

业界首款基于Arm Cortex-M85处理器的MCU
控制/MCU
描述
RA8系列是瑞萨电子推出的全新超高性能产品业界首款基于Arm Cortex-M85处理器的MCU,能够提供卓越的6.39 CoreMark/MHz,可满足工业自动化、家电、智能家居、消费电子、楼宇/家庭自动化、医疗等广泛应用的各类图形显示和语音/视觉多模态AI要求。
所有RA8系列MCU均利用Arm Cortex-M85处理器和Arm的Helium技术所带来的高性能,结合矢量/SIMD指令集扩展,能够在数字信号处理器(DSP)和机器学习(ML)的实施方面获得相比Cortex-M7内核高4倍的性能提升。

有关Arm的Helium技术介绍,我们将转载来自Arm技术专家的Helium技术讲堂系列文章,帮助您更好地理解Helium技术用于实践中。
本文转载自 Arm 社区
当人工智能 (AI) 下沉到各式各样的应用当中,作为市场上最大量的物联网设备也将被赋予智能性。Arm Helium 技术正是为基于 Arm Cortex-M 处理器的设备带来关键机器学习与数字信号处理的性能提升。
在上期 Helium 技术讲堂中,大家了解了 Helium 技术的核心“节拍式”执行。今天,我们将共同探讨一些复杂而又有趣的交错加载/存储指令。若您想要了解如何高效利用 Helium,千万别错过文末视频,通过 Arm 技术专家的实例演示,详解 Helium 如何为端点设备引入更多智能。
Arm Helium 技术诞生的由来
数独、寄存器和相信的力量
作者:Arm 架构与技术部 M 系列首席架构师兼研究员 Thomas Grocutt
DSP 处理中一个重要部分就是对不同的数据格式进行高效处理,这些数据格式通常需要转换成不同的排列方式进行计算。图像数据就是一个很好的例子,它通常以红、绿、蓝和 alpha 像素值交错流的形式被存储。但是,为了将计算矢量化,就需要将所有红色像素放在一个矢量中,绿色像素放在另一个矢量中,以此类推。在 Neon 架构中,VLD4/VST4 指令可以执行这种转换,如下图所示。
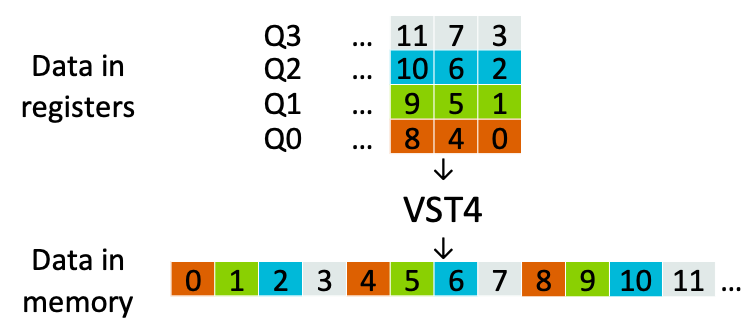
VST4 将四个 128 位寄存器交错排列,共存储 512 位数据。Neon 架构有多种交织/去交织运算,可支持不同的格式。例如,提供的 VST2 可用于交织立体声音频的左右声道。这些指令还支持从 8 到 32 位不等的元素大小。
MVE 的“节拍式”执行的主要优点之一,是它允许内存和 ALU 运算重叠,即使在单发射处理器上也是如此。如下图所示,基于此技术要实现性能的翻倍,所有指令必须执行相同的工作量。
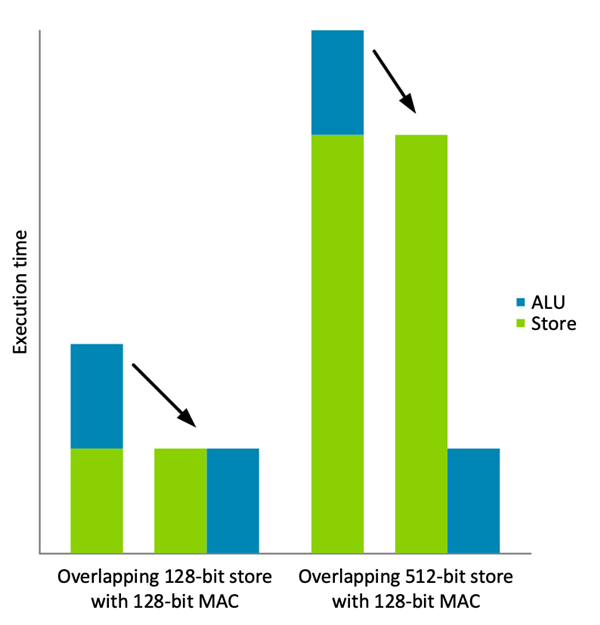
显而易见,重叠带来的性能提升会因 VST4 这样的宽存储指令而大打折扣。MVE 提供的解决方案是将存储空间分割成与 ALU 运算相平衡的块,每个块存储 128 位数据。MVE 允许由 VST40、VST41、VST42 和 VST43 这四条指令构成四路交织。但到此并未结束,仍有不少问题存在:
显而易见的拆分方法是让四条指令分别存储不同的数据流(例如 VST40 存储所有红色像素,VST41 存储绿色像素等)。对于 8 位像素数据,这意味着每条指令将存储 16 个非连续字节。这种访问模式对内存子系统来说非常复杂,会导致大量停滞。相反,指令需要生成大块连续请求。
要正确配合其他矢量指令,必须将寄存器文件端口设置为访问寄存器文件的行(即整个矢量寄存器),而不是列(即四个寄存器的第一个字节),如果要将数据交织存储到连续内存块中,则需要访问列。
为了避免我在上一篇内容中描述的时间跨越问题,我们需要将指令分成几个“节拍”,先读取寄存器的 [63:0] 位,然后在下一个周期读取 [127:64] 位。
解决方案必须同时适用于两路交织和四路交织,以及 8、16 和 32 位数据运算。
面对所有这些相互矛盾的限制,我们就像掉进了兔子洞,我不禁想起了《爱丽丝梦游仙境》中的情节:
爱丽丝:这是不可能的。
疯帽匠:只要你相信,一切皆有可能。
所以,让我们暂且放下怀疑的态度,仔细研究一下读取端口,看看会发生什么。
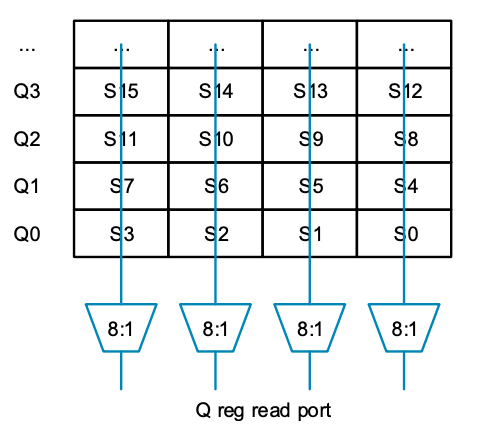
MVE 重复使用浮点寄存器文件,因此矢量寄存器(Q0 至 Q7)由每四个一组的若干组 “S” 寄存器组成。每个列多路复用器选择相同的行,然后将数据合并以访问整个 Q 寄存器(见上图)。但是,如果不能从一列中的任何寄存器中选择,而是将端口扭曲,从交替列中的寄存器中选择,如下图所示,会如何呢:
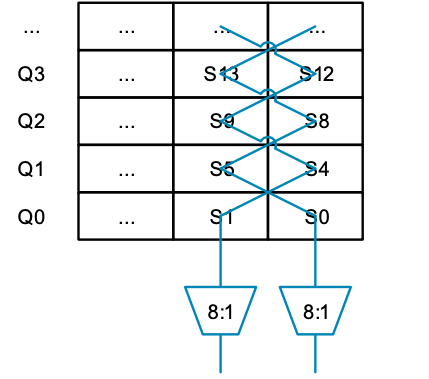
如果 8:1 多路复用器上的控制输入设置为相同值,则可读取一行数据(例如 S0 和 S1)。但是,如果使用不同的值,则可以读取一列中的一对值(如 S0 和 S4)。现在看起来似乎可行,我们能够从列和行中读取数据。如果我们把图的下面放大,并将寄存器编号替换为它们所连接的多路复用器的编号,就会得到下图结果:
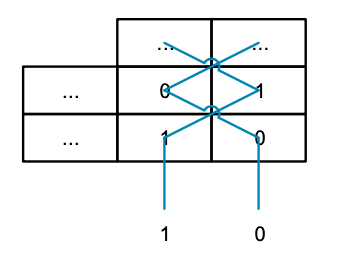
这类似于一道简单的数独谜题,在重复矩阵的每一行和每一列中,每个数字只会出现一次,只不过这个矩阵是 2 x 2 的,而不是平常的 9 x 9。由于只能从一列中读取两个值,并且只能处理 32 位值(多路复用器的宽度),因此这种模式只能提供两路交织的解决方案。由于我们需要一种可处理所有交错模式和数据宽度组合的模式,因此可想象将所有组合垂直堆叠起来,得到一个多分辨率的三维数独谜题。解决一层谜题轻而易举,但解决整个三维谜题的过程一定令人叹为观止。此外,我们还需要考虑上文提到的其他限制因素,如连续内存访问,以及在不同周期内拆分对寄存器上下 64 位的访问。
经过一番思索,我意识到可以将问题一分为二:一是确定一种可在单个统一的问题空间中表示全部约束的方法,二是解决这些约束的单调任务。由于该模式类似于一个非常复杂的数独问题,而许多数独程序都是基于 SAT 解算器的,因此我产生了使用 SAT 解算器来完成单调约束求解任务的想法。经过努力,我想出了一种能表示所有约束的方法,一番调试后,第一个可行的解决方案诞生了。虽然它不完善,而且会导致多路复用器的控制逻辑难以实施,但至少胜利在望了。由于不想对解决方案进行手动清理,我们添加了一些额外的约束条件,引入了一些对称性,并产出了最终的解决方案,它竟然是一对双嵌套四重螺旋结构:
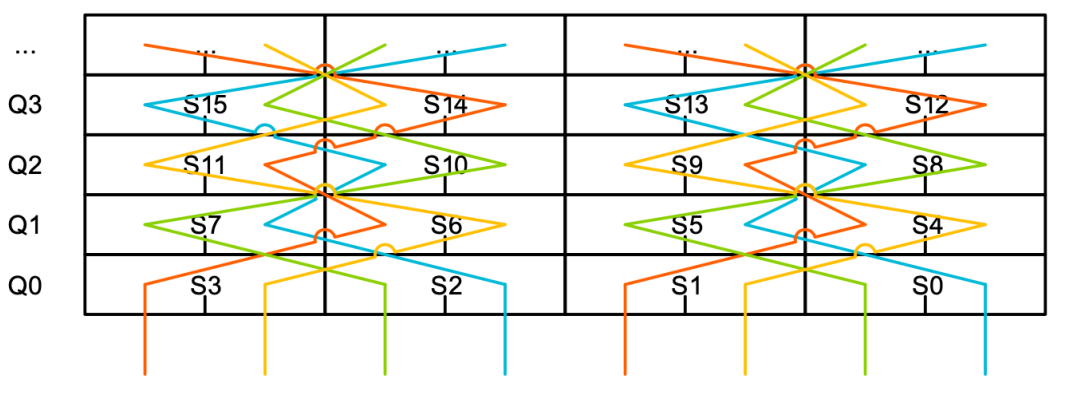
为了让大家看到嵌套的螺旋线,我在下图中标注了单个多路复用器的路径。如图所示,路径每行交替通过 32 位 “S” 寄存器(如左图所示),每两行交换通过 “S” 寄存器上下两半 16 位区域(如右图所示)。
直觉告诉我,这种扭曲的方法对于三路交织来说是行不通的,经证实我是对的,SAT 解算器正式证明无解。
这种扭曲方法意味着可以同时访问寄存器文件行和列中的数据。但问题在于,读取端口返回的字节可能顺序有误,而顺序取决于访问的寄存器。要纠正此情况,就需要使用一个交叉多路复用器,将一切交换回正确的位置。由于如 VREV 等其他指令和复数原生操作指令会用到交叉多路复用器,所以我们正好能免费使用它。这正印证了那句话:“如果你必须使用一个硬件,请物尽其用。”
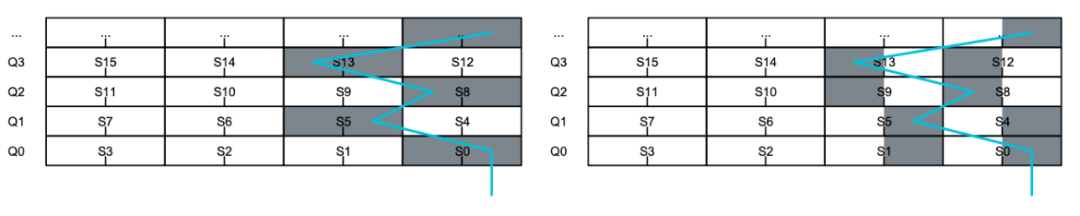
下图显示了由读取端口扭曲模式衍生出的一些指令访问模式。第一种情况 (VST2n.S32) 显示从矢量寄存器 Q0 和 Q1 读取 32 位 (S32),并将其两路交织(如左右音频通道)。图中颜色代表两条指令分别读取的寄存器部分(即 VST20 读取橙色部分),元素中的文字表示内存中存储的字节偏移。

可以发现,上述 S8 和 S16 模式都将相同的数据放在寄存器的相同颜色区域内;唯一不同的是每节中字节的排列方式。这意味着,只需在交叉多路复用器中使用不同的配置,16 位模式也能支持 8 位。这些模式也适用于加载指令所使用的写入端口。除了可以建立寄存器文件端口外,这些模式还意味着内存访问始终是一对 64 位的连续块,这样可以提高内存访问的效率。另外,这些数据块地址的第 [3] 位总是不同的,因此可以在拥有两组交织 64 位内存的系统上并行发送。
研究团队从这些指令中积累了两条重要的经验。首先,要想在 gate 数量和效率方面取得突破式进展,就必须在设计架构的同时对微架构的细节同步思考设计。其次,要保持信念,相信一切皆有可能。
审核编辑:黄飞
-
Cortex-M3处理器是什么2021-07-16 0
-
Cortex™-M3处理器2021-08-11 0
-
Arm Cortex-M处理器—Cortex-M85介绍2022-07-15 0
-
ARM Cortex-M85处理器技术参考手册2023-08-09 0
-
ARM Cortex-M85处理器软件优化指南2023-08-10 0
-
Arm Cortex®-M33处理器技术参考手册2023-08-17 0
-
Arm Cortex-R82处理器技术参考手册2023-08-17 0
-
ARM Cortex-M85处理器设备通用用户指南2023-08-18 0
-
Arm Cortex-M55处理器数据集2023-08-25 0
-
Arm Cortex-M7处理器产品介绍2023-08-25 0
-
Arm Cortex-M23处理器产品介绍2023-08-25 0
-
ARM Cortex-M33处理器数据表2023-08-28 0
-
瑞萨推出业界首款基于Arm Cortex-M85处理器的MCU2023-11-07 474
-
业界首款基于Arm Cortex-M85的超高性能MCU2023-11-10 266
-
瑞萨电子发布业界首款基于Cortex-M85处理器的全新超高性能MCU2024-02-26 252
全部0条评论

快来发表一下你的评论吧 !
