

佐思汽研发布《2023-2024年汽车AI大模型技术和应用趋势报告》
描述
2023年以来,越来越多车型开始接入大模型,越来越多Tier1推出汽车大模型解决方案。特斯拉FSD V12的出色进展和SORA的推出,更加速了AI大模型在座舱和智驾领域的落地。
端到端自动驾驶大模型的发展突飞猛进
2023年2月,采用端到端自动驾驶模型的特斯拉FSD v12.2.1已经开始陆续在美开启推送,不仅仅是员工和测试人员。根据首批客户的反馈,FSD V12 相当强大,让以前不相信不敢用自动驾驶的普通人也敢于使用FSD了。譬如,特斯拉 FSD V12 可绕行路边积水,一位特斯拉的工程师评论说:这种开法很难用明确的代码来实现,但特斯拉的端到端方案几乎毫不费力地实现了。
自动驾驶AI大模型的发展可以分为四个阶段:
1.0时代就是在感知层面使用大模型(Transformer);
2.0时代就是模块化,感知规控决策都用大模型;
3.0时代就是端到端大模型(一“端”是传感器的原始数据,另一“端”直接输出驾驶动作);
4.0时代就是从垂直领域的人工智能走向通用领域的人工智能(AGI的世界模型)。
现在多数公司处于2.0时代。特斯拉FSD V12已处于3.0时代。其他主机厂和Tier1纷纷跟进FSD V12的端到端大模型。2024年1 月 30 日,小鹏汽车宣布,小鹏的端到端模型下一步将会全面上车。据悉,蔚来和理想的“基于端到端”自动驾驶模型也将在2024年上线。
FSD V12驾驶决策交由AI算法生成,用海量视频数据训练出的端到端神经网络,替换掉了超过30万行C++代码。FSD V12提供了一条有待验证的全新路径,若得以走通,将对行业产生颠覆性影响。
2月16日,OpenAI发布文本生成视频模型SORA,标志着AI视频应用即将大规模应用的前夜。SORA不仅支持通过文本或图像生成长达60秒的视频,其视频生成能力、复杂场景和角色生成能力、以及对物理世界模拟的能力,都显著超越了之前的技术。
SORA和FSD V12都是通过视觉让AI能够理解甚至模拟真实的物理世界。Elon Mask认为,“FSD 12和Sora不过是AI通过视觉认知世界、理解世界上的两个开花结果,FSD最终用于驾驶行为,Sora则是用来生成视频。”
SORA的爆火,进一步证明了FSD V12的合理性。马斯克称「特斯拉已经能够制作真实世界视频大约一年了」。
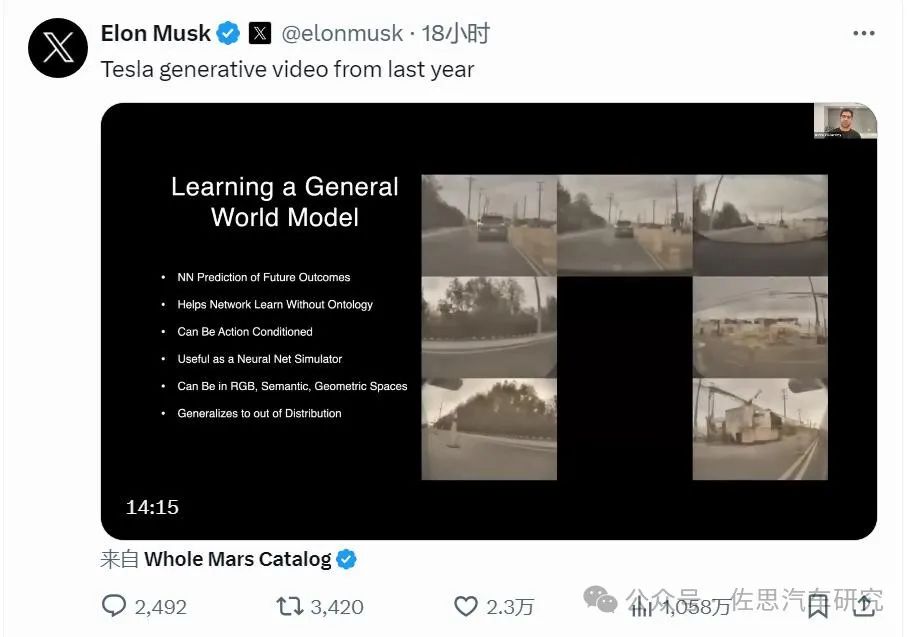
来源:Twitter
AI大模型快速演化,带来全新机会
最近三年,自动驾驶大模型经历了若干次的演化,领先车企的自动驾驶系统几乎每年要重写一次。这也给后来者提供了切入机会。
CVPR2023上,商汤、OpenDriveLab、地平线等联合发布的端到端的自动驾驶算法UniAD,获得了2023年的最佳论文。
2024年初,中科慧拓技术团队和中科院自动化所共同提出的生成式端到端自动驾驶模型GenAD,将生成式人工智能(Generative AI)和端到端自动驾驶技术结合,是业界首个生成式端到端自动驾驶模型。该技术颠覆了UniAD的渐进式流程端到端方案,探讨了一种新的端到端自动驾驶范式,关键在于采用生成式人工智能的方式预测自车和周围环境在过去场景中的时序演变方式。 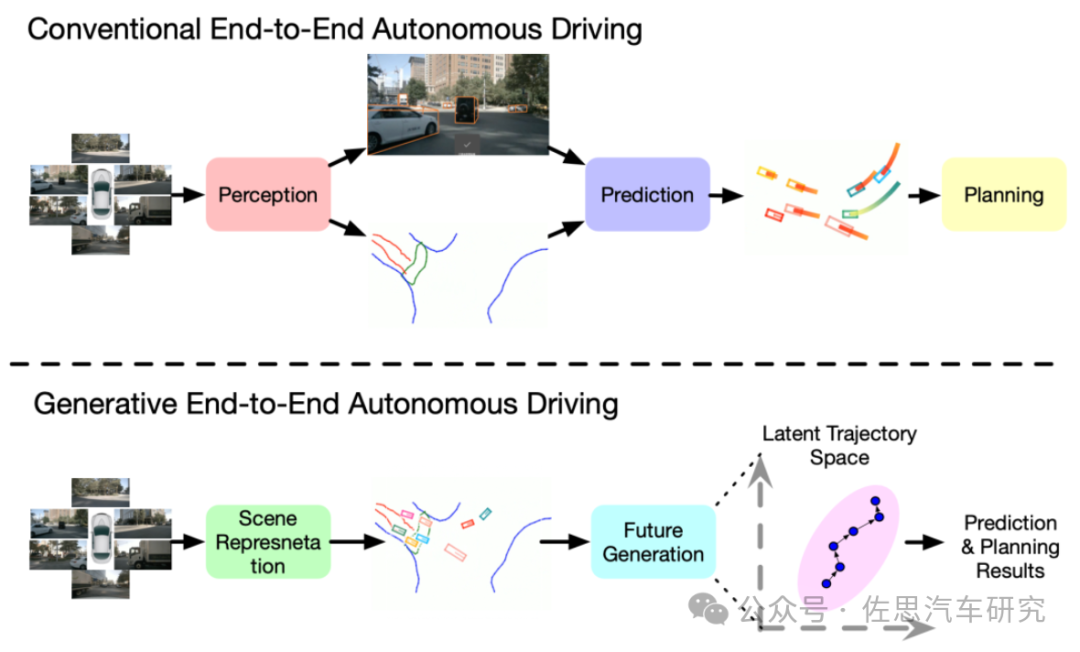
来源:中科慧拓
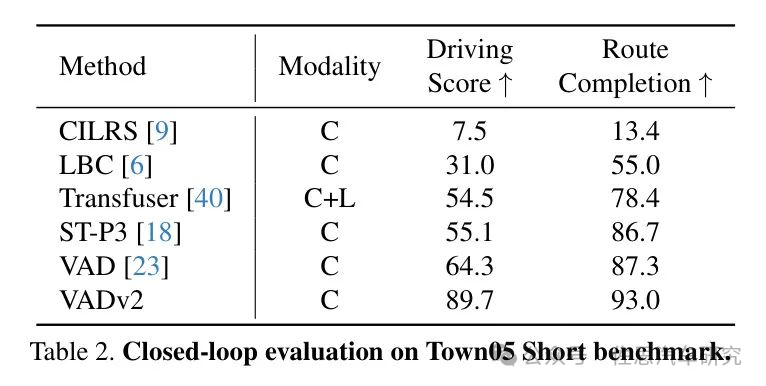
2024年2月,地平线和华中科技大学提出了VADv2,一个基于概率规划的端到端驾驶模型。VADv2以流方式输入多视角图像序列,将传感器数据转换为环境标记嵌入,输出动作的概率分布,并从中采样一个动作来控制车辆。仅使用摄像头传感器,VADv2在CARLA Town05基准测试中实现了最先进的闭环性能,显著优于所有现有方法。它能够在完全端到端的方式下稳定运行,甚至不需要基于规则的封装。
来源:地平线
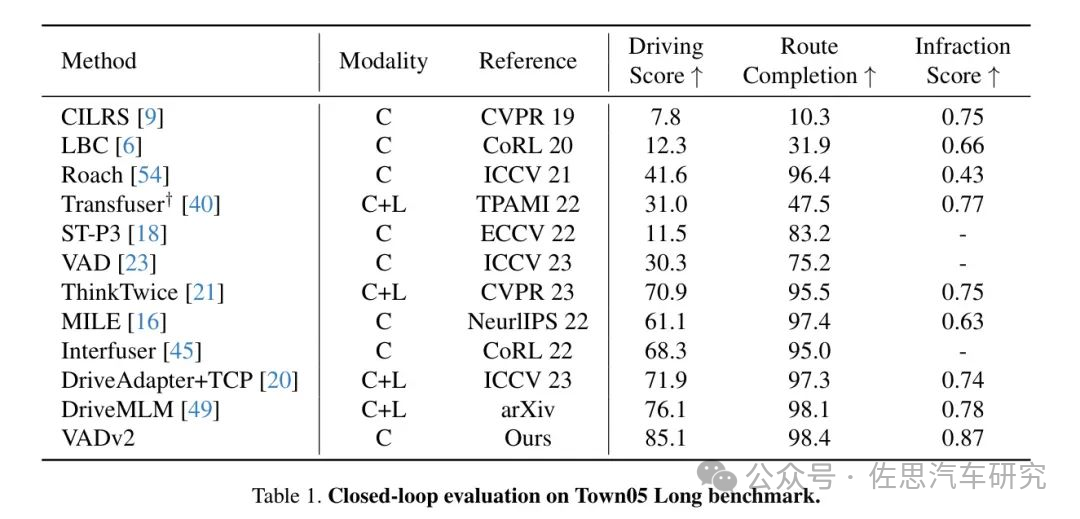
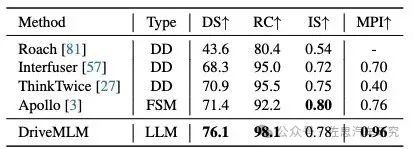
在Town05长距离基准测试中,VADv2取得了85.1的驾驶分数,98.4的路程完成度,以及0.87的违规分数,如表1所示。与之前的最先进方法相比,VADv2在路程完成度更高的同时,显著提高了驾驶分数,增加了9.0。值得注意的是,VADv2仅使用摄像头作为感知输入,而DriveMLM同时使用了摄像头和激光雷达。此外,与之前仅依赖摄像头最佳方法相比,VADv2显示出更大的优势,驾驶分数的显著提高达到了16.8。
来源:地平线
也是在2024年2月,清华大学交叉信息研究院和理想汽车提出了 DriveVLM。DriveVLM的整体流程如下图所示。一系列图像被大型视觉语言模型(VLM)处理,以执行特定的链式思维(CoT)推理,得出驾驶规划结果。这个大型VLM包括一个视觉编码器和一个大型语言模型(LLM)。
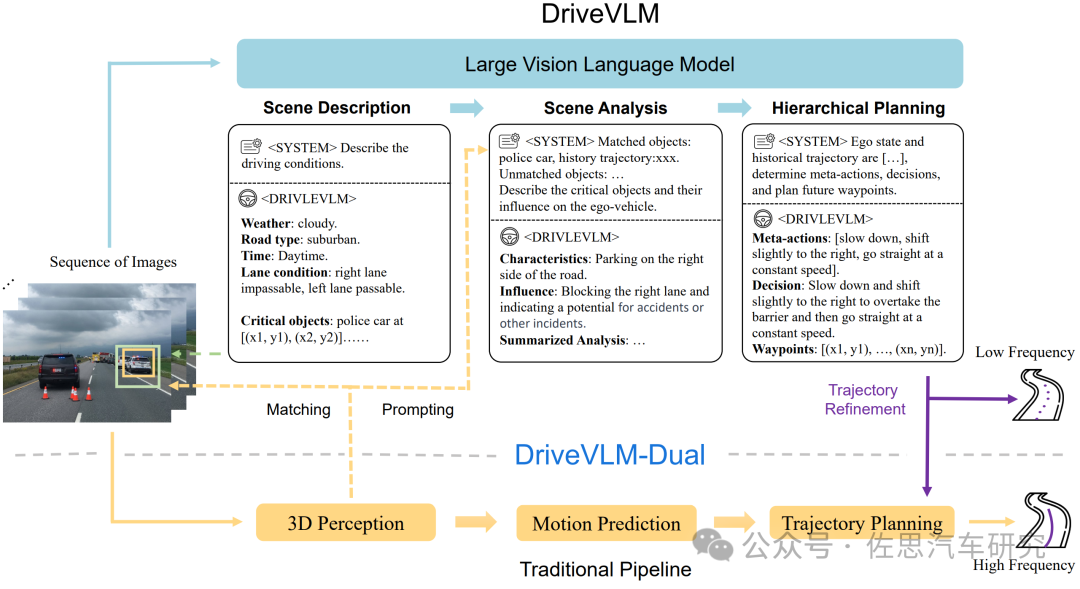
来源:清华大学交叉信息研究院
由于VLMs在空间推理和高计算需求方面的局限性,DriveVLM团队又提出了DriveVLM-Dual,一个结合了DriveVLM与传统自主驾驶流水线优势的混合系统。DriveVLM-Dual可选择性地将DriveVLM与传统的3D感知和规划模块相结合,例如3D目标检测器、占用网络和运动规划器,使系统能够实现3D定位和高频规划能力。这种双重系统设计,类似于人脑的慢速和快速思考过程,能够有效适应驾驶场景中不断变化的复杂性。
大模型兴起,AI和云计算公司受关注
AI大模型兴起,算力、算法和数据三者缺一不可。擅长算法,储备了大量算力的AI公司(如科大讯飞、商汤科技、旷视科技等),以及具备强大智算中心的云计算公司(如浪潮、火山引擎、腾讯云等)受到主机厂关注。
商汤在AI大模型领域布局了座舱多模态大模型SenseChat-Vision、AIDC智算中心(6000P算力)、自动驾驶大模型DriveMLM。2024年初,商汤推出DriveMLM,在闭环测试最权威榜单CARLA上取得很好的成绩。DriveMLM是介于模块化和端到端方案之间的中间方案,具备可解释性。
来源:商汤科技
在自动驾驶的Corner Case采集上,火山引擎和毫末智行一起将大模型应用在场景生成和标注提效上。在火山引擎提供的云服务能力支持下,毫末DriveGPT大模型的预标注,整体效率提升了10倍。
2023年,腾讯发布了在智能汽车云、智驾云图、智能座舱等领域的升级产品和方案。算力方面,腾讯智能汽车云带来3.2Tbps带宽,算力性能提升3倍,通信性能提升10倍,计算集群GPU利用率提升60%以上,为智能驾驶大模型训练提供高带宽、低延迟的智算能力支撑。
在训练加速方面,腾讯智能汽车云结合太极Angel训练加速框架,训练速度相比业界主流框架提高1倍,推理速度相比业界主流框架提升1.3倍。博世、蔚来汽车、英伟达、奔驰、文远知行等企业目前都是腾讯智能汽车云的用户。2024年,腾讯将进一步加强AI大模型的建设。
审核编辑:刘清
-
OpenHarmony社区运营报告(2023年12月)2024-01-10 0
-
2024年小米汽车产业链分析及新品上市全景洞察报告2024-03-29 0
-
飞思卡尔智能汽车技术报告2014-07-29 0
-
2018上海国际汽车轻质技术展2017-11-29 0
-
清华出品:最易懂的AI芯片报告!人才技术趋势都在这里 精选资料分享2021-07-23 0
-
展望2023年,制造业技术的五大趋势2023-02-16 0
-
OpenHarmony社区运营报告(2023年2月)2023-03-28 0
-
OpenHarmony社区运营报告(2023年3月)2023-04-14 0
-
OpenHarmony社区运营报告(2023年4月)2023-05-22 0
-
OpenHarmony社区运营报告(2023年7月)2023-08-11 0
-
混合动力汽车研究:电动化计划推迟 PHEV&增程式占比将抬升至40%2024-01-25 1436
-
长安汽车发布2023-2024产品规划及销量目标2024-02-03 319
-
华域汽车系统股份有限公司发布2023年年度报告2024-03-29 216
-
2024中国AI大模型产业发展报告2024-03-30 437
-
《2024智能汽车技术与研发测试洞察报告》发布2024-04-17 481
全部0条评论

快来发表一下你的评论吧 !
