

创图像分类速度新高: Xilinx Kintex UltraScale FPGA + xDNN Library + AlexNet + Caffe
FPGA/ASIC技术
描述
神经网络起源于上世纪五六十年代,当时还叫感知机,分为输入层、隐含层和输出层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。早期的感知机只有单层,随着科学的发展,直到八十年代才被发明出多层感知机,多层感知机可以使用sigmoid或tanh等连续函数模拟神经元对激励的响应,在训练算法上采用反向的BP算法,这就是我们现在所说的神经网络NN。而多层感知机给我们的启示是,神经网络的层数直接决定了他对现实的刻画能力,所以随着研究的深入出现了如今的DNN深度神经网络。
目前,神经网络已经广泛应用在语音识别,图像处理,机器视觉等人工智能领域。其中,在2012年的图像分类挑战赛中,Geoffrey和他的学生Alex提出了AlexNet这个经典之作,刷新了图像分类的记录,取得本次挑战赛冠军,并一举奠定了深度学习在计算机视觉中的地位。之后几年,许多更深的神经网络被提出,比如优秀的VGG,GoogleNet。
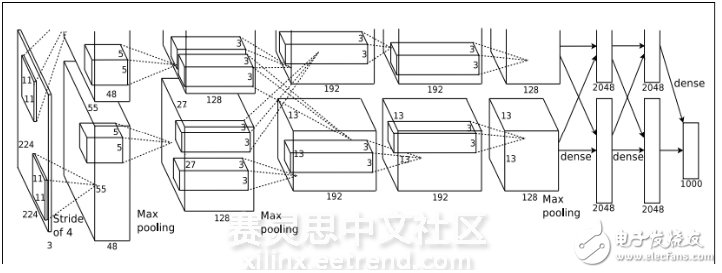
图1 AlexNet的结构模型
Xilinx Kintex UltraScale FPGA + xDNN Library + AlexNet + Caffe:
在2012年之后,深度学习席卷而来,一统天下,所向披靡。各类神经网络模型如雨后春笋涌现,DNN,CNN,RNN,SDA,RBP,RBM从一种思想迅速被应用到实际神经网络算法函数中,神经网络对语音识别的速度,对图像识别的速度每日都在刷新着记录。
想看一下机器推理的运算速度有多快,效率有多高吗?在上月末,Xilinx推出了一段视频,这个视频向你展示了在FPGA上利用8位整数实现AlexNet inage-classification算法时有多快(快于1800 image classification/sec),有多高效(低于50W的功率消耗)。这个视频中的demo展示的是在Xilinx UltraScale FPGA上利用xDNN深度神经网络来实现开源的Caffe 深度学习结构,当然开发过程是在Xilinx Kintex UltraScale FPGA 加速器开发套件上实现的。以上的所有部分都包含在Xilinx 可编程加速堆中。
图2 Xilinx UltraScale FPGA套件
同时,如果你可以用16位整数实现这个demo,那么你可以达到demo中一般的性能,详细信息可在xilinx官网看到( https://forums.xilinx.com/t5/Xcell-Daily-Blog/Counter-Intuitive-Fixed-Po... )。
Why?
众所周知,目前的大部分算法加速,神经网络都是由软件程序来实现的,这些软件程序往往都十分庞大,数据量也十分庞大,对相应PC硬件的要求也十分高。近年来,出现了一波加速器芯片,这些芯片都是针对特定算法实现硬件加速设计的,成本较高,进入市场的时间十分缓慢。
Xilinx公司推出的 Kintex UltraScale FPGA(包含在Xilinx 可编程加速堆系列中),内部集成了可重构的可编程加速堆,这是专门针对密集型计算的数据分析和人工智能应用而设计的。可以将类似于上文中的神经网络结构在此加速堆上实现,提高其运行速度(硬件并行运算总是快于软件的),从而达到机器推理的高效快速运算。
总结:
现在,深度学习,机器学习,神经网络席卷我们周围的所有大型运算,高科技前沿领域。FPGA作为硬件领域的中坚力量,利用硬件的独特优势积极加入,软硬件互相促进发展,是当前技术发展的趋势。Xilnx 作为FPGA领域的领头羊,有何理由不积极推进呢?
-
Xilinx UltraScale 系列发布常见问题汇总2013-12-17 0
-
Xilinx Kintex UltraScale XCKU040 FPGA 电源解决方案PMP10630技术资料下载2018-07-13 0
-
基于UCD90120A的Xilinx Ultrascale Kintex FPGA 电源解决方案包括原理图,物料清单及CAD文件2018-08-09 0
-
用于Xilinx Ultrascale Kintex FPGA多路千兆位收发器(MGT)的电源解决方案2018-08-10 0
-
Xilinx扩展20 nm Kintex UltraScale产品阵容2014-11-06 1139
-
Xilinx Ultrascale Kintex FPGA 电源解决方案2017-02-08 349
-
用于Xilinx Ultrascale Kintex FPGA多路千兆位收发器 (MGT) 的电源解决方案2017-02-08 433
-
直击关于Xilinx UltraScale架构、Virtex和Kintex UltraScale架构FPGA 和最新的Vivado开发工具的9大要点2017-02-08 509
-
K800:Kintex UltraScale™ PCI Express平台2017-02-08 435
-
Xilinx FPGA如何通过深度学习图像分类加速机器学习2018-11-28 3546
-
Kintex UltraScale FPGA KCU105评估套件的特点性能介绍2018-11-26 4528
-
Xilinx的Kintex UltraScale FPGA的数据手册和直流和交流开关特性2019-02-20 621
-
Kintex UltraScale FPGA的数据手册和直流和交流开关特性说明2019-02-21 614
-
赛灵思推出了Kintex UltraScale+ KU19P FPGA2020-08-03 3661
-
Xilinx FPGA KCU105 分享下载2021-10-11 389
全部0条评论

快来发表一下你的评论吧 !
