

语音识别的技术历程及工作原理
描述
语音识别技术,也被称为自动语音识别(Automatic Speech Recognition,ASR),是以语音为研究对象,通过语音信号处理和模式识别让机器理解人类语言,并将其转换为计算机可输入的数字信号的一门技术。
语音识别的技术历程
现代语音识别可以追溯到1952年,Davis等人研制了世界上第一个能识别10个英文数字发音的实验系统,从此正式开启了语音识别的进程。语音识别发展到今天已经有70多年,但从技术方向上可以大体分为三个阶段。
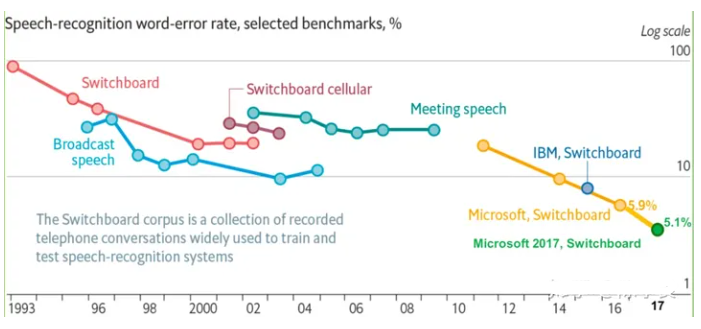
下图是从1993年到2017年在Switchboard上语音识别率的进展情况,从图中也可以看出1993年到2009年,语音识别一直处于GMM-HMM时代,语音识别率提升缓慢,尤其是2000年到2009年语音识别率基本处于停滞状态。2009年随着深度学习技术,特别是DNN的兴起,语音识别框架变为DNN-HMM,语音识别进入了DNN时代,语音识别精准率得到了显著提升。
2015年以后,由于“端到端”技术兴起,语音识别进入了百花齐放时代,语音界都在训练更深、更复杂的网络,同时利用端到端技术进一步大幅提升了语音识别的性能,直到2017年微软在Swichboard上达到词错误率5.1%,从而让语音识别的准确性首次超越了人类,当然这是在一定限定条件下的实验结果,还不具有普遍代表性。
语音识别原理
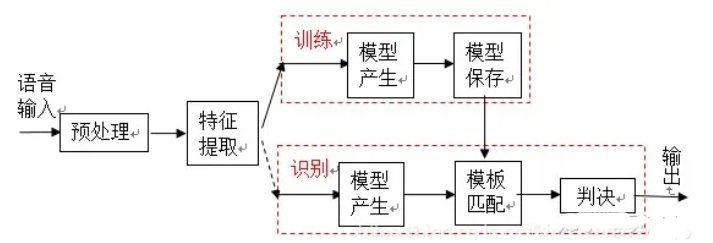
语音识别的本质是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。目前,模式匹配原理已经被应用于大多数语音识别系统中。如图1是基于模式匹配原理的语音识别系统框图。
一般的模式识别包括预处理,特征提取,模式匹配等基本模块。如图所示首先对输入语音进行预处理,其中预处理包括分帧,加窗,预加重等。其次是特征提取,因此选择合适的特征参数尤为重要。
常用的特征参数包括:基音周期,共振峰,短时平均能量或幅度,线性预测系数(LPC),感知加权预测系数(PLP),短时平均过零率,线性预测倒谱系数(LPCC),自相关函数,梅尔倒谱系数(MFCC),小波变换系数,经验模态分解系数(EMD),伽马通滤波器系数(GFCC)等。
在进行实际识别时,要对测试语音按训练过程产生模板,最后根据失真判决准则进行识别。常用的失真判决准则有欧式距离,协方差矩阵与贝叶斯距离等。
语音识别技术涉及的领域有哪些
它涉及的领域相当广泛,包括但不限于以下几个方面:
智能语音助手:智能语音技术为我们带来了智能助理,如Siri、小爱同学等。用户可以通过语音与智能助理进行交流,询问天气、定闹钟、发送消息等,实现更加直观、便捷的操作。
智能家居:借助智能语音技术,用户可以通过简单的口头指令控制家居设备,例如开关灯、调整温度、播放音乐等,实现智能家居的全方位控制和管理。
医疗领域:语音识别技术可以辅助医生对病人进行诊断,对病人的病情和治疗方案进行记录等。此外,它还可以应用于医疗设备的操作中,使得医疗设备更加智能化和便利化。
教育领域:语音识别技术可以辅助学生进行口语练习,提高学生的英语口语水平等。另外,它还可以应用于教育评测中,通过语音识别来评估学生的语音表达能力、语感等。
金融领域:语音识别技术可以用于身份验证、语音指令操作等。此外,它还可以应用于金融客户服务中,使得客户可以通过语音来查询账户信息、进行转账等操作,更加便捷快速。
游戏领域:语音识别技术可以应用于游戏领域,如通过语音识别来与游戏角色进行交互,使得游戏更加真实、有趣。
智能客服:语音识别技术可以帮助用户通过语音指令获取客服服务,解决客服等待时间长的问题。
语音翻译:在全球化的今天,语音识别技术可以帮助人们实现不同语言之间的翻译。
随着技术的不断发展和完善,语音识别技术将在更多领域得到应用,并为人们的生活带来更多便利。
审核编辑:黄飞
-
语音编码识别的请进2012-07-11 0
-
请问电销机器人智能语音识别的原理是什么?2018-06-12 0
-
模式识别的关键技术2020-12-11 0
-
特定人语音识别的方法有哪些?2021-05-14 0
-
自动语音识别的原理是什么?2021-06-15 0
-
离线语音识别和控制的工作原理及应用2023-11-07 0
-
离线语音识别及控制是怎样的技术?2023-11-24 0
-
语音识别技术的发展历程,语音识别是如何工作的?语音识别资料概述2018-09-01 9947
-
语音识别的技术历程2019-08-22 4185
-
简析语音识别技术的工作原理2019-12-23 11239
-
语音识别的两个方法_语音识别的应用有哪些2020-04-01 5668
-
虹膜识别技术的过程_虹膜识别的发展历程2020-04-02 5398
-
情感语音识别的前世今生2023-11-12 340
-
情感语音识别的应用与挑战2023-11-30 285
全部0条评论

快来发表一下你的评论吧 !
