

数据中心网络组网设计及发展趋势
通信网络
描述
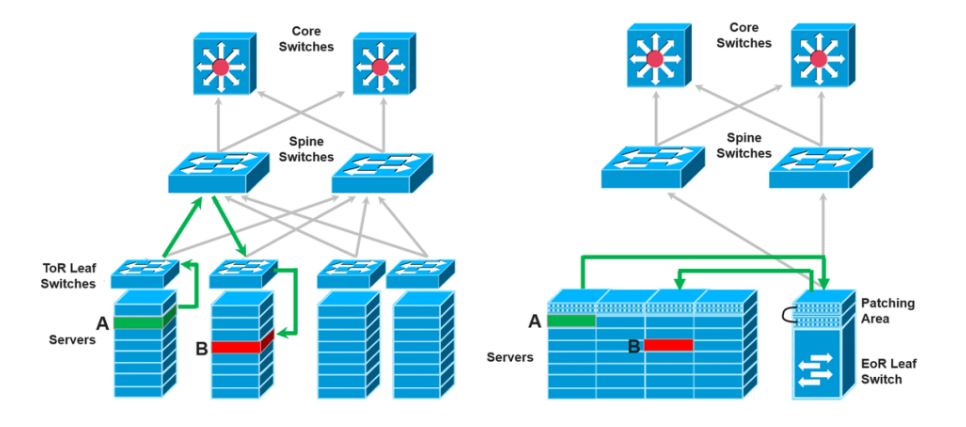

 (1)可扩展性 为适应业务的发展、需求的变化、先进技术的应用,数据中心网络必须具备足够的可扩展来满足发展的需要。如采用合理的模块化设计,尽量采用端口密度高的网络设备、尽量在网络各层上具备三层路由功能,使得整个数据中心网络具有极强的路由扩展能力。功能的可扩展性是数据中心网络随着发展提供增值业务的基础。(2)可用性 包括网络设备和网络本身的冗余。关键设备均采用电信级全冗余设计,采用冗余网络设计,每个层次均采用双机方式,层次与层次之间采用全冗余连接。提供多种冗余技术,在不同层次可提供增值冗余设计。(3)灵活性 灵活的目的是实现可根据数据中心不同用户的需求进行定制,网络/设备能够灵活提供各种常用网络接口、能够根据不同需求对网络模块进行合理搭配。(4)安全性 安全性是数据中心的用户最为关注的问题,也是数据中心建设的关键,它包括物理空间的安全控制及网络的安全控制。二、数据中心网络组网设计(1)Fabric网络
(1)可扩展性 为适应业务的发展、需求的变化、先进技术的应用,数据中心网络必须具备足够的可扩展来满足发展的需要。如采用合理的模块化设计,尽量采用端口密度高的网络设备、尽量在网络各层上具备三层路由功能,使得整个数据中心网络具有极强的路由扩展能力。功能的可扩展性是数据中心网络随着发展提供增值业务的基础。(2)可用性 包括网络设备和网络本身的冗余。关键设备均采用电信级全冗余设计,采用冗余网络设计,每个层次均采用双机方式,层次与层次之间采用全冗余连接。提供多种冗余技术,在不同层次可提供增值冗余设计。(3)灵活性 灵活的目的是实现可根据数据中心不同用户的需求进行定制,网络/设备能够灵活提供各种常用网络接口、能够根据不同需求对网络模块进行合理搭配。(4)安全性 安全性是数据中心的用户最为关注的问题,也是数据中心建设的关键,它包括物理空间的安全控制及网络的安全控制。二、数据中心网络组网设计(1)Fabric网络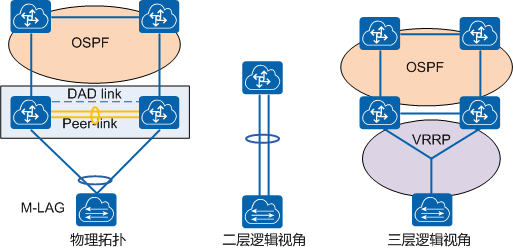 随着云计算的发展,在数据中心网络中服务器虚拟化技术得到广泛应用,但服务器在迁移时,为了保证迁移时业务不中断,就要求不仅虚拟机的IP地址不变,而且虚拟机的运行状态也必须保持原状(例如TCP会话状态),所以虚拟机的动态迁移只能在同一个二层域中进行,而不能跨二层域迁移,这就要我的二层网络足够大。而传统的二层技术,不论是通过缩小二层域的范围和规模来控制广播风暴的影响范围或是阻塞掉冗余设备和链路来破环,网络中能够容纳的主机数量、收敛性能以及网络资源的带宽利用率对于数据中心网络而言是远远不够的。 M-LAG(Multichassis Link Aggregation Group)即跨设备链路聚合组,是一种实现跨设备链路聚合的机制,将一台设备与另外两台设备进行跨设备链路聚合,从而把链路可靠性从单板级提高到了设备级。对二层来讲,可将M-LAG理解为一种横向虚拟化技术,将M-LAG的两台设备在逻辑上虚拟成一台设备,形成一个统一的二层逻辑节点。M-LAG提供了一个没有环路的二层拓扑同时实现冗余备份,不再需要繁琐的生成树协议配置,极大的简化了组网及配置。这种设计相对传统的xSTP破环保护,逻辑拓扑更加清晰、链路利用更加高效。
随着云计算的发展,在数据中心网络中服务器虚拟化技术得到广泛应用,但服务器在迁移时,为了保证迁移时业务不中断,就要求不仅虚拟机的IP地址不变,而且虚拟机的运行状态也必须保持原状(例如TCP会话状态),所以虚拟机的动态迁移只能在同一个二层域中进行,而不能跨二层域迁移,这就要我的二层网络足够大。而传统的二层技术,不论是通过缩小二层域的范围和规模来控制广播风暴的影响范围或是阻塞掉冗余设备和链路来破环,网络中能够容纳的主机数量、收敛性能以及网络资源的带宽利用率对于数据中心网络而言是远远不够的。 M-LAG(Multichassis Link Aggregation Group)即跨设备链路聚合组,是一种实现跨设备链路聚合的机制,将一台设备与另外两台设备进行跨设备链路聚合,从而把链路可靠性从单板级提高到了设备级。对二层来讲,可将M-LAG理解为一种横向虚拟化技术,将M-LAG的两台设备在逻辑上虚拟成一台设备,形成一个统一的二层逻辑节点。M-LAG提供了一个没有环路的二层拓扑同时实现冗余备份,不再需要繁琐的生成树协议配置,极大的简化了组网及配置。这种设计相对传统的xSTP破环保护,逻辑拓扑更加清晰、链路利用更加高效。(2)Overlay网络
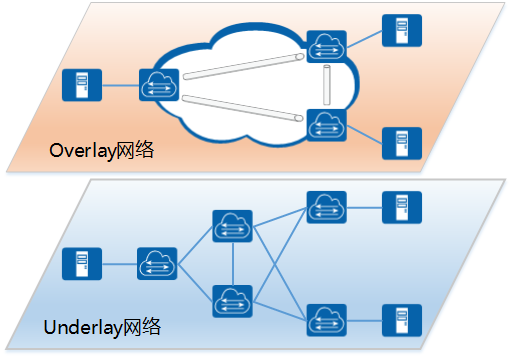
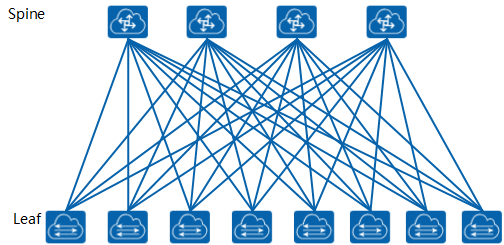 Spine+Leaf两层设备的扁平化网络架构来源于CLOS网络,CLOS网络以贝尔实验室的研究人员Charles Clos命名,他在1952年提出了这个模型,作为克服电话网络中使用的机电开关的性能和成本相关挑战的一种方法。Clos用数学理论来证明,如果交换机按层次结构组织,在交换阵列(现在称为结构)中实现非阻塞性能是可行的,主要是通过组网来形成非常大规模的网络结构,本质是希望无阻塞。在此之前,要实现“无阻塞的架构”,只能采用NxN的Cross-bar方式。接入连接的数量仍然等于折叠后的三层CLOS网络架构的Spine与Leaf之间的连接数,流量可以分布在所有可用的链接上,不用担心过载问题。随着更多的连接被接入到Leaf交换设备,我们的链路带宽收敛比将增加,可以通过增加Spine和Leaf设备间的链路带宽降低链路收敛比。Spine+Leaf网络架构的另一个好处就是,它提供了更为可靠的组网连接,因为Spine层面与Leaf层面是全交叉连接,任一层中的单交换机故障都不会影响整个网络结构。因此,任一层中的一个交换机的故障都不会使整个结构失效。(4)BGP EVPN
Spine+Leaf两层设备的扁平化网络架构来源于CLOS网络,CLOS网络以贝尔实验室的研究人员Charles Clos命名,他在1952年提出了这个模型,作为克服电话网络中使用的机电开关的性能和成本相关挑战的一种方法。Clos用数学理论来证明,如果交换机按层次结构组织,在交换阵列(现在称为结构)中实现非阻塞性能是可行的,主要是通过组网来形成非常大规模的网络结构,本质是希望无阻塞。在此之前,要实现“无阻塞的架构”,只能采用NxN的Cross-bar方式。接入连接的数量仍然等于折叠后的三层CLOS网络架构的Spine与Leaf之间的连接数,流量可以分布在所有可用的链接上,不用担心过载问题。随着更多的连接被接入到Leaf交换设备,我们的链路带宽收敛比将增加,可以通过增加Spine和Leaf设备间的链路带宽降低链路收敛比。Spine+Leaf网络架构的另一个好处就是,它提供了更为可靠的组网连接,因为Spine层面与Leaf层面是全交叉连接,任一层中的单交换机故障都不会影响整个网络结构。因此,任一层中的一个交换机的故障都不会使整个结构失效。(4)BGP EVPN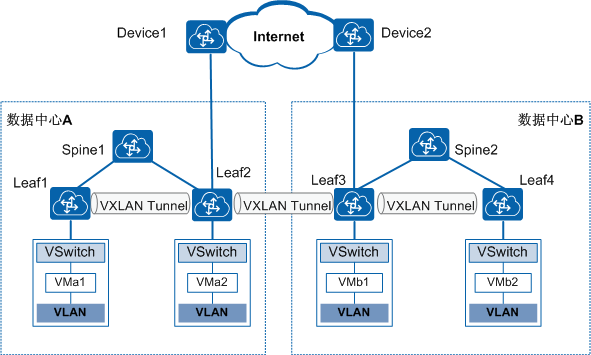 EVPN是基于BGP协议的技术,需要部署在网络交换机上。这意味着网络交换机需要作为VTEP节点,进行VXLAN封装。服务器通过接口或VLAN接入网络交换机。这些接口或VLAN会映射到对应的广播域BD,同时BD也会绑定一个EVPN实例,通过EVPN实例间路由的传递实现VXLAN隧道的建立、MAC学习。通过BGP EVPN在两个数据中心内部各建立一段VXLAN隧道,数据中心之间再建立一段VXLAN隧道,可以实现数据中心互联。三、数据中心网络的发展趋势 数据的集中处理、存储、传输、交换和管理无一不是在构建数字经济的基础设施。网络技术驱动数据中心网络从以“数据”为中心发展到了以“算力”为中心。相较传统的数据中心网络,现代大规模数据中心网络在架构、技术上和运维都发生了巨大变革,主要表现在:(1)网络带宽加速发展,构建高性能网络 网络支撑业务的底层连接,将网络设备上从管理平面、控制平面和数据平面进行分离,软件定义网络,用软件集中管理设备简化数据平面,让网络更智能,更简单。用先进的网络架构,实现在线和离线对业务网络的互联互通,灵活调度网络流量满足个性化业务需求,构建高带宽、低时延高性能网络才能满足日新月异的互联网业务要求。(2)高密度异构计算集群,大规模弹性扩展 数据中心网络将从交换机网络趋向以数据互联I/O为中心的架构,通过技术和规模弹性给用户提供低成本,高可靠的网络资源。提供更加安全,稳定的网络基础设施,根据业务需要弹性扩展,用更加简单的方式降本提效是下一代数据中心网络发展的指导原则。(3)降本提效,实现智能可视化运维 网络成本的优化,是很多互联网业务发展必不可少的一环。相比传统网络架构,大规模数据中心网络架构通过使用单芯片box设备进行构建数据中心网络,降低能耗,解决能耗瓶颈,同时在电力、散热、空间成本上进行降本提效。同时,随着网络规模不断扩大,人工运维不再现实,自动化运维部署,软件功能自动升级及故障自动告警,恢复等成为很多厂商设备建设数据中心努力的方向。
EVPN是基于BGP协议的技术,需要部署在网络交换机上。这意味着网络交换机需要作为VTEP节点,进行VXLAN封装。服务器通过接口或VLAN接入网络交换机。这些接口或VLAN会映射到对应的广播域BD,同时BD也会绑定一个EVPN实例,通过EVPN实例间路由的传递实现VXLAN隧道的建立、MAC学习。通过BGP EVPN在两个数据中心内部各建立一段VXLAN隧道,数据中心之间再建立一段VXLAN隧道,可以实现数据中心互联。三、数据中心网络的发展趋势 数据的集中处理、存储、传输、交换和管理无一不是在构建数字经济的基础设施。网络技术驱动数据中心网络从以“数据”为中心发展到了以“算力”为中心。相较传统的数据中心网络,现代大规模数据中心网络在架构、技术上和运维都发生了巨大变革,主要表现在:(1)网络带宽加速发展,构建高性能网络 网络支撑业务的底层连接,将网络设备上从管理平面、控制平面和数据平面进行分离,软件定义网络,用软件集中管理设备简化数据平面,让网络更智能,更简单。用先进的网络架构,实现在线和离线对业务网络的互联互通,灵活调度网络流量满足个性化业务需求,构建高带宽、低时延高性能网络才能满足日新月异的互联网业务要求。(2)高密度异构计算集群,大规模弹性扩展 数据中心网络将从交换机网络趋向以数据互联I/O为中心的架构,通过技术和规模弹性给用户提供低成本,高可靠的网络资源。提供更加安全,稳定的网络基础设施,根据业务需要弹性扩展,用更加简单的方式降本提效是下一代数据中心网络发展的指导原则。(3)降本提效,实现智能可视化运维 网络成本的优化,是很多互联网业务发展必不可少的一环。相比传统网络架构,大规模数据中心网络架构通过使用单芯片box设备进行构建数据中心网络,降低能耗,解决能耗瓶颈,同时在电力、散热、空间成本上进行降本提效。同时,随着网络规模不断扩大,人工运维不再现实,自动化运维部署,软件功能自动升级及故障自动告警,恢复等成为很多厂商设备建设数据中心努力的方向。相关阅读:
-
工业互联网关键技术研究(2024)
-
全网最全网络基础思维导图(38张)
-
存算一体算力网络创新与发展
-
网络安全等保基本要求
-
2024年网络安全趋势与预测
-
网络专题:工业交换机(2024)
-
新一代存储网络RoCE及配套iNOF技术
-
开放云网络高性能网关技术路线
-
云网络网关技术现状和趋势
-
确定性算力网络技术
-
无服务器边缘计算网络介绍
-
技术创新:算力网络纵深发展(2023)
-
一文掌握网络技术发展趋势(2023)
-
中国网络安全产业分析报告(2023年)
-
以网络IO为中心的无服务器数据中心白皮书(2023)
-
数据中心网络演进、趋势与挑战
-
如何计算并减少网络中的光纤损耗?
- Arm架构升级,v9与v8版本有何差异?
- 从X86到ARM,跨越CPU架构鸿沟
-
ARM vs x86云数据库性能深度测评与对比
-
从Arm v8到v9,服务器发展之路
-
ARM与x86:有何区别?
-
Arm增长突出,中国服务器市场占比达16%
-
分布式软件:X86/ARM CPU混合部署
-
Arm竞争加剧,全球众多巨头涌入
-
ARM处理器架构和天梯图解析
-
信创始于芯:Arm64体系结构编程与实践
-
ARM v8处理器概述、架构、及技术介绍
-
飞腾系和鲲鹏系:国产Arm架构CPU服务器正在崛起
-
Fujitsu A64FX:继承SPARC64架构的Arm超级处理器
-
收藏:从全球超算战略看ARM指令架构在HPC领域的发展
-
众多科技巨头涌入ARM,国内研发进展及玩家详解
-
亚马逊最新Arm服务器芯片详解
-
计算芯片变革:ARM取代x86成为趋势
-
国内外AI芯片、算力综合对比
-
华为算力编年史(2023)
-
AI算力研究框架(2023)
-
大模型训练,英伟达Turing、Ampere和Hopper算力分析
-
AI大语言模型原理、演进及算力测算
-
大算力模型,HBM、Chiplet和CPO等技术打破技术瓶颈
- 走进芯时代:AI算力GPU行业深度报告
- 高性能计算:RoCE技术分析及应用
- 高性能计算:谈谈被忽视的国之重器
- 高性能计算:RoCE v2 vs. InfiniBand网络该怎么选?
- 高性能网络全面向RDMA进军
-
数据中心的健康检查(电气篇)2016-03-18 0
-
锐捷助互联网数据中心网络自动化、可视化运维2017-01-25 0
-
网络发展怎么改变企业数据中心的面貌的2018-08-16 0
-
2019北京数据中心展览会2018-09-25 0
-
云数据中心市场的十大趋势2018-12-31 0
-
5G创新,半导体在未来的发展趋势将会如何?2019-12-03 0
-
未来数据中心与光模块发展假设2020-08-07 0
-
如何去推进新一代数据中心的发展?2021-05-25 0
-
数据中心太耗电怎么办2021-06-30 0
-
数据中心是什么2021-07-12 0
-
什么是数据中心2021-09-15 0
-
数据中心冷却技术是什么?发展趋势如何2019-11-25 6062
-
基于SDN的云计算数据中心网络将是未来云数据中心网络的发展趋势2019-12-03 2234
-
中国数据中心将呈现哪四高的发展趋势?2021-06-22 3283
-
SD-WAN组网案例——数据中心2023-07-28 353
全部0条评论

快来发表一下你的评论吧 !
