
资料下载


×
基于内存控制的流水线处理方法
消耗积分:1 |
格式:rar |
大小:0.4 MB |
2017-10-30
分享资料个
随着个人计算机和计算机网络的飞速发展,以及信息化的高速推进,互联网提供的信息总量也在迅猛增长。如果企业和社会组织实现数据共享,可以使更多的人更充分地利用已有的数据资源。可是为不同应用服务的信息都存储在许多不同的数据源之中,数据内容以及数据格式千差万别,且其管理系统也各不相同。如何对这些数据进行有效的集成管理,屏蔽这些信息的异构,并提供一个统一的访问接口以透明地访问各信息源,成为一些大型企业或社会组织关心的事情。数据集成正是在这一背景下提出的。
1 基于数据复制方法的集成模式
数据复制方法[1]是当前比较常用的数据集成模式,该方法将各个数据源的数据复制到与其相关的其他数据源上,并维护数据源整体上的数据一致性、提高信息共享利用的效率。这种方式可以复制信息源的整个数据,也可以是信息源的部分信息。数据复制方法在用户使用某个数据源之前,将用户可能用到的其他数据源的数据预先复制过来,如果用户要使用的数据已经被复制,则只需要查询该集成信息源,并与中介器/包装器的虚拟数据集成[2]相比,大大提高了系统处理用户请求的效率。
基于数据复制方式最常见的一种方法是数据仓库方法[1]。该方法将各个数据的全部或者部分数据复制到数据仓库,用户像访问普通数据库一样直接访问数据仓库。该方式实现了对物理数据库语义异构的屏蔽和数据访问的控制,提供了一个统一的数据逻辑视图来隐藏底层的数据细节。图1所示为一个典型的数据仓库体系结构图[3]。
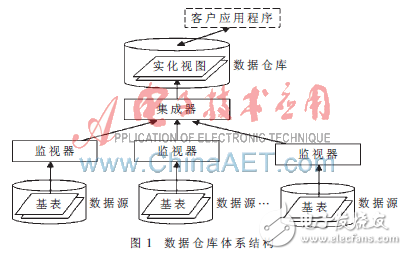
在该集成模型中,每一个数据源对应一个监视器(Monitor),监视器负责收集所需要集成的信息源中数据的变化以便上报给集成端(收集的方式有如下类别:针对信息源有日志的情况,可以通过日志分析提取要上报的增量;对于没有日志情况可以通过触发器方式或者快照差分方式获取信息源的增量),同时监视器还具有一个包装器的功能,提供信息源的数据查询提取以及类型转化功能。当作为数据查询功能的时候,不仅将数据初始化同步到数据仓库中,同时也相当于一个服务器,不断侦听来自于集成器的命令查询请求,当有请求到达时,执行查询,并将该监视器对应的数据源的数据包装成基于公共类型的数据,或以XML文件的方式和固定大小对象数据块的方式传递给集成器,然后集成器负责将提取后的数据进行合成。其中监视器与集成器中的通信流程如图2所示。

1 基于数据复制方法的集成模式
数据复制方法[1]是当前比较常用的数据集成模式,该方法将各个数据源的数据复制到与其相关的其他数据源上,并维护数据源整体上的数据一致性、提高信息共享利用的效率。这种方式可以复制信息源的整个数据,也可以是信息源的部分信息。数据复制方法在用户使用某个数据源之前,将用户可能用到的其他数据源的数据预先复制过来,如果用户要使用的数据已经被复制,则只需要查询该集成信息源,并与中介器/包装器的虚拟数据集成[2]相比,大大提高了系统处理用户请求的效率。
基于数据复制方式最常见的一种方法是数据仓库方法[1]。该方法将各个数据的全部或者部分数据复制到数据仓库,用户像访问普通数据库一样直接访问数据仓库。该方式实现了对物理数据库语义异构的屏蔽和数据访问的控制,提供了一个统一的数据逻辑视图来隐藏底层的数据细节。图1所示为一个典型的数据仓库体系结构图[3]。
在该集成模型中,每一个数据源对应一个监视器(Monitor),监视器负责收集所需要集成的信息源中数据的变化以便上报给集成端(收集的方式有如下类别:针对信息源有日志的情况,可以通过日志分析提取要上报的增量;对于没有日志情况可以通过触发器方式或者快照差分方式获取信息源的增量),同时监视器还具有一个包装器的功能,提供信息源的数据查询提取以及类型转化功能。当作为数据查询功能的时候,不仅将数据初始化同步到数据仓库中,同时也相当于一个服务器,不断侦听来自于集成器的命令查询请求,当有请求到达时,执行查询,并将该监视器对应的数据源的数据包装成基于公共类型的数据,或以XML文件的方式和固定大小对象数据块的方式传递给集成器,然后集成器负责将提取后的数据进行合成。其中监视器与集成器中的通信流程如图2所示。

声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
评论(0)
发评论
- 相关下载
- 相关文章







