

基于FPGA的WALLACE TREE乘法器设计
FPGA/ASIC技术
描述
本文着重介绍了一种基于WALLACETREE优化算法的改进型乘法器架构。根据FPGA内部标准独特slice单元,有必要对WALLACE TREE部分单元加以研究优化,从而让在FPGA的乘法器设计中的关键路径时延得以减小,整体时钟性能得以提高。也能够使FPGA的面积资源合理优化,提高器件的整体资源利用率。
1 WALLACE TREE结构
WALLACE TREE是对部分积规约,减小乘法器关键路径时延的一种算法。传统WALLACE TREE结构的CSA(Carry Save Adder)阵列乘法器如图1所示,其中“·”代表生成的多个部分乘积项,相应电路中用逻辑与门来实现。求和阵列将前面生成的多个部分积通过3:2 CSA压缩器,将其压缩成2个部分积,最后通过末级进位相加得到所需的最终乘积结果。图中矩形框所示为3:2 CSA压缩器,其电路逻辑等效于一个全加器结构。通过运算可知N个部分积,要经类似的log(2N/3)级3:2压缩,就可得到2个部分积。
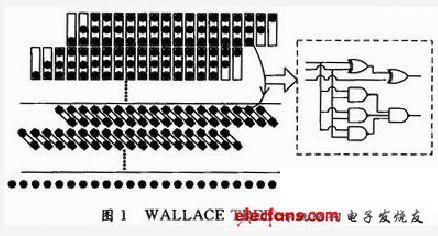
2 压缩器的优化
由于FPGA内部的结构是固定的,没有以上WALLACE TREE所需要的CSA标准全加器结构。因此,在传统的FPGA电路综合实现时,该CSA全加
器被综合在FPGA内部查找表(LUT)和进位链中,占用了整个slice单元的资源。由于经典WALLACETREE结构不具有良好的对称性且需要权重对齐等因素,势必要增大FPGA电路的复杂度,增加大量的FPGA内部布局和布线资源,在FPGA中不规则的布局布线结构,也增大了关键路径的时延。
为在FPGA中较好地实现WALLACE TREE结构,结合FPGA中最小标准单元的结构silce,对CSA全加器单元结构加以改进。如图2所示,可将WALLACE TREE相邻的平级3:2 CSA压缩器合并成一个6:4压缩器。该压缩器只需使用1个FPGA的silce资源,就能实现其数字逻辑。下面以3×3乘法器为例,进行WALLACE TREE压缩器的推导和优化。如图2的第一个部分积,部分积低位空白应补0,高位空白位用该部分积的最高位补齐。
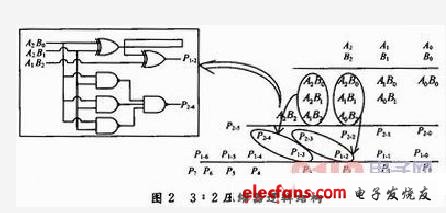
下面对2个3:2 CSA压缩器合并成一个6:4压缩器单元运算逻辑做理论推导,其中:

合并这两项3:2压缩为6:4压缩时,A1B2和P23属同级进位,在计算过程中可将这两项的位置互换,因此上式可推导演化成:

3 改进CSA的FPGA实现
Xilinx提供了一项强大的用户界面软件工具FPGA Editer,可以通过手动编辑和修改FPGA最基本的标准单元slice结构,使其符合所需要的逻辑。图3左边是一个WALLACE TREE 6:4压缩的整体结构,右边是实现架构中一个6:4压缩的FPGA内部标准单元slice。slice电路中虚线是器件原有的预布线,实线是根据实际电路逻辑手动编辑后slice内部电路布线。根据上一面的推导式(5)~(8),slice内部的2个查找表(LUT)单元被配置成2输入异或门单元。为了使整体WALLACE TREE布线齐整,还将式(7)直通逻辑实现也在该级slice压缩器中完成,其中输入电平A1B2经过2个MUX和一个配置为1的常有效LATCH输出到
,形成一个直通电路。
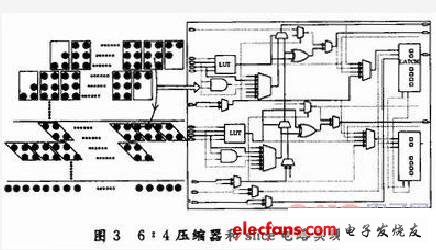
从图3可以看出,WALLACE TREE的6:4压缩器单元只用一个slice就可以实现。而几乎所有Xilinx的FPGA器件内部slice结构都类似,因此该6:4压缩器在基本的FPGA器件中都可以通过此手动编辑方法实现,形成一个可供顶层WALLACETREE逻辑调用的硬宏模块。
4 乘法器的FPGA实现和仿真
在顶层乘法器WALLACE TREE逻辑架构设计中,可以通过描述语言模块例化来调用前面手动实现的6:4压缩器,可将slice压缩模块看成一个FPGA中固有的IP硬宏模块,调用方法与使用FPGA器件内部的其他IP没有区别。在FPGA Editer中对各个模块相互位置按树的层次和数字逻辑顺序进行约束排列,形成一个约束文件。这样FPGA芯片面积资源不仅得到充分的利用,在时序方面也会减小关键路径的时延,提高时钟频率。
该乘法器的末级加法器要把WALLACE TREE得到的最后2个部分积快速的相加得到最终结果。末级加法器的实现方法有CPA(Carry Propaga tion Adder),该加法器的利用超前进位,可以使进位链这个关键路径的时序在逻辑上层次减小。但该加法器在FPGA综合实现后形成复杂结构,带来的是利用了很大的布局面积和布线资源。FPGA内部结构中以其特有纵向结构的超级进位链,可将进位的器件延时和布线延时优化。可以利用该进位链,合理进行布局约束优化,使进位链路径时序减小。实践表明,在16×16的加法器中,该进位链的时延只有6 ns左右,大大减小了整个乘法器关键路径延时。在图4中列出了本设计的FPGA布局布线布局布线后仿真结果。该结果在XILINX-Virtex5-VC5VSX35T器件中运行,通过ModelSim仿真输出采集。multin_a和multin_b分别是16位乘数,acc_out是相乘后输出的32位结果,rst_n是复位清0信号。整个设计的硬件描述语言采用Verelog语言,其中例化了预先用FPGA Editer工具设计好的6:4硬宏压缩模块。

图5给出了WALLACE TREE乘法器设计的XILLNX-Virtex5-VC5VSX35T器件实际运行性能参数。该结果是FPGA器件以系统时钟为120 MHz运行时,通过XILLNX公司ISE套装软件ChipScope采集获取的数据。图中,unt1和unt2采用FPGA内部一个测试计数器输出的16位无符号乘数,将其输入WALLACE TREE乘法器运算后,得到一组32位乘积结果。该实测结果表明,该结构的乘法器能工作正常工作在120 MHz系统时钟的条件下,其实现电路关键路径的延时小于8.33ns。

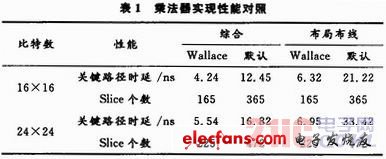
表1分别列出了16×16,24×24位乘法器在FPGA中用工具默认方法和本文方法生成的资源和时序对照图。可以看出,本文的结构更合理,资源和速度都得到了一定程度的优化。
5 结语
本文根据FPGA内部标准单元结构,提出了一种改进的WALLACE TREE 6:4压缩器的新型逻辑结构,并用Xilinx提供的工具套件FPGA Edi-ter实现了该压缩器单元。结合乘法器在FPGA中的仿真表明,该结构的乘法器在提高系统的时钟频率和节省布局布线方面都有很大的优势。
-
求fpga乘法器,要求快的2012-08-16 0
-
怎么设计基于FPGA的WALLACETREE乘法器?2019-09-03 0
-
求一种改进的Wallace树型乘法器的设计2021-04-14 0
-
怎么实现32位浮点阵列乘法器的设计?2021-05-08 0
-
基于跳跃式Wallace树的低功耗32位乘法器2009-04-17 594
-
基于FPGA 的单精度浮点数乘法器设计2010-09-29 619
-
乘法器的基本概念2010-05-18 13458
-
1/4平方乘法器2010-05-18 1811
-
N象限变跨导乘法器2010-05-18 1571
-
变跨导乘法器2010-05-18 1110
-
基于IP核的乘法器设计2011-05-20 835
-
华清远见FPGA代码-FPGA片上硬件乘法器的使用2016-10-27 539
-
乘法器2016-12-01 1089
-
采用CSA与4-2压缩器改进Wallace树型乘法器的设计2019-05-15 15074
-
使用verilogHDL实现乘法器2018-12-19 10511
全部0条评论

快来发表一下你的评论吧 !
