

LLM推理任务中GPU的选择策略
描述
去年十月,美商务部禁令的出现,使中国客户无法使用NVIDIA H100/H200旗舰芯片。一时间,各种NV存货、中国限定卡型、其他厂商NPU纷至沓来。在大模型推理场景中,如何客观比较不同硬件的能力,成为一大难题,比如:
Q1:输入输出都很长,应该选H20还是A800?
Q2:高并发情况下,用L20还是RTX 4090?
最直接的解决方法是,使用SOTA推理服务框架,对不同硬件X不同负载做全面的评估。但是,大模型任务推理的负载变化范围很大,导致全面评估耗时耗力。主要来源以下几个方面:
输入参数batch size、input sequence length、output sequence length变化多样。
大模型种类很多,从7B到170B,不同尺寸模型都有。
硬件种类很多。参考许欣然的文章,备选的NVIDIA GPU就有15种,而且还有其他厂商的硬件。
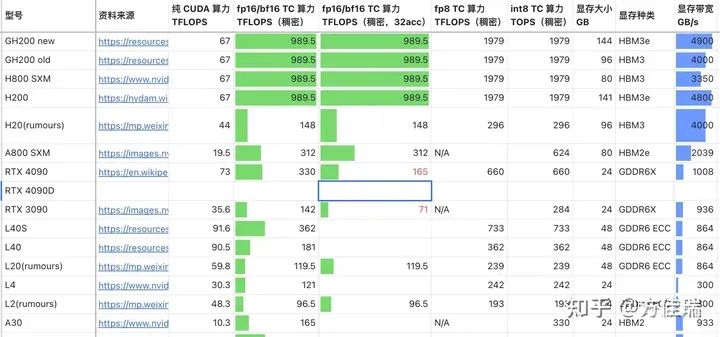
如何在繁重的benchmark任务前,对不同硬件在不同推理任务上的表现有一个直观的认识?为此,我做了一个简单的性能评估工具LLMRoofline,它使用Roofline模型,不需要运行程序,来简单比较不同硬件。
Roofline模型
Roofline模型是一种非常简化的性能模型,但可以清晰地展示出应用程序的硬件性能极限。
在Roofline模型可以直观展示一张曲线图,其中x轴表示AI(Arithmetic Intensity),即每个内存操作对应的浮点运算次数;y轴表示性能,通常以每秒浮点运算次数(Tflops)表示。图中的“屋顶”(Roofline)由两部分组成:一部分是峰值内存带宽(Memory Bandwidth)限制的斜线,另一部分是峰值计算性能(Peak Performance)限制的水平线。这两部分相交的点是应用程序从内存带宽受限转变为计算性能受限的转折点。
下图绘制了多个不同GPU(包括NVIDIA的A100、H20、A800、L40S、L20和4090)的Roofline模型。如果一个硬件的屋顶Roof越高,那么它在处理计算密集型任务时的性能更好;如果屋顶的Line斜率越高,表示它的HBM带宽越高,处理访存密集型任务时,性能越好。
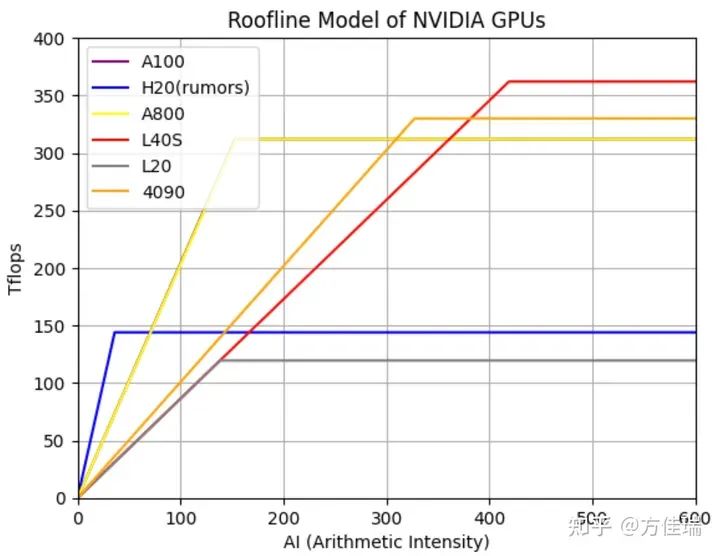
图1,不同GPU的Roofline模型
LLM推理性能模型
方法一:全局Roofline模型
基于Roofline模型,可以计算出不同LLM模型推理任务的AI。我们用Decode阶段的AI来代表整体推理阶段的AI,因为Prefill阶段,是计算密集的,且在一次推理任务中只算一次,时间占比很小。因为LLM的Transformers layer数比较大,所以只考虑Transformers的计算和访存,忽略包括Embedding在内的前后处理开销。
AI = 总计算量FLOPS/(总参数大小+总KVCache大小)
为了简化,没考虑中间activation的内存读取,因为它的占比通常很小,而且可以被FlashAttention之类的Kernel Fusion方法优化掉。
总计算量和参数量可以参考如下文章,文章中的数据还是针对GPT2的,这里在LLAMA2模型下进行一些修改,主要包括取消intermediate_size=4*hidden_size限制,并考虑GQA和MoE等模型结构的优化。
这里约定,bs(batch size),in_len(输入序列长度,Decoder阶段一直是1),kv_len(KVCache长度),h(hidden_size),i(intermediate_size)。
总计算量
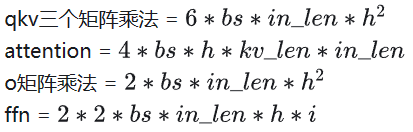
总参数量
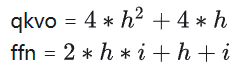
KVCache参数量
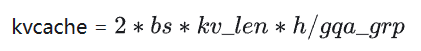
如果使用MoE结构,我们计算参数时对ffn 乘以 #Expert,计算量对ffn乘以topk。
有了任务的AI,可以在图1中,min(peak_flops, ai * bandwidth)查找对应位置的Tflops性能,从而比较两个硬件上该任务的性能优劣。
使用多卡Tensor Parallel并行,分子分母都近似除以GPU数目,因此AI几乎不变。使用FP8会增加Roof高度,但是Line的斜率不变。
方法二:算子Roofline模型
上述方法还是将整个Transformers看成整体算出AI,还可以对Decoder中每一个算子算出它的AI,然后使用Roofline模型计算该算子的延迟。计算算子的AI可以考虑Activation的读写开销,相比方法一访存计算会更加精确。
我找到了一个现成的项目LLM-Viewer做了上述计算,该项目也是刚发布不久。
https://github.com/hahnyuan/LLM-Viewergithub.com/hahnyuan/LLM-Viewer
值得注意的是,目前无论方法一还是方法二都无法精确估计运行的延迟。比如,我们用LLM-Viewer估计A100的延迟,并和TensorRT-LLM的数据对比,可见最后两列差距还是比较大的。因为Roofline模型只能估计性能上限,并不是实际的性能。
| Model | Batch Size | Input Length | Output Length |
TRT-LLM Throughput (token/sec) |
LLM-Viewer Throughput (token/sec) |
| LLaMA 7B | 256 | 128 | 128 | 5,353 | 8,934 |
| LLaMA 7B | 32 | 128 | 2048 | 1,518 | 2,796 |
| LLaMA 7B | 32 | 2048 | 128 | 547 | 788 |
| LLaMA 7B | 16 | 2048 | 2048 | 613 | 1,169 |
但是,应该可以基于LLM-Viewer的数据进行一些拟合来精确估计不同GPU的性能,不过据我了解还没有对LLM做精确Performance Model的工作。
效果
LLMRoofline可以使用上述两种方式比较不同硬件的性能。它会画出一个Mesh,横轴时序列长度(可以看成生成任务的平均KVCache length),纵轴时Batch Size。
比如,我们比较NVIDIA H20 rumors和A100在推理任务上的差异。这两款芯片一个带宽很高4TBps vs 2 TBps,一个峰值性能高 312 Tflops vs 148 Flops。
使用LLAMA2 13B时,左图是方法二、右图是方法一的A100/H20的比较结果,大于1表示有优势。两张图有差异,但是分布近似。A100比H20的优势区域在网格的左上角。当序列长度越短、Batch Size越大,A100相比H20越有优势。这是因为,此时任务更偏计算密集型的,A100的峰值性能相比H20更具优势。
借助性能模型,我们可以澄清一些误解。例如,有人可能会认为在H20上增大Batch Size会使任务变得更加计算密集,且由于H20的计算能力非常低,因此增大Batch Size是无效的。这里忽略了序列长度对AI的影响,对于处理长序列的任务来说,任务一直是访存密集的,增大Batch Size仍然是一种有效的优化策略。
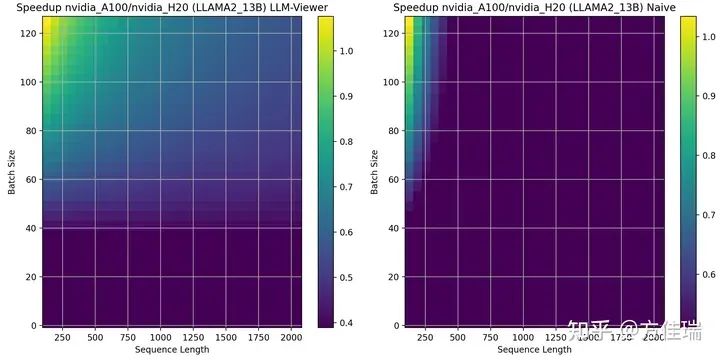
当使用LLAMA2 70B时,A100相比H20优势区域扩大。这是因为LLAMA2 13B没有用GQA,但LLAMA2 70B用了GQA,这让推理任务更偏计算密集,对A100更有利。
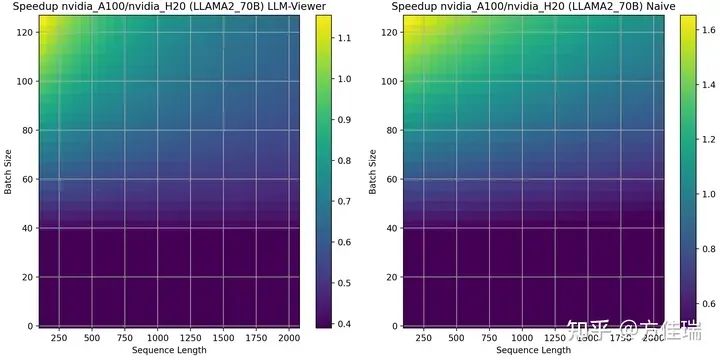
当使用Mistral 7B时,LLM-Viewer目前还没有登记模型信息,我们只有方法一的结果,A100相比H20的优势区域相比13B缩小。这说明hidden size越大,越偏计算密集。
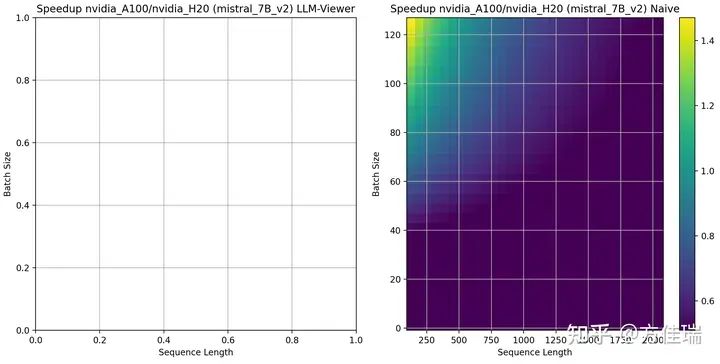
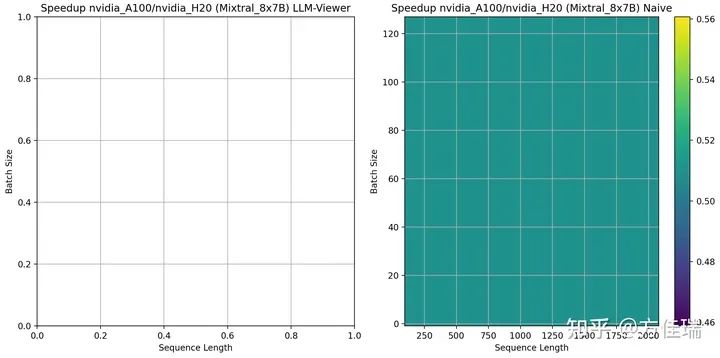
Mixtral 8X7B时,可见A100相比H20一致保持劣势,说明MoE把推理任务推向访存密集的深渊,H20的带宽优势发挥明显作用。
通过使用 LLMRoofline,我们能够制作出许多两个硬件比较的 Mesh,从而清晰地观察到一些类似上述的简单结论。
总结
大模型推理任务的复杂性和多变性使得对不同型号GPU的适用范围的理解变得尤为重要。为了帮助大家直观地感知这些差异,本文介绍了一款名为LLMRoofline的性能分析工具。该工具采用Roofline模型,能够直观地对比不同硬件的性能和适用范围。具体而言,影响硬件选择的因素包括任务的序列长度、批处理大小(Batch Size),以及是否使用了MoE/GQA等优化技巧,它们相互作用可以在LLMRoofline中得到体现。
审核编辑:黄飞
-
充分利用Arm NN进行GPU推理2022-04-11 0
-
如何判断推理何时由GPU或NPU在iMX8MPlus上运行?2023-03-20 0
-
如何利用LLM做多模态任务?2023-05-11 702
-
如何利用LLM做一些多模态任务2023-05-17 628
-
LLM在各种情感分析任务中的表现如何2023-05-29 1616
-
基准数据集(CORR2CAUSE)如何测试大语言模型(LLM)的纯因果推理能力2023-06-20 1386
-
适用于各种NLP任务的开源LLM的finetune教程~2023-07-24 1450
-
人工智能中的处理器如何选择2023-09-05 758
-
对比解码在LLM上的应用2023-09-21 406
-
mlc-llm对大模型推理的流程及优化方案2023-09-26 498
-
Hugging Face LLM部署大语言模型到亚马逊云科技Amazon SageMaker推理示例2023-11-01 504
-
怎样使用Accelerate库在多GPU上进行LLM推理呢?2023-12-01 746
-
LLM推理加速新范式!推测解码(Speculative Decoding)最新综述2024-01-29 618
-
自然语言处理应用LLM推理优化综述2024-04-10 163
全部0条评论

快来发表一下你的评论吧 !
