

Arm Neoverse CSS N3助力快速实现出色能效
描述
突破传统基础设施
从云到边缘,Arm Neoverse 正凭借出色的性能、效率、设计灵活性和总体拥有成本 (TCO) 优势,革新传统基础设施芯片领域。
云和超大规模服务运营商正不断增大计算密度。随着 Microsoft Cobalt、阿里巴巴的倚天 710、AmpereOne等配置 128 核或以上的 CPU 设计进入市场,单个封装可实现的性能更强,且下一代的目标还将远高于 128 核。
随着 CPU 性能逐步提高,市场对人工智能 (AI)、网络和加密加速器等专用计算的需求也随之持续增长。这显然需要将这些加速器集成在一起,才能更有效地提高性能和效率,与此同时,还需实现模块化设计,以便将加速器与不同的通用计算引擎进行混合搭配。
基于 Neoverse N3 CPU 的Neoverse CSS N3
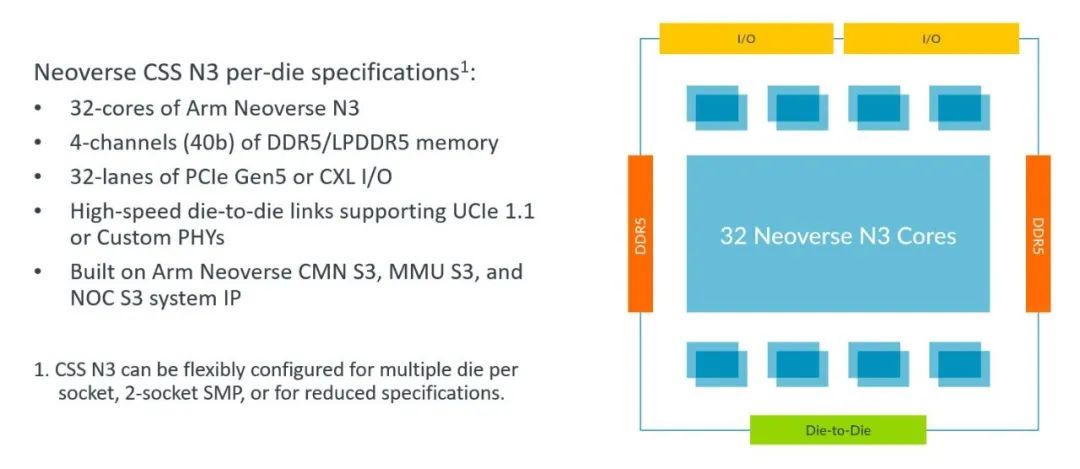
图 1:Neoverse CSS N3 概览
Arm Neoverse 计算子系统 (CSS) 支持在新的工艺节点上快速开发先进的系统级芯片 (SoC)。通过在设计中使用预配置、预验证的 CSS,合作伙伴节省了 80 人/年的工程师时间,以及相应的机会成本,使其能够专注于实现助其系统增值的“秘密法宝”。
Neoverse CSS N3 构建在 Neoverse CSS N2 经过市场验证的优良表现之上,能通过新的架构功能提供更高的性能和效率,为数据中心市场带来更优越的单芯片性能和单 TCO 性能表现。此外,Neoverse CSS N3 还为边缘和网络应用带来了出色的效率。CSS N3 以 Neoverse S3 系统 IP 为基础,Neoverse S3 系统 IP 包括了一致性网状网络 CMN S3、系统内存管理单元 MMU S3 和片上网络 NOC S3。此外,CSS N3 还包含系统管理和本地控制处理器,以及 CPU 和系统 IP 协同设计与共同开发,以优化 PPA 和系统级功能的支持。
Neoverse CSS N3 支持 32 颗 Neoverse N3 核心,可在低至 40W 的功率范围内实现优异性能。该产品具备高度可配置性,适用于电信、数据处理单元 (DPU) 、网络和云等多个领域,可以在 8 核至 32 核之间进行扩展配置。
除了性能和效率的大幅提升之外,Neoverse CSS N3 还支持基于芯粒的设计。它支持 UCIe 晶粒间 (die-to-die) 连接标准,结合 Arm 新的 AMBA CHI C2C 协议,为构建异构加速计算奠定了基础。可以预见的是,Arm Neoverse CSS N3 将在当今专用计算领域蓬勃发展。
基于 CSS N3 的芯粒可通过 AMBA CHI C2C 连接到 I/O 一致性加速器,从而将加速器封装在一起,进一步提高性能和效率,这一方法可用来取代传统的解决方案。在过往的解决方案中,其加速器是通过 PCIe 进行板级连接,这会导致更高的延迟、软件复杂性和功耗。
Neoverse N3 CPU优异的效率表现
以每瓦性能来衡量的性能效率是 CPU 评估的一大关键指标。5G/6G 无线基础设施要求现代计算解决方案表现出更高的性能,同时功耗预算须保持不变。新一代的 DPU 需要配备功能更强大的 CPU,以便在 PCIe 设备规范的限制内运行成熟的操作系统、虚拟机、容器及其他数据包处理功能。头部云服务提供商正着手在机架的冷却能力范围内,部署核心数量更多、更密集的 CPU。“能效”几乎是所有细分市场的主要设计决策要素。Neoverse N3 便是以能效作为其设计核心。
Neoverse N3 CPU 延续了 Neoverse N2 经过市场验证的效率表现。经过 Arm CPU 设计团队的不懈努力,他们强化了分支预测器、预取器的性能,并优化了微架构,进而实现了效率的提升。此外,他们还改进了电源管理表现,增加了精度更高的每核动态电压频率调整 (DVFS) 功能,以实现更出色的性能效率。这些工作成果使得 N3 在效率表现上比上一代产品提高了 20% 以上。
Neoverse N3 可以满足多样的 SoC 设计要求,包括 16 核网络设计、32 核电信 RAN 或云 DPU 设计,以及 192 核超大规模和云 CPU 等等。Neoverse N3 还提供了多种电压和频率选择,与 Neoverse N2 相比,其每核性能效率提高了 20% 至近 50%。

图 1:Arm Neoverse N3 CPU
延续卓越效率表现
在面积和功耗配置与 Neoverse N2 大致相同,且采用一样的工艺节点下,Neoverse N3 在机器学习 (ML) 和数据分析工作负载方面的性能约提升了三倍,在 SQL 数据库、选定压缩应用程序,以及整数运算性能等方面分别约提升了 1.3 倍、1.2 倍,以及 1.1 倍的性能。
灵活的缓存配置
Neoverse N3 提供多种缓存配置,可满足不同计算场景的需求。许多横向扩展的云数据分析和数据库应用均能从更靠近核心的较大缓存中受益,因此我们为这一细分领域推出了 2MB L2 缓存选项。此外,1MB L2 缓存选项主要针对 5G/6G 无线基础设施、企业网络、DPU 和智能网卡 (SmartNIC) 以及超大规模服务器等各种任务中的通用计算,能够实现性能和面积的良好平衡;而较小的 32KB L1 和 128KB 则适合那些对缓存不敏感,但仍希望能以较小占用空间提供良好算力的工作负载。
总结
Neoverse N3 CPU 的推出实现了 Neoverse N 系列持续提供出色的每瓦性能的目标。新的 CSS N3 结合了 Neoverse N3 优异的性能和效率与 Neoverse S3 系统 IP,成为一套定制性更强的计算子系统。与上一代的 CSS 相比,Neoverse CSS N3的每瓦性能可提高 20% 至近 50%。CSS N3 平台适用于云到边缘设计,可帮助我们的合作伙伴将 Arm 强大的处理器与加密、网络或 AI 加速器等等多种专用组件结合在一起,打造更具差异性的新产品。
我们的合作伙伴将有望在 2024 年底推出基于 Neoverse N3 和 CSS N3 的创新芯片设计,让我们共同翘首以待。
审核编辑:刘清
-
2014 OPPO N3 新品发布会2014-10-28 0
-
ARM Neoverse N1 Core性能分析方法2023-08-09 0
-
Arm Neoverse N1软件优化指南2023-08-11 0
-
Arm Neoverse™ N1 PMU指南2023-08-12 0
-
ARM Neoverse™N1核心技术参考手册2023-08-29 0
-
ARM Neoverse™N2核心技术参考手册2023-08-29 0
-
努比亚N3惊艳发布 续航表现非常出色2018-03-09 2577
-
智原与Arm合作提供基于Arm Neoverse CSS的设计服务2024-01-10 669
-
Arm 更新 Neoverse 产品路线图,实现基于 Arm 平台的人工智能基础设施2024-02-22 315
-
Arm发布新一代Neoverse数据中心计算平台,AI负载性能显著提升2024-02-22 623
-
Arm发布Neoverse V3和N3 CPU内核2024-02-27 846
-
Neoverse CSS V3助力云计算实现TCO优化的机密计算2024-03-14 463
-
Arm Neoverse CSS N3 助力快速实现出色能效2024-03-26 384
-
Arm Neoverse CSS V3 助力云计算实现 TCO 优化的机密计算2024-03-26 269
-
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N32024-04-24 935
全部0条评论

快来发表一下你的评论吧 !
