

HarmonyOS CPU与I/O密集型任务开发指导
电子说
描述
一、CPU密集型任务开发指导
CPU密集型任务是指需要占用系统资源处理大量计算能力的任务,需要长时间运行,这段时间会阻塞线程其它事件的处理,不适宜放在主线程进行。例如图像处理、视频编码、数据分析等。
基于多线程并发机制处理CPU密集型任务可以提高CPU利用率,提升应用程序响应速度。
当进行一系列同步任务时,推荐使用Worker;而进行大量或调度点较为分散的独立任务时,不方便使用8个Worker去做负载管理,推荐采用TaskPool。接下来将以图像直方图处理以及后台长时间的模型预测任务分别进行举例。
使用TaskPool进行图像直方图处理
1. 实现图像处理的业务逻辑。
2. 数据分段,将各段数据通过不同任务的执行完成图像处理。
创建Task,通过execute()执行任务,在当前任务结束后,会将直方图处理结果同时返回。
3. 结果数组汇总处理。
import taskpool from '@ohos.taskpool';
@Concurrent
function imageProcessing(dataSlice: ArrayBuffer) {
// 步骤1: 具体的图像处理操作及其他耗时操作
return dataSlice;
}
function histogramStatistic(pixelBuffer: ArrayBuffer) {
// 步骤2: 分成三段并发调度
let number = pixelBuffer.byteLength / 3;
let buffer1 = pixelBuffer.slice(0, number);
let buffer2 = pixelBuffer.slice(number, number * 2);
let buffer3 = pixelBuffer.slice(number * 2);
let task1 = new taskpool.Task(imageProcessing, buffer1);
let task2 = new taskpool.Task(imageProcessing, buffer2);
let task3 = new taskpool.Task(imageProcessing, buffer3);
taskpool.execute(task1).then((ret: ArrayBuffer[]) = > {
// 步骤3: 结果处理
});
taskpool.execute(task2).then((ret: ArrayBuffer[]) = > {
// 步骤3: 结果处理
});
taskpool.execute(task3).then((ret: ArrayBuffer[]) = > {
// 步骤3: 结果处理
});
}
@Entry
@Component
struct Index {
@State message: string = 'Hello World'
build() {
Row() {
Column() {
Text(this.message)
.fontSize(50)
.fontWeight(FontWeight.Bold)
.onClick(() = > {
let data: ArrayBuffer;
histogramStatistic(data);
})
}
.width('100%')
}
.height('100%')
}
}
使用Worker进行长时间数据分析
本文通过某地区提供的房价数据训练一个简易的房价预测模型,该模型支持通过输入房屋面积和房间数量去预测该区域的房价,模型需要长时间运行,房价预测需要使用前面的模型运行结果,因此需要使用Worker。
1. DevEco Studio提供了Worker创建的模板,新建一个Worker线程,例如命名为“MyWorker”。
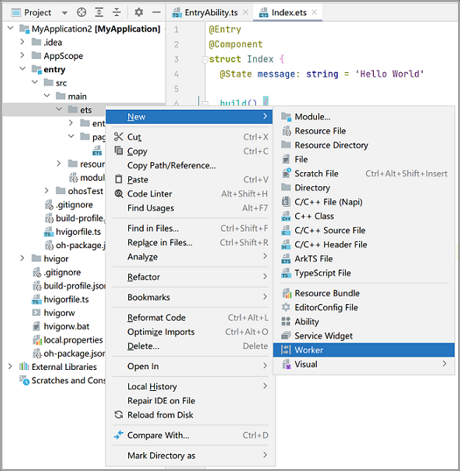
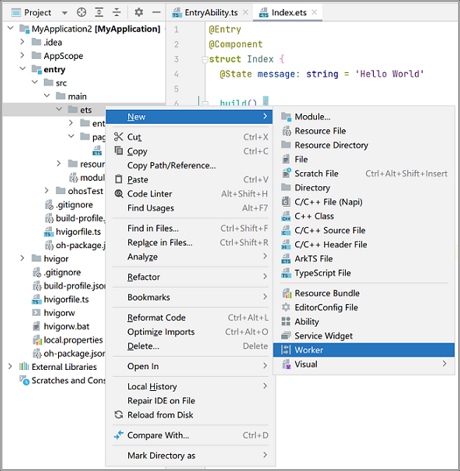
2. 在主线程中通过调用ThreadWorker的constructor()方法创建Worker对象,当前线程为宿主线程。
import worker from '@ohos.worker';
const workerInstance = new worker.ThreadWorker('entry/ets/workers/MyWorker.ts');
3. 在宿主线程中通过调用onmessage()方法接收Worker线程发送过来的消息,并通过调用postMessage()方法向Worker线程发送消息。
例如向Worker线程发送训练和预测的消息,同时接收Worker线程发送回来的消息。
// 接收Worker子线程的结果
workerInstance.onmessage = function(e) {
// data:主线程发送的信息
let data = e.data;
console.info('MyWorker.ts onmessage');
// 在Worker线程中进行耗时操作
}
workerInstance.onerror = function (d) {
// 接收Worker子线程的错误信息
}
// 向Worker子线程发送训练消息
workerInstance.postMessage({ 'type': 0 });
// 向Worker子线程发送预测消息
workerInstance.postMessage({ 'type': 1, 'value': [90, 5] });
4. 在MyWorker.ts文件中绑定Worker对象,当前线程为Worker线程。
import worker, { ThreadWorkerGlobalScope, MessageEvents, ErrorEvent } from '@ohos.worker';
let workerPort: ThreadWorkerGlobalScope = worker.workerPort;
5. 在Worker线程中通过调用onmessage()方法接收宿主线程发送的消息内容,并通过调用postMessage()方法向宿主线程发送消息。
如在Worker线程中定义预测模型及其训练过程,同时与主线程进行信息交互。
import worker, { ThreadWorkerGlobalScope, MessageEvents, ErrorEvent } from '@ohos.worker';
let workerPort: ThreadWorkerGlobalScope = worker.workerPort;
// 定义训练模型及结果
let result;
// 定义预测函数
function predict(x) {
return result[x];
}
// 定义优化器训练过程
function optimize() {
result = {};
}
// Worker线程的onmessage逻辑
workerPort.onmessage = function (e: MessageEvents) {
let data = e.data
// 根据传输的数据的type选择进行操作
switch (data.type) {
case 0:
// 进行训练
optimize();
// 训练之后发送主线程训练成功的消息
workerPort.postMessage({ type: 'message', value: 'train success.' });
break;
case 1:
// 执行预测
const output = predict(data.value);
// 发送主线程预测的结果
workerPort.postMessage({ type: 'predict', value: output });
break;
default:
workerPort.postMessage({ type: 'message', value: 'send message is invalid' });
break;
}
}
6. 在Worker线程中完成任务之后,执行Worker线程销毁操作。销毁线程的方式主要有两种:根据需要可以在宿主线程中对Worker线程进行销毁;也可以在Worker线程中主动销毁Worker线程。
在宿主线程中通过调用onexit()方法定义Worker线程销毁后的处理逻辑。
// Worker线程销毁后,执行onexit回调方法
workerInstance.onexit = function() {
console.info("main thread terminate");
}
方式一:在宿主线程中通过调用terminate()方法销毁Worker线程,并终止Worker接收消息。
// 销毁Worker线程 workerInstance.terminate();
方式二:在Worker线程中通过调用close()方法主动销毁Worker线程,并终止Worker接收消息。
// 销毁线程 workerPort.close();
二、 I/O密集型任务开发指导
使用异步并发可以解决单次I/O任务阻塞的问题,但是如果遇到I/O密集型任务,同样会阻塞线程中其它任务的执行,这时需要使用多线程并发能力来进行解决。
I/O密集型任务的性能重点通常不在于CPU的处理能力,而在于I/O操作的速度和效率。这种任务通常需要频繁地进行磁盘读写、网络通信等操作。此处以频繁读写系统文件来模拟I/O密集型并发任务的处理。
1. 定义并发函数,内部密集调用I/O能力。
import fs from '@ohos.file.fs';
// 定义并发函数,内部密集调用I/O能力
@Concurrent
async function concurrentTest(fileList: string[]) {
// 写入文件的实现
async function write(data, filePath) {
let file = await fs.open(filePath, fs.OpenMode.READ_WRITE);
await fs.write(file.fd, data);
fs.close(file);
}
// 循环写文件操作
for (let i = 0; i < fileList.length; i++) {
write('Hello World!', fileList[i]).then(() = > {
console.info(`Succeeded in writing the file. FileList: ${fileList[i]}`);
}).catch((err) = > {
console.error(`Failed to write the file. Code is ${err.code}, message is ${err.message}`)
return false;
})
}
return true;
}
2. 使用TaskPool执行包含密集I/O的并发函数:通过调用execute()方法执行任务,并在回调中进行调度结果处理。示例中的filePath1和filePath2的获取方式请参见获取应用文件路径。
import taskpool from '@ohos.taskpool';
let filePath1 = ...; // 应用文件路径
let filePath2 = ...;
// 使用TaskPool执行包含密集I/O的并发函数
// 数组较大时,I/O密集型任务任务分发也会抢占主线程,需要使用多线程能力
taskpool.execute(concurrentTest, [filePath1, filePath2]).then((ret) = > {
// 调度结果处理
console.info(`The result: ${ret}`);
})
审核编辑 黄宇
-
鸿蒙原生应用开发-ArkTS语言基础类库多线程CPU密集型任务TaskPool2024-03-19 0
-
鸿蒙原生应用开发-ArkTS语言基础类库多线程I/O密集型任务开发2024-03-21 0
-
【HarmonyOS】HarmonyOS子系统开发指导2020-09-21 0
-
计算密集型的程序简析2021-09-07 0
-
HarmonyOS如何使用异步并发能力进行开发2023-09-22 0
-
HarmonyOS CPU与I/O密集型任务开发指导2023-09-26 0
-
基于GoKit的产品开发指导2015-11-16 572
-
ZigBee2007视频教程-应用开发指导2015-12-29 789
-
FPGA执行计算密集型任务性能表现及优势有哪些2022-11-10 724
-
HarmonyOS语言基础类库开发指南上线啦!2023-10-18 273
-
HarmonyOS后台任务管理开发指南上线!2023-11-28 412
-
鸿蒙OS开发实例:【ArkTS类库多线程I/O密集型任务开发】2024-04-01 108
-
鸿蒙OS开发实例:【ArkTS类库多线程CPU密集型任务TaskPool】2024-04-01 326
全部0条评论

快来发表一下你的评论吧 !
