

适配器微调在推荐任务中的几个关键因素
描述
本文对基于适配器的可迁移推荐系统进行了实验探索和深入研究。发现在文本推荐方面,基于适配器的可迁移推荐取得了有竞争力的结果;在图像推荐方面,基于适配器的可迁移推荐略落后于全量微调。后续本文对四种著名的适配器微调方法进行了基准测试,并深入研究了可能影响适配器微调在推荐任务中的几个关键因素。

论文题目:
Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights
论文链接:
https://arxiv.org/abs/2305.15036
代码链接:
https://github.com/westlake-repl/Adapter4Rec/
研究动机
可迁移的推荐系统 (TransRec) 通常包含一个用户编码器和一个或多个基于模态的物品编码器,其中基于模态的物品编码器通常是经过预训练的 ViT, BERT, RoBERTA, 与 GPT 等模型,他们往往包含很大的参数量。常见使用 TransRec 的范式是先经过一个源域数据集的预训练之后再迁移到目标域,迁移的过程往往都需要再进行微调。
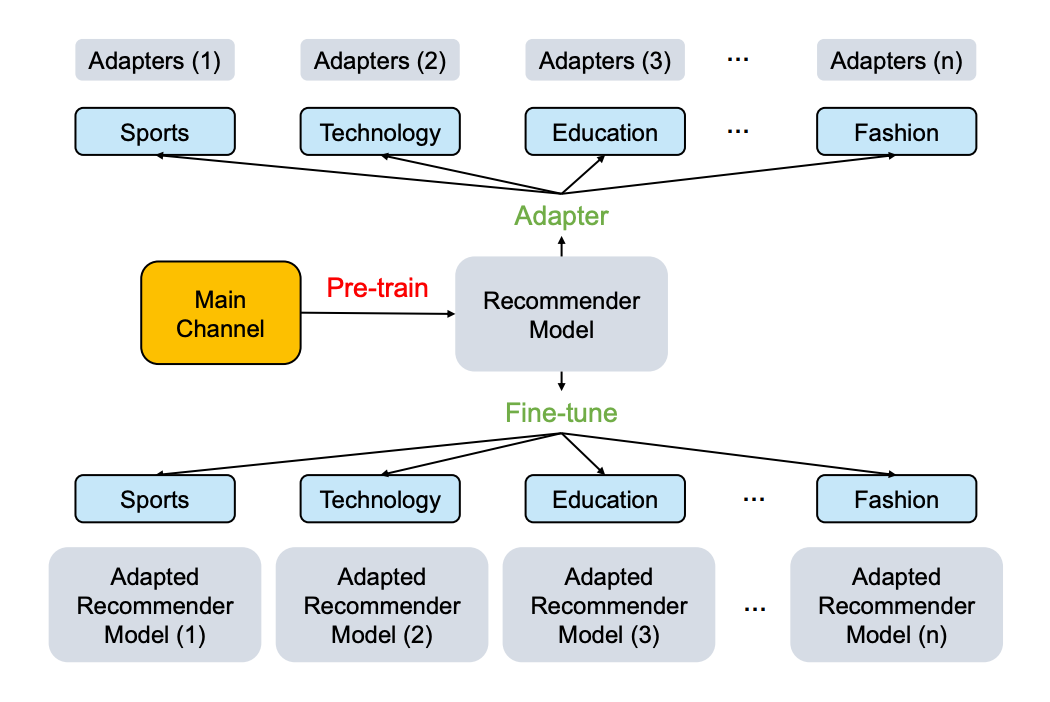
传统的全参数微调 (Fine-tune All, FTA) 是很有效的方式,但它存在如下几个问题:
1. 如上图所示,推荐系统往往都包含一个主频道和多个垂直频道,如果想利用主频道预训练过的模型迁移至每个垂直频道,则每个垂直通道的模型更新、维护和存储都需要很多额外成本;
2. 全参数微调往往存在过拟合问题;
3. 昂贵的训练成本,往往微调越大的模型所需要的 GPU 显存越高。
这促使研究者们在 TransRec 中探索基于适配器 (Adapter) 的高效微调范式 (Adapter tuning, AdaT) 。AdaT 与传统 FTA 的比较如下图所示,AdaT 仅仅微调新插入的适配器和对应的 layer-normalization 层:
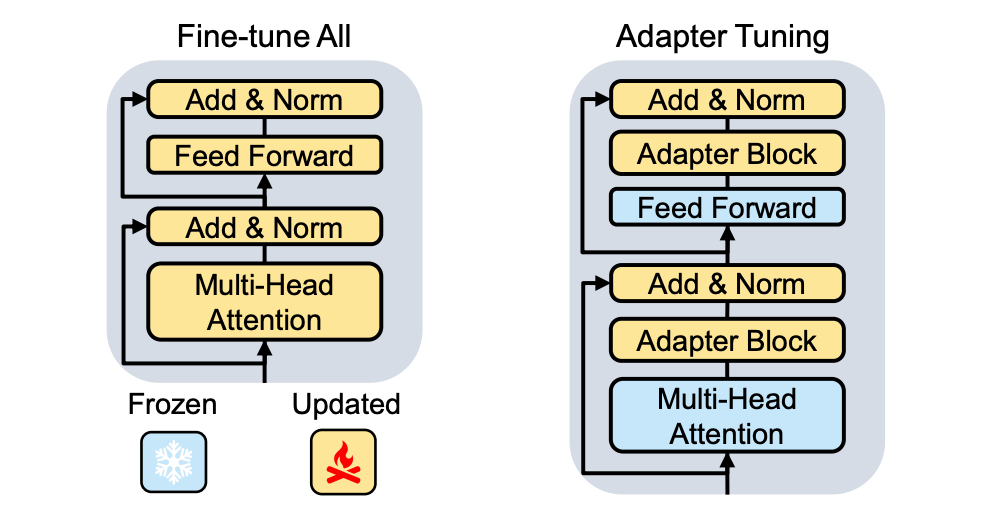
适配器是一种在 NLP 和 CV 中广泛采用的参数高效方法用于解决高效迁移大规模基础模型,然而在当前 TransRec 范式的推荐系统领域并没有被系统的探究过该方法的有效性。针对于该有效性的探究,论文提出如下几个关键研究问题:
RQ1: 基于适配器的 TransRec 性能上能否与典型的基于微调的 TransRec 相当?该结论适用于不同模态的场景吗?
RQ2: 如果 RQ1 为正确或部分正确,那么这些 NLP 和 CV 社区当中流行的适配器性能又如何呢?
RQ3: 是否有因素影响这些基于适配器的 TransRec 模型的性能?
针对于 RQ1, 论文在两种物品模态(即文本和图像)上对基于适配器和基于全参数微调的 TransRec 进行了严格的比较研究。其中包括采用两种流行的推荐架构(即 SASRec 和 CPC)以及四种强大的模态编码(即 BERT、RoBERTa、ViT 和 MAE)。
针对于 RQ2, 论文对 NLP 和 CV 中广泛采用的四种适配器进行了基准测试。还加入了 LoRA、Prompt-tuning 和 layer-normalization tuning 的结果,以进行综合比较。
针对于 RQ3, 该文章进行了不同策略的性能比较,这些策略包括插入适配器的方式和位置,以及是否调整相应的 layer-normalization 等。除此之外,论文还研究了 TransRec 在源域和目标域中的数据缩放效应,以考察在使用较大数据集预训练 TransRec 时 AdaT 的有效性。
网络架构
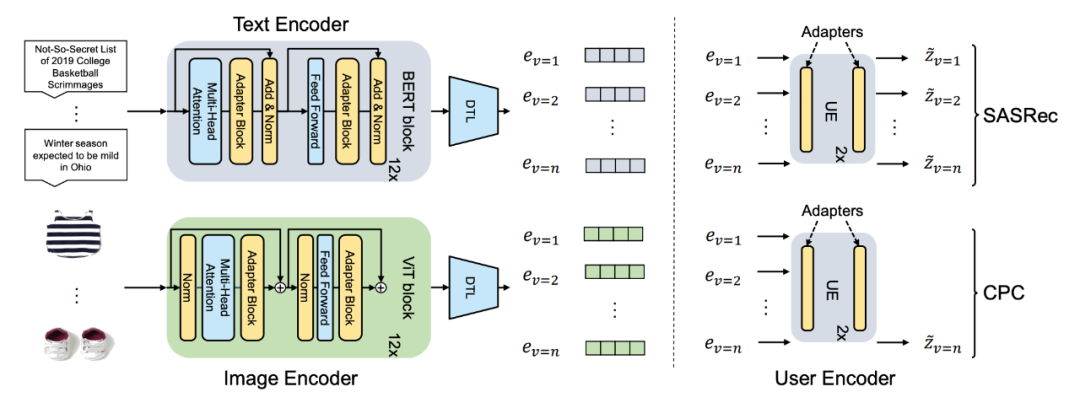
TransRec 架构包含两个子模块,即物品编码器和用户编码器,这两个模块都基于 Transformer 模块。论文采用插入适配器到物品和用户编码器当中。基于适配器的 TransRec 架构如下图所示。论文采用 SASRec 和 CPC 框架对 TransRec 进行二元交叉熵 (BCE) 损失训练。
实验设置
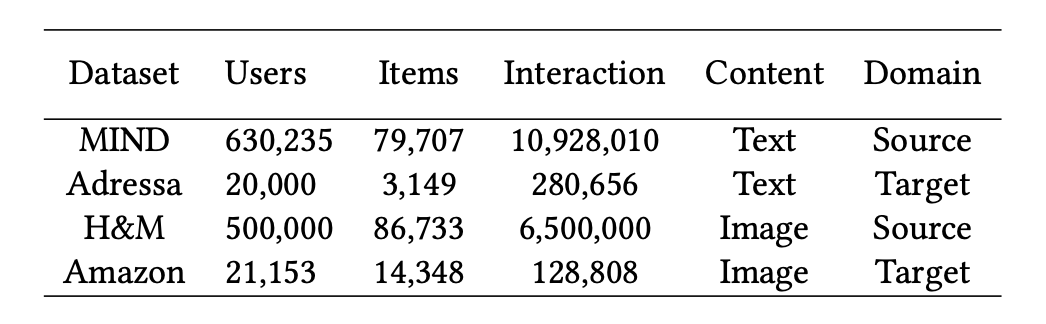
数据集:论文用两种模式对基于适配器的 TransRec 进行了评估。对于具有文本模态的物品,使用 MIND 英语新闻推荐数据集作为源域,并使用 Adressa 挪威语新闻推荐数据集作为目标域。对于视觉模态,使用亚马逊用于服装和鞋类的评论数据集作为目标域,并使用 H&M 个性化时尚推荐数据集作为源域。
预训练模型的使用:文本模态采用 bert-base-uncased 和 roberta-base 模型;图片模态采用 vit-base-patch16-224 和 vit-mae-base 模型。
评价标准:论文采用 "leave-one-out"的策略来分割数据集:交互序列中的最后一项用于评估,最后一项之前的一项用于验证,其余的用于训练。评估指标采用 HR@10(命中率)和 NDCG@10(归一化累计收益)。所有实验结果均为测试集的结果。
主要发现
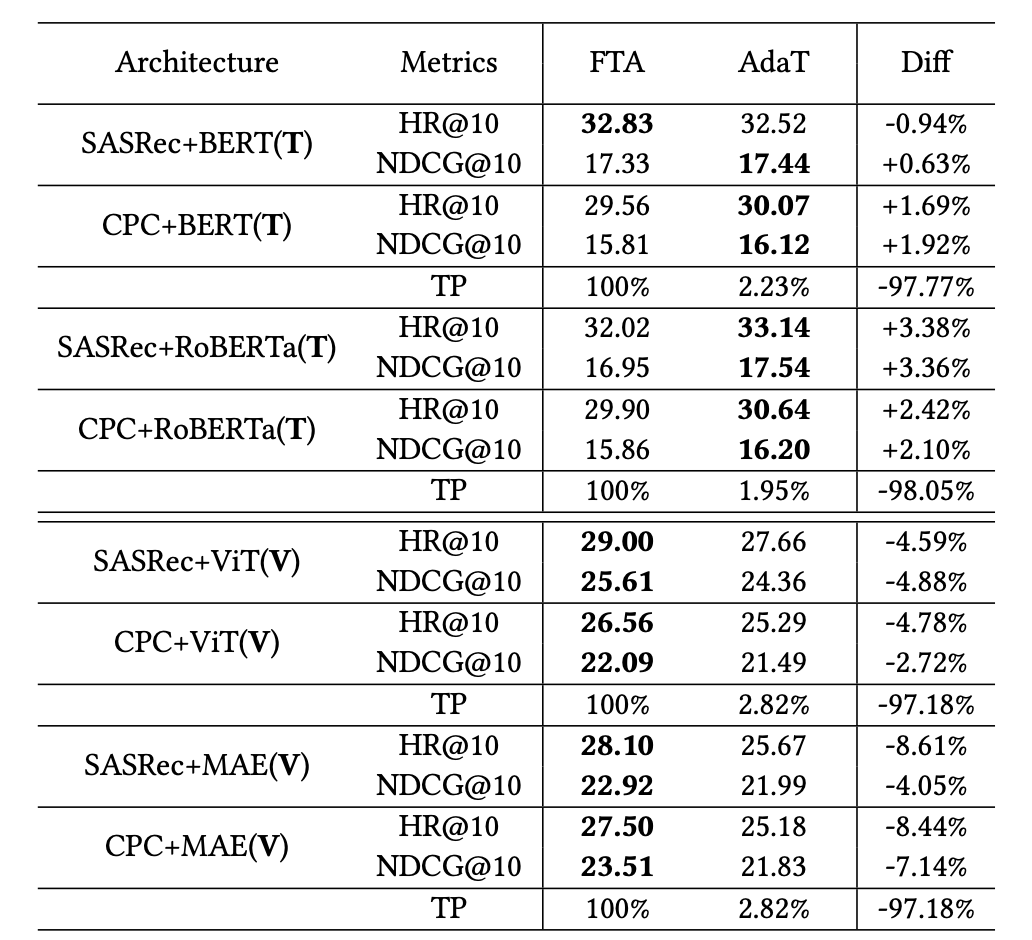
RQ1: 在文本内容中,使用 AdaT 的 TransRec 可获得与 FTA 相当的性能,但在视觉场景中性能有所下降。
对比 FTA 和 AdaT 在文本和图片场景下的实验结果如下表所示:
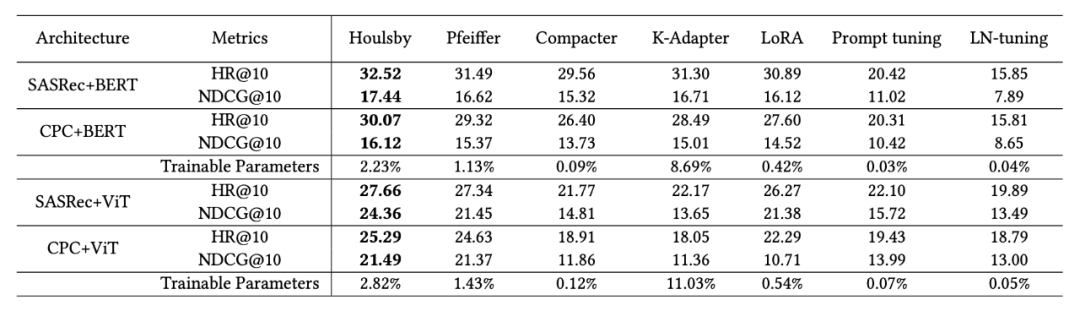
RQ2: 与其他流行的参数高效微调的方法相比,经典的Houlsby 适配器在 TransRec 中取得了最佳效果。
对比常用不同的参数高效微调方法的基准测试:
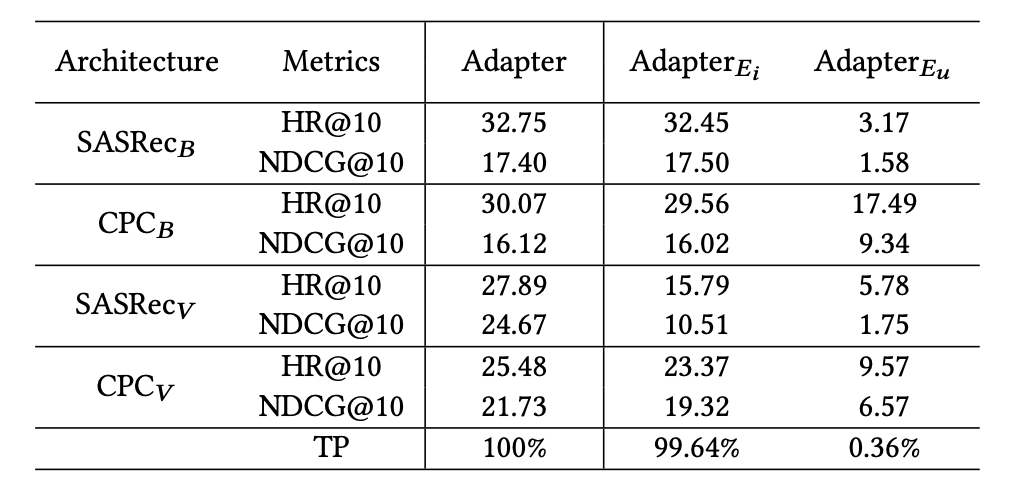
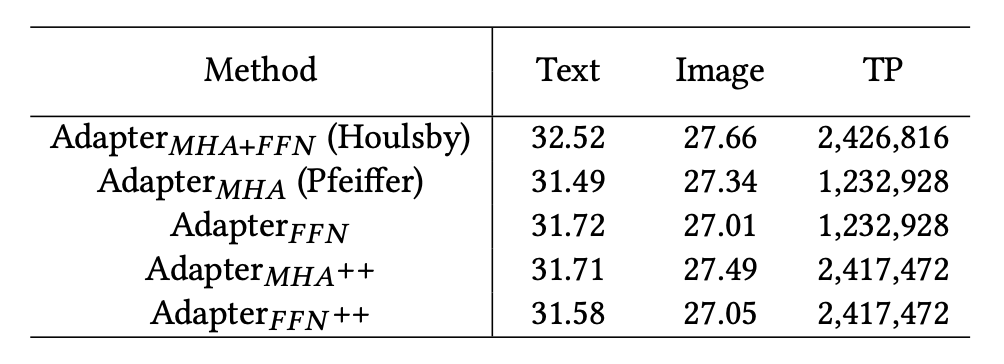
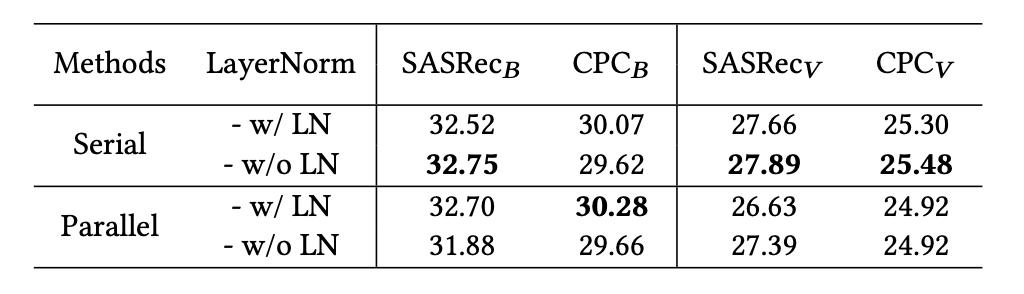
RQ3: 该文章认为,TransRec 应为用户和物品编码器放置适配器,以获得最佳效果。插入位置同样也很重要,Transformer当中的FFN (Feed-Forward Network) 和 MHA (Multi-Head Attentions) 的后面一层都需要单独的适配器模块。其次插入方式 (串行或并行) 和 LayerNorm 优化等其他因素对于推荐任务的性能上并不重要。
插入适配器的位置到物品 (Ei) 或用户编码器 (Eu) 的性能对比:
插入适配器到 MHA 和 FFN 之后的位置的性能对比:
采用序列和并行插入的性能对比:
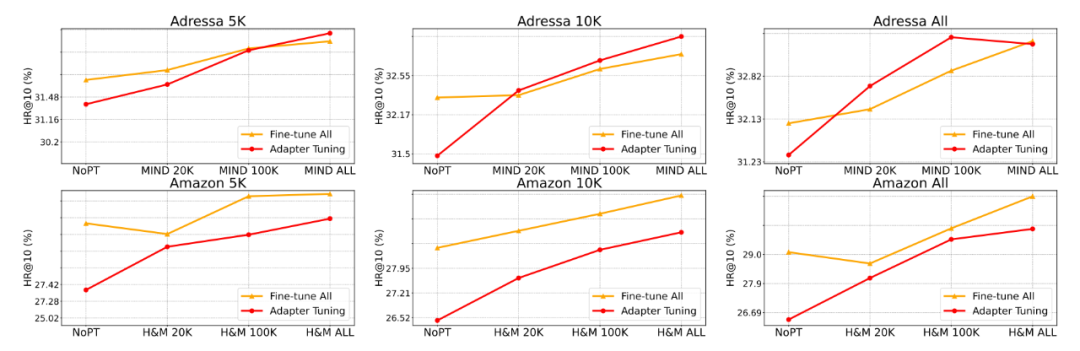
除此之外,该文章还进行了充分的数据缩放实验,发现 TransRec 的迁移学习中如果有更多预训练的源领域数据,目标域性能会有更大的提升:
总结
文章发现了两个事实:1)在文本推荐方面,与微调所有参数 (FTA) 相比,AdaT 取得了有竞争力的结果;2)在图像推荐方面,AdaT 性能良好,但略落后于 FTA。
论文对四种著名的 AdaT 方法进行了基准测试,发现经典的 Houlsby 适配器性能最佳。随后,该文章深入研究了可能影响 AdaT 在推荐任务中的结果的几个关键因素。最后,论文发现 TransRec 的 AdaT 和 FTA 符合理想的数据缩放效应——TransRec 在增大源领域数据时能提升性能。
该工作为模态推荐模型的参数高效迁移学习提供了重要指导。它对推荐系统社区的基础模型也有重要的实际意义,是实现推荐系统社区“one model for all”的目标上重要的一环。该方向未来的工作包括探究图片推荐当中如何提升 AdaT 的性能以及引入更多不同的模态等。
审核编辑:黄飞
-
让信息传递自由无限——ABB WirelessHART~(TM)升级型Hart无线适配器2010-04-24 0
-
适配器2014-05-20 0
-
怎么样才是正确的使用充电适配器2017-10-31 0
-
电源适配器如何进行盐雾测试?2021-06-26 0
-
适配器模式实现2021-09-15 0
-
透射适配器2009-12-29 584
-
网络适配器,什么是网络适配器2010-04-03 1846
-
光纤适配器是什么_光纤适配器的作用介绍2018-02-26 39440
-
分享几个电源适配器的EMI整改过程2021-05-30 962
-
设计模式-适配器模式-以电压适配器为例2021-11-07 617
-
影响天线隔离度的几个关键因素2022-08-14 1674
-
杂乱的适配器!2022-11-07 396
-
热设计软件在电源适配器设计中的应用有哪些?2023-11-23 389
-
移动电源适配器是什么 移动设备的电源适配器有何特点?2023-11-24 647
-
适配器是什么?适配器模式有几种常见的类型?2023-12-11 635
全部0条评论

快来发表一下你的评论吧 !
