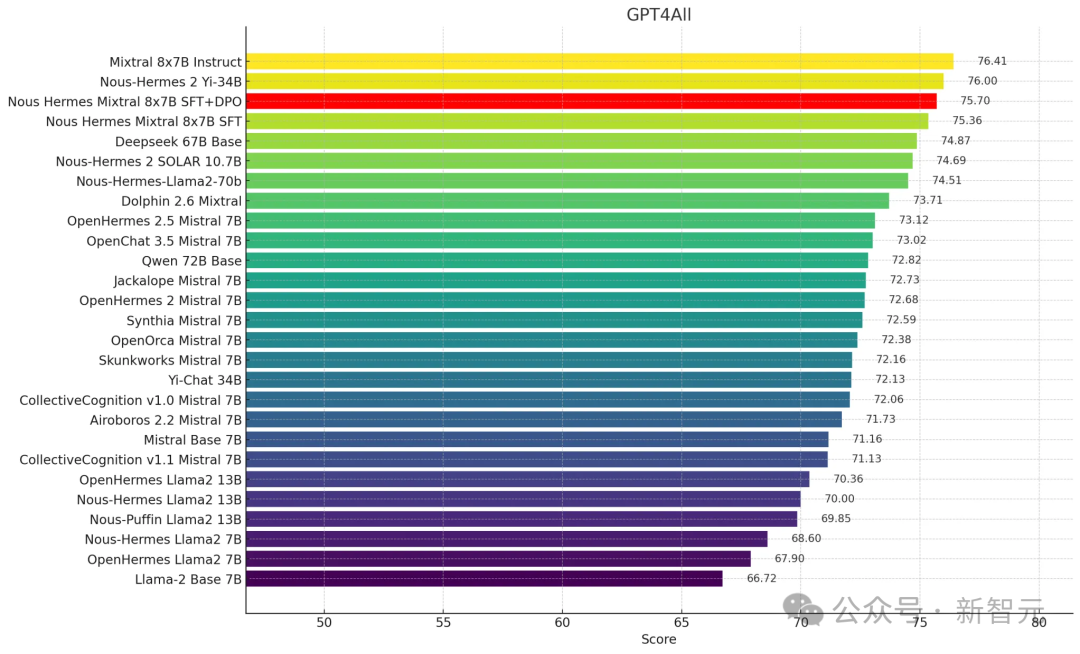
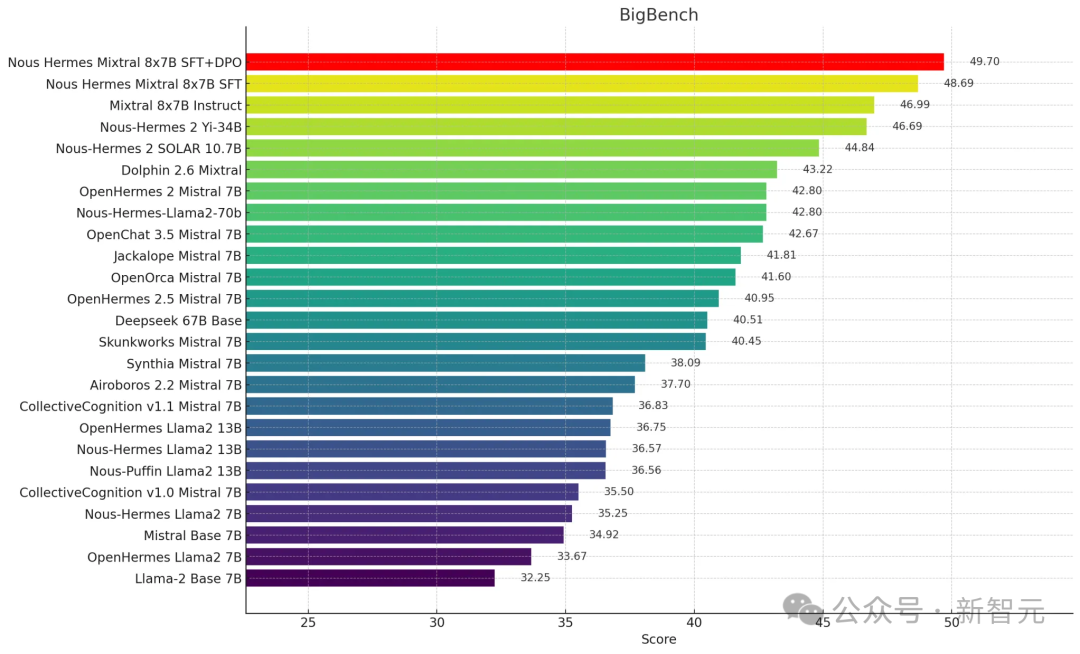
在GPT4All中,Nous-Hermes Mixtral 8x7B(SFT+DPO)拿下了75.7分,位列榜单第三。
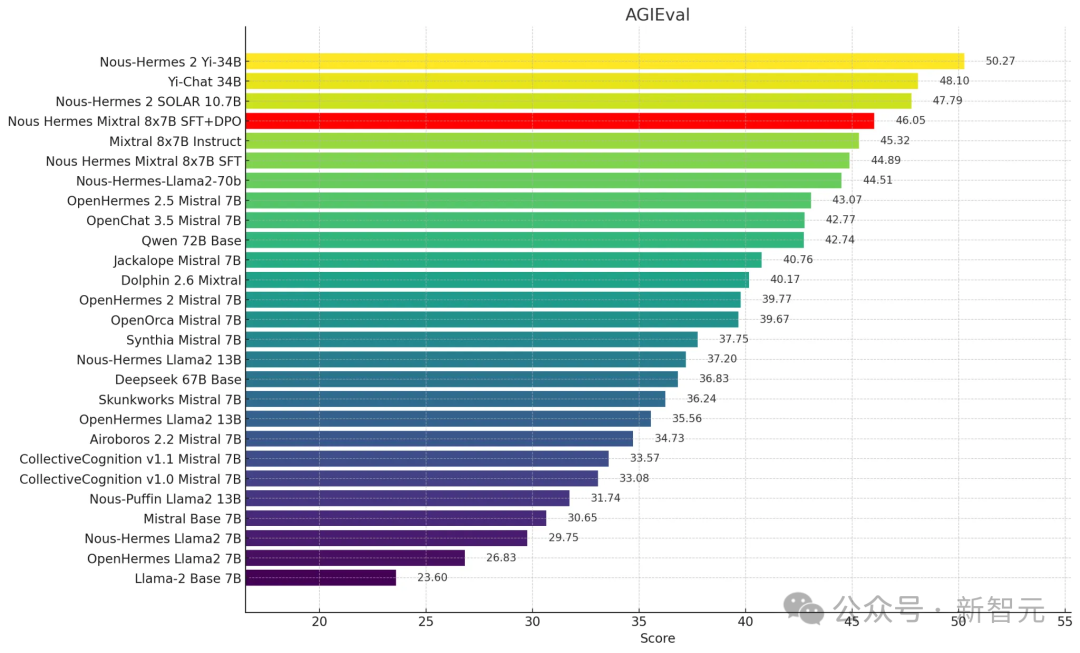
在AGIEval的排行中,Nous-Hermes Mixtral 8x7B(SFT+DPO)拿下了46.05的成绩。
此外,在BigBench Reasoning Test中,Nous-Hermes 2 Mixtral 8x7B(SFT+DPO)霸榜第一。
背后团队
成立于2023年,Nous Research是一个在大模型领域发布开源研究而闻名的私人应用研究小组。
去年12月,这个研究团队成员曾发布了一款轻量的视觉语言模型——Nous Hermes 2 Vision。
这个模型以希腊神使赫尔墨斯的名字命名。它通过用户上传的图像数据,通过自然语言提供详细的答案。

就在前几天,Nous Research宣布了一轮520万美元的种子融资,涉及了多位天使投资人。
到目前为止,Nous Research已经发布了40多个开源模型,包括Hermes、YaRN、Capybara、Puffin和Obsidian系等系列。

Mixtral模型,会将成为开源版GPT-4
继2023年年初Llama发布之后,一系列羊驼家族瞬间爆发。年底,Mixtral的开源MoE发布,更是为开源年做了一个完美的收尾。
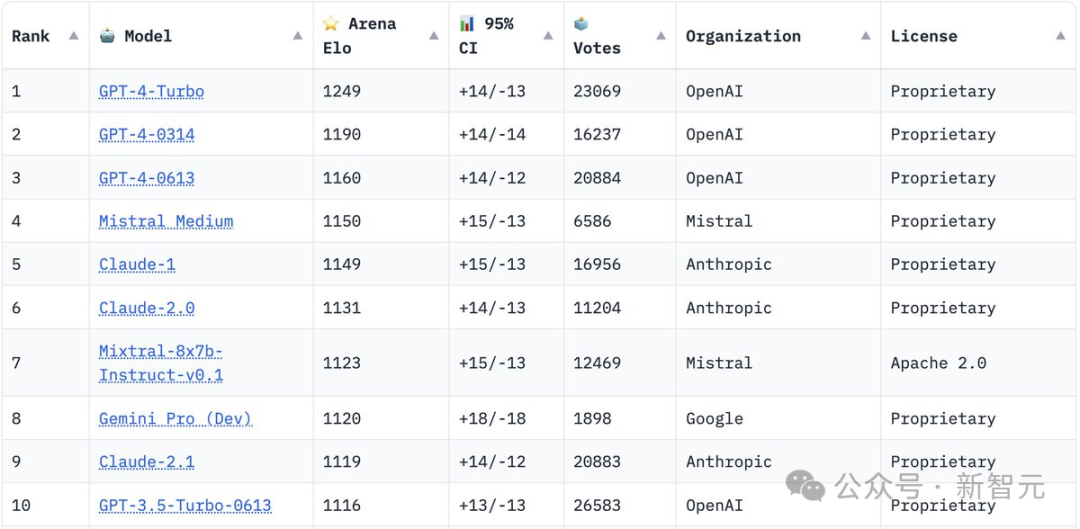
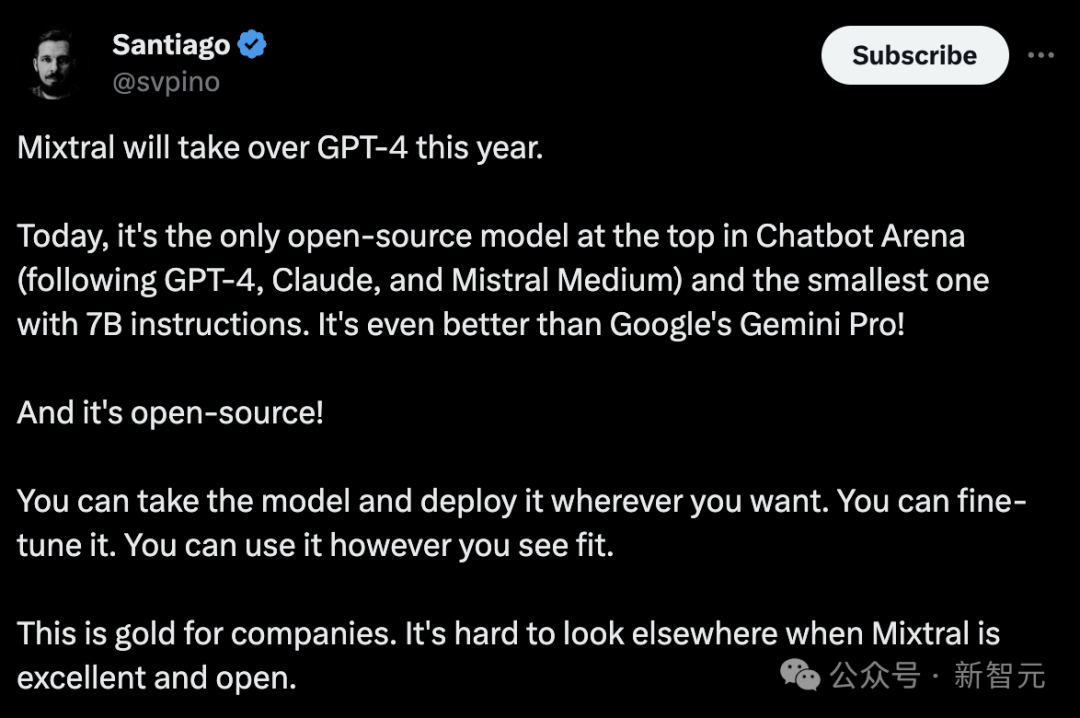
有网友表示,Mixtral或将有实力将于今年接管GPT-4。
在Chatbot Arena排行榜上,Mixtral成为(继GPT-4、Claude和Mistral Medium之后)唯一能打的开源模型,也是仅有7B参数的最小模型,甚至比谷歌的Gemini Pro还要好!
而且它是开源的!任何人可以获取该模型,并将其部署到自己的设备,而且可以对其进行微调,可以随心所欲地使用它。
现在,在Mixtral-7B上进行微调、部署的模型案例,也是非常的多。
比如,有网友用树莓派在本地跑起了Phi-2、Mistral和LLaVA等模型。
还有人出了一款APP,名为Offline Chat:Private AI,能够在iPhone上离线跑Mistral 7B模型。
这样一来,模型生成的内容,可以保障安全和隐私。
还有人用直接偏好微调了Mistral-7B模型。

具体来说,研究人员将使用一种类似RLHF的技术:直接偏好优化(DPO)对OpenHermes-2.5进行微调,从而创建NeuralHermes-2.5。
为此,他们还引入了一个偏好数据集,描述DPO算法的工作原理,并将其应用到模型中。我们将看到它显著提高了OpenLLM排行榜上基本模型的性能。
有网友进行的海底捞针实验中, Mistral-7B-Instruct-v0.2在80000 token情况下,召回率下降。
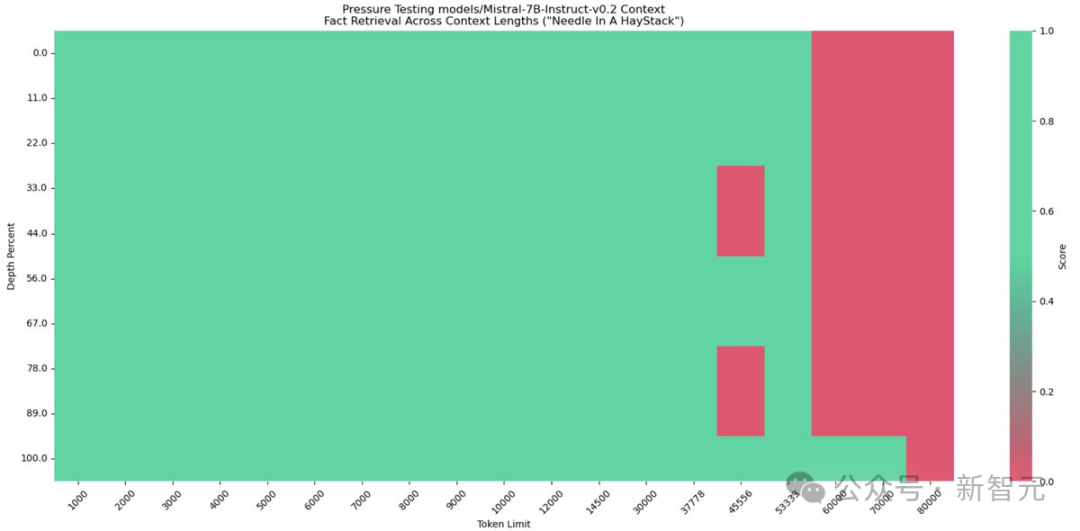
相信未来,Mixtral模型会向羊驼家族一样,迎来大爆发。
-
IBM在watsonx上提供开源的Mistral AI模型2024-03-12 1104
-
Eleuther AI:已经开源了复现版GPT-3的模型参数2021-03-31 2932
-
GPT-4发布!多领域超越“人类水平”,专家:国内落后2-3年2023-03-16 4131
-
ChatGPT升级 OpenAI史上最强大模型GPT-4发布2023-03-15 2446
-
GPT-4多模态模型发布,对ChatGPT的升级和断崖式领先2023-03-17 3044
-
一个基于GPT-4的代码搜索引擎,开源了!2023-04-27 956
-
GPT-4 的模型结构和训练方法2023-05-22 2080
-
可商用多语言聊天LLM开源,性能直逼GPT-42023-05-25 743
-
GPT-4没有推理能力吗?2023-08-11 687
-
ChatGPT重磅更新 OpenAI发布GPT-4 Turbo模型价格大降2/32023-11-07 2219
-
周鸿祎:长期看谷歌赶上GPT-4绰绰有余2023-12-11 364
-
全球最强大模型易主:GPT-4被超越,Claude 3系列崭露头角2024-03-05 280
-
全球最强大模型易主,GPT-4被超越2024-03-05 313
-
微软Copilot全面更新为OpenAI的GPT-4 Turbo模型2024-03-13 285
-
阿里云发布通义千问2.5大模型,多项能力超越GPT-42024-05-09 140
全部0条评论

快来发表一下你的评论吧 !
