

英码科技EA500I基于昇腾Mind SDK实现实时人体关键点检测
描述
在教育、体育、安防、交通、医疗等领域中,实时人体关键点检测应用发挥着至关重要的作用,比如在体育训练时,实时人体关键点检测可以精确、实时地捕捉运动员的动作,从而进行动作分析和优化;在安防应用场景中,实时人体关键点检测应用可以用来识别异常行为或特定姿态,以达到场景安全防控的目的。
那么,什么是实时人体关键点检测?
简单来说,实时人体关键点检测是一种计算机视觉技术,它能够在图像或视频中实时地自动识别并标注出人体的关键部位,如关节点、头部等。
实时人体关键点检测在边缘计算领域的应用非常重要和广泛,今天我们来介绍:如何在英码科技EA500I边缘计算盒子上使用昇腾Mind SDK来实现实时人体关键点检测。

案例概述
本应用以英码科技EA500I边缘计算盒子为主要硬件平台,使用昇腾MindX SDK开发端到端人体关键点识别的参考设计,实现对视频中的人体进行关键点识别的功能。
案例说明
本案例参考华为昇腾Mind SDK 实时人体关键点检测,底层原理逻辑请参考:<昇腾社区应用案例>
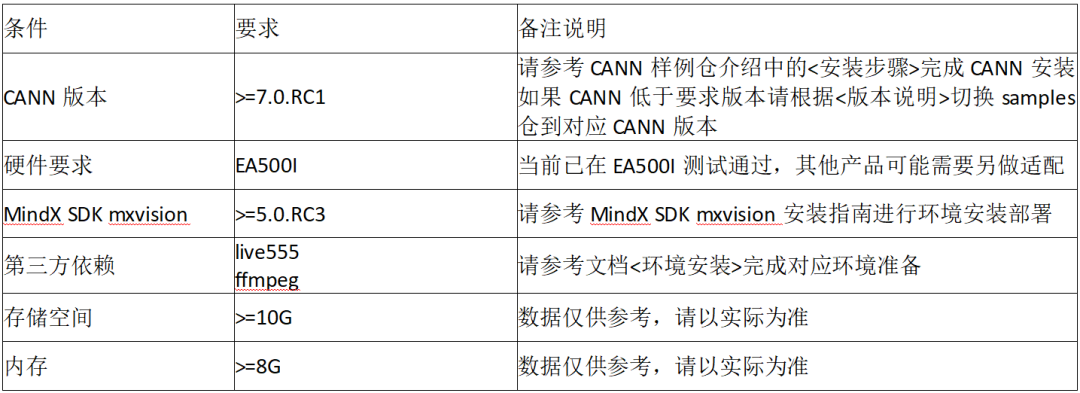
前置条件
1环境安装
●注意:
➢以下操作以普通用户HwHiAiUser安装CANN包为例说明,推荐使用root用户进行操作,如果是root用户,请将安装准备中所有的${HOME}修改为/usr/local。
➢推荐按照本文档路径进行操作,如安装在自定义路径可能会导致环境冲突等问题
①配置相关环境
# 以安装用户在任意目录下执行以下命令,打开.bashrc文件。vi ~/.bashrc # 在文件最后一行后面添加如下内容。source ${HOME}/Ascend/ascend-toolkit/set_env.shsource /home/work/MindX_SDK/mxVision-5.0.RC3/set_env.sh
export CPU_ARCH=`arch`export THIRDPART_PATH=${HOME}/Ascend/thirdpart/${CPU_ARCH} #代码编译时链接samples所依赖的相关库文件export LD_LIBRARY_PATH=${THIRDPART_PATH}/lib:$LD_LIBRARY_PATH #运行时链接库文件export INSTALL_DIR=${HOME}/Ascend/ascend-toolkit/latest #CANN软件安装后的文件存储路径,根据安装目录自行修改export DDK_PATH=${HOME}/Ascend/ascend-toolkit/latest #声明CANN环境export NPU_HOST_LIB=${DDK_PATH}/runtime/lib64/stub #声明CANN环境# 执行命令保存文件并退出。:wq! # 执行命令使其立即生效。source ~/.bashrc# 创建samples相关依赖文件夹mkdir -p ${THIRDPART_PATH}# 下载源码并安装gitcd ${HOME}sudo apt-get install gitgit clone https://gitee.com/ascend/samples.git# 拷贝公共文件到samples相关依赖路径中cp -r ${HOME}/samples/common ${THIRDPART_PATH} # 拷贝media_mini等so文件以及相关头文件mkdir -p ${INSTALL_DIR}/drivercp /usr/lib64/libmedia_mini.so ${INSTALL_DIR}/driver/ #如路径中没有相关so文件,可跳过该命令cp /usr/lib64/libslog.so ${INSTALL_DIR}/driver/cp /usr/lib64/libc_sec.so ${INSTALL_DIR}/driver/cp /usr/lib64/libmmpa.so ${INSTALL_DIR}/driver/cp /usr/local/Ascend/include/peripheral_api.h ${INSTALL_DIR}/driver/ #如路径中没有相关头文件,可跳过该命令# 下载案例源码并安装gitcd ${HOME}git clone https://gitee.com/ascend/mindxsdk-referenceapps.git
②安装x264插件
# 下载x264cd ${HOME}git clone https://code.videolan.org/videolan/x264.gitcd x264# 安装x264./configure --enable-shared --disable-asmmakesudo make installsudo cp /usr/local/lib/libx264.so.164 /lib
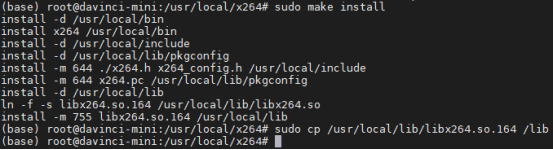
③安装部署ffmpeg
# 下载ffmpegcd ${HOME}wget http://www.ffmpeg.org/releases/ffmpeg-4.1.3.tar.gz --no-check-certificatetar -zxvf ffmpeg-4.1.3.tar.gzcd ffmpeg-4.1.3# 安装ffmpeg./configure --enable-shared --enable-pic --enable-static --disable-x86asm --enable-libx264 --enable-gpl --prefix=${THIRDPART_PATH} #此步骤报错可参考FAQmake -j8make install# 添加环境变量vi ~/.bashrc # 在文件最后一行后面添加如下内容。export PATH=${HOME}/Ascend/thirdpart/aarch64/bin:$PATH# 执行命令保存文件并退出。:wq! # 执行命令使其立即生效。source ~/.bashrc
④安装live555
# 下载相应版本的live555软件包,该版本测试可用,部分版本的软件包会有代码编译的报错cd ${HOME}wget http://www.live555.com/liveMedia/public/live.xxxx.xx.xx.tar.gz(请根据实际版本下载)tar -zxvf live.xxxx.xx.xx.tar.gzcd live/# 修改config.linuxvi config.linux找到:CPLUSPLUS_FLAGS = $(COMPILE_OPTS) -Wall -DBSD=1替换为:CPLUSPLUS_FLAGS = $(COMPILE_OPTS) -Wall -DBSD=1 -std=c++2a# 执行命令保存文件并退出。:wq! # 配置视频循环推流,按照以下提示修改文件可以使自主搭建的rtsp循环推流,如果不作更改,则为有限的视频流cd ./liveMedia/vi ByteStreamFileSource.cpp# 在liveMedia库下的ByteStreamFileSource.cpp文件中的95行,找到:void ByteStreamFileSource::doGetNextFrame() {
if (feof(fFid) || ferror(fFid) || (fLimitNumBytesToStream && fNumBytesToStream == 0)){ handleClosure(); return; }# 替换为:void ByteStreamFileSource::doGetNextFrame() {
if (feof(fFid) || ferror(fFid) || (fLimitNumBytesToStream && fNumBytesToStream == 0)) { //handleClosure();** //return;** fseek(fFid, 0, SEEK_SET); }# 执行命令保存文件并退出。:wq! # 编译并安装cd .../genMakefiles linux #注意后面这个参数是根据当前文件夹下config.<后缀>获取得到的,与服务器架构等有关。make -j8# 编译完成后就会在当前目录下生成mediaServer 文件夹,有一个live555MediaServer可执行文件# 防止推流丢帧cd ../mediaServervi DynamicRTSPServer.cpp在mediaServer的DynamicRTSPServer.cpp文件中,修改每一处OutPacketBuffer::maxSize的值,更改到800000,该版本有三处需要修改。# 执行命令保存文件并退出。:wq!# 修改了代码后需要重新执行编译cd ..make clean./genMakefiles linux #注意后面这个参数是根据当前文件夹下config.<后缀>获取得到的,与服务器架构等有关。make -j8# 转换MP4文件,把需要推流的人体MP4视频文件上传到相应目录,执行命令转换成h264文件,相应参数请自行修改ffmpeg -i test.mp4 -vcodec h264 -bf 0 -g 25 -r 10 -s 1280*720 -an -f h264 test1.264//-bf B帧数目控制,-g 关键帧间隔控制,-s 分辨率控制 -an关闭音频, -r 指定帧率# 把转换后的h264文件拷贝到${HOME}/live/mediaServer/路径下# 启动推流./live555MediaServer# 启动完成会输出推流地址,其中rtsp_Url的格式是 rtsp://host:port/Data,host:port/路径映射到mediaServer/目录下,Data为视频文件的路径。例:rtsp://10.1.30.111:80/test1.h264# 启动成功后该终端窗口会一直推流,请另开一个终端窗口进行后续步骤
2模型获取&转换
# 进入案例路径,mindxsdk-referenceapps为前置步骤中下载的案例包cd ${HOME}/mindxsdk-referenceapps/contrib/RTMHumanKeypointsDetection# 在models路径下下载原始模型,下列链接可下载512x512的onnx模型文件cd ./modelswget https://mindx.sdk.obs.cn-north-4.myhuaweicloud.com/mindxsdk-referenceapps%20/contrib/RTMHumanKeypointsDetection/human-pose-estimation512.onnx --no-check-certificate# 进入"${RTMHumanKeypointsDetection代码包目录}/models/"目录,对"insert_op.cfg"文件做以下修改related_input_rank: 0src_image_size_w: 512 # onnx模型输入的宽,请根据对应模型进行修改,如使用本案例文档下载的原始模型,则不需要修改src_image_size_h: 512 # onnx模型输入的高,请根据对应模型进行修改,如使用本案例文档下载的原始模型,则不需要修改crop: false# 使用ATC工具进行模型转换atc --model=./human-pose-estimation512.onnx --framework=5 --output=openpose_pytorch_512 --soc_version=Ascend310B1 --input_shape="data:1, 3, 512, 512" --input_format=NCHW --insert_op_conf=./insert_op.cfg
3编译运行案例
# 修改RTMHumanKeypointsDetection/pipeline目录下的rtmOpenpose.pipeline文件中mxpi_rtspsrc0的内容。 "mxpi_rtspsrc0": { "factory": "mxpi_rtspsrc", "props": { "rtspUrl":"rtsp://xxx.xxx.xxx.xxx:xxxx/xxx.264", // 修改为自己所使用的的服务器和文件名,例:rtsp://10.1.30.111:80/test1.h264 "channelId": "0" }, "next": "mxpi_videodecoder0" }, # 注意检查om模型文件名是否和pipeline/rtmOpenpose.pipeline中的mxpi_tensorinfer0 插件 modelPath 属性值相同,若不同需改为一致。 "mxpi_tensorinfer0":{ "next":"mxpi_rtmopenposepostprocess0", "factory":"mxpi_tensorinfer", "props":{ "dataSource": "mxpi_imageresize0", "modelPath":"./models/openpose_pytorch_512.om"//检查om模型文件名是否正确 } },# 若修改了模型的输入尺寸,还需要将 mxpi_imageresize0 插件中的 resizeWidth 和 resizeHeight 属性改成修改后的模型输入尺寸值;将 mxpi_rtmopenposepostprocess0 插件中的 inputWidth 和 inputHeight 属性改成修改后的模型输入尺寸值。 "mxpi_imageresize0":{ "next":"queue3", "factory":"mxpi_imageresize", "props":{ "interpolation":"2", "resizeWidth":"512",//输入的宽,请根据对应模型进行修改 "resizeHeight":"512",//输入的高,请根据对应模型进行修改 "dataSource":"mxpi_videodecoder0", "resizeType":"Resizer_KeepAspectRatio_Fit" } }, ...... "mxpi_rtmopenposepostprocess0":{ "next":"queue4", "factory":"mxpi_rtmopenposepostprocess", "props":{ "imageSource":"mxpi_videodecoder0", "inputHeight":"512",//输入的高,请根据对应模型进行修改 "dataSource":"mxpi_tensorinfer0", "inputWidth":"512"//输入的宽,请根据对应模型进行修改 } },# 将pipeline里面的 mxpi_videoencoder0 插件中的 imageHeight 和 imageWidth 更改为上传视频的实际高和宽。 "mxpi_videoencoder0":{ "props": { "inputFormat": "YUV420SP_NV12", "outputFormat": "H264", "fps": "1", "iFrameInterval": "50", "imageHeight": "720",#上传视频的实际高 "imageWidth": "1280"#上传视频的实际宽 },# 本项目需要使用 mxpi_opencvosd 插件,使用前需要生成所需的模型文件。执行MindX SDK开发套件包安装目录下 operators/opencvosd/generate_osd_om.sh 脚本生成所需模型文件。例:bash /home/work/MindX_SDK/mxVision-5.0.RC3/operators/opencvosd/generate_osd_om.sh# 编译项目cd ${HOME}/mindxsdk-referenceapps/contrib/RTMHumanKeypointsDetectionvi CMakeLists.txt# 在target_link_libraries处添加:cpprest例:target_link_libraries(main glog mxbase cpprest plugintoolkit mxpidatatype streammanager mindxsdk_protobuf)cd ./pluginsbash build.sh# 运行推理bash run.sh# 运行成功后如无报错会在当前路径下生成一个out.h264文件# 转换为MP4文件ffmpeg -i out.h264 -c copy output.mp4
4案例展示转换为MP4文件后,可以看到视频中的人体关键点。
至此,实时人体关键点检测应用部署成功,以下是英码科技技术工程师在实际操作过程中遇到的相关FAQ,供大家参考~
5相关FAQ
①安装ffmpeg执行命令:./configure时报错:“Unable to create and execute files in /tmp. Set the TMPDIR environm”➢该报错可能是环境问题
# 声明相关环境
export TMPDIR=~/tmp-ffmpeg
mkdir $TMPDIR
# 之后再执行./configure .......
②如果在使用Live555进行拉流时,依旧出现”The input frame data was too large for our buffer“问题,导致丢帧。➢尝试进行下列优化
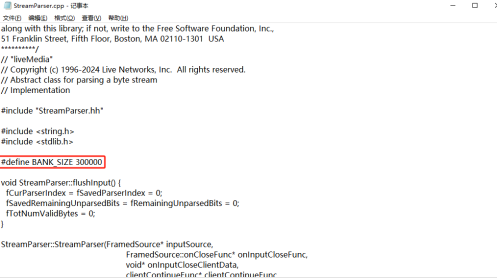
在“live/liveMedia/StreamParser.cpp”中扩展帧解析buffer大小,即BANK_SIZE,默认值为150k,根据传输的H264数据帧大小,至少设置为300k。否则超出大小,可能会被Live555抛弃。
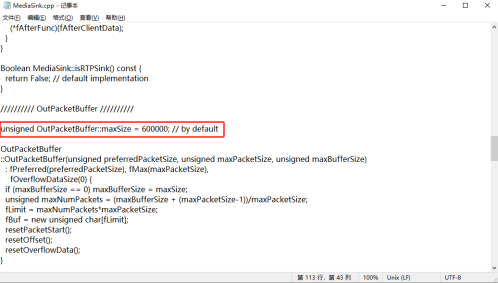
在“live/liveMedia/MediaSink.cpp”中增加OutPacketBuffer::maxSize大小,同样为了容纳超大帧数据,否则可能会导致数据丢失,设置为 600000。
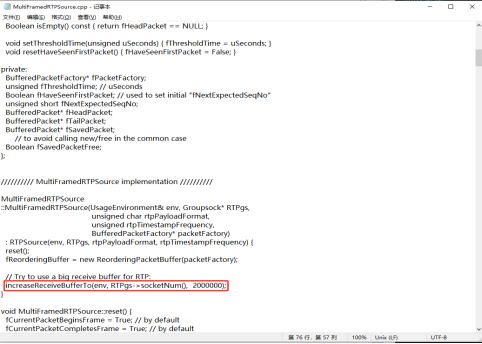
在“live/liveMedia/MultiFramedRTPsource.cpp”中增加socket发送缓冲区大小,即increaseSendBufferTo函数的参数值--increaseRecieveBufferTo(env, RTPgs-> socketNUm(), 2000000)”
结语
 以上就是英码科技EA500I边缘计算盒子基于昇腾Mind SDK实现实时人体关键点检测应用的全部操作内容,将持续推出更多基于昇腾AI芯片的边缘计算盒子和技术干货,欢迎大家持续关注和留言交流~
以上就是英码科技EA500I边缘计算盒子基于昇腾Mind SDK实现实时人体关键点检测应用的全部操作内容,将持续推出更多基于昇腾AI芯片的边缘计算盒子和技术干货,欢迎大家持续关注和留言交流~
-
[11.12]--实时人体姿态点检测jf_75936199 2023-04-28
-
昇润 CC2640 SDK 应用入门教程一2017-02-06 0
-
如何使用Tengine Explore版在firefly-RK3399上实现实时目标检测?2022-03-04 0
-
Firefly RK3399Pro开源主板 + 单目摄像头,人体特征点检测方案2022-04-01 0
-
怎样使用Rock-X SDK对人体骨骼点关键点进行开发获取呢2022-06-29 0
-
一种基于基音频率的实时性端点检测方法2009-12-16 632
-
DM6446平台的实时人眼检测系统2017-10-26 831
-
树莓派上使用OpenCV和Python实现实时人脸检测2018-03-06 50828
-
firefly人体特征点检测介绍2019-11-05 1307
-
一种改进的人体关键点检测算法2021-05-14 530
-
用于实时PCR扩增或LAMP终点检测的微流控芯片2023-01-29 967
-
【昇腾系列产品应用】英码科技EA500I边缘计算盒子接口使用示例和目标检测算法演示2024-03-30 73
全部0条评论

快来发表一下你的评论吧 !
