

BP神经网络编码样例及工作原理
编程语言及工具
描述
人工神经网络是一种经典的机器学习模型,随着深度学习的发展神经网络模型日益完善。联想大家熟悉的回归问题, 神经网络模型实际上是根据训练样本创造出一个多维输入多维输出的函数, 并使用该函数进行预测, 网络的训练过程即为调节该函数参数提高预测精度的过程.神经网络要解决的问题与最小二乘法回归解决的问题并无根本性区别。
回归和分类是常用神经网络处理的两类问题, 如果你已经了解了神经网络的工作原理可以在 上体验一个浅层神经网络的工作过程。
感知机(Perceptron)是一个简单的线性二分类器, 它保存着输入权重, 根据输入和内置的函数计算输出.人工神经网络中的单个神经元即是感知机。
在前馈神经网络的预测过程中, 数据流从输入到输出单向流动, 不存在循环和返回的通道。
目前大多数神经网络模型都属于前馈神经网络, 在下文中我们将详细讨论前馈过程。
多层感知机(Multi Layer Perceptron, MLP)是由多个感知机层全连接组成的前馈神经网络, 这种模型在非线性问题中表现出色。
所谓全连接是指层A上任一神经元与临近层B上的任意神经元之间都存在连接。
反向传播(Back Propagation,BP)是误差反向传播的简称,这是一种用来训练人工神经网络的常见算法, 通常与最优化方法(如梯度下降法)结合使用。
本文介绍的神经网络模型在结构上属于MLP, 因为采用BP算法进行训练, 人们也称其为BP神经网络。
BP神经网络原理
经典的BP神经网络通常由三层组成: 输入层, 隐含层与输出层.通常输入层神经元的个数与特征数相关,输出层的个数与类别数相同, 隐含层的层数与神经元数均可以自定义。
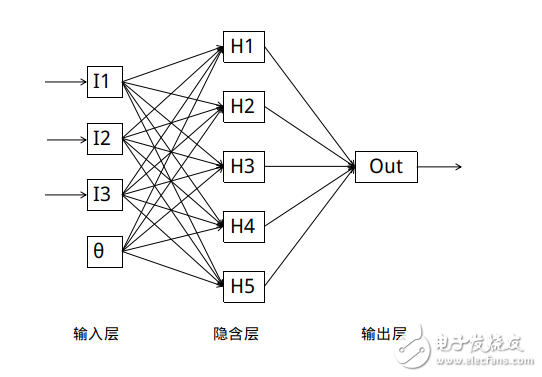
每个神经元代表对数据的一次处理:

每个隐含层和输出层神经元输出与输入的函数关系为:

我们用一个完成训练的神经网络处理回归问题, 每个样本拥有n个输入.相应地,神经网络拥有n个输入神经元和1个输出神经元。
实际应用中我们通常在输入层额外增加一个偏置神经元, 提供一个可控的输入修正;或者为每个隐含层神经元设置一个偏置参数。
我们将n个特征依次送入输入神经元, 隐含层神经元获得输入层的输出并计算自己输出值, 输出层的神经元根据隐含层输出计算出回归值。
上述过程一般称为前馈(Feed-Forward)过程, 该过程中神经网络的输入输出与多维函数无异。
现在我们的问题是如何训练这个神经网络。
作为监督学习算法,BP神经网络的训练过程即是根据前馈得到的预测值和参考值比较, 根据误差调整连接权重Wij的过程。
训练过程称为反向传播过程(BackPropagation), 数据流正好与前馈过程相反。
首先我们随机初始化连接权重Wij, 对某一训练样本进行一次前馈过程得到各神经元的输出。
首先计算输出层的误差:


为了避免神经网络进行无意义的迭代, 我们通常在训练数据集中抽出一部分用作校验.当预测误差高于阈值时提前终止训练。
Python实现BP神经网络
首先实现几个工具函数:
def rand(a, b):
return (b - a) * random.random() + a
def make_matrix(m, n, fill=0.0): # 创造一个指定大小的矩阵
mat = []
for i in range(m):
mat.append([fill] * n)
return mat
定义sigmod函数和它的导数:
def sigmoid(x):
return 1.0 / (1.0 + math.exp(-x))
def sigmod_derivate(x):
return x * (1 - x)
定义BPNeuralNetwork类, 使用三个列表维护输入层,隐含层和输出层神经元, 列表中的元素代表对应神经元当前的输出值.使用两个二维列表以邻接矩阵的形式维护输入层与隐含层, 隐含层与输出层之间的连接权值, 通过同样的形式保存矫正矩阵。
定义setup方法初始化神经网络:
def setup(self, ni, nh, no):
self.input_n = ni + 1
self.hidden_n = nh
self.output_n = no
# init cells
self.input_cells = [1.0] * self.input_n
self.hidden_cells = [1.0] * self.hidden_n
self.output_cells = [1.0] * self.output_n
# init weights
self.input_weights = make_matrix(self.input_n, self.hidden_n)
self.output_weights = make_matrix(self.hidden_n, self.output_n)
# random activate
for i in range(self.input_n):
for h in range(self.hidden_n):
self.input_weights[i][h] = rand(-0.2, 0.2)
for h in range(self.hidden_n):
for o in range(self.output_n):
self.output_weights[h][o] = rand(-2.0, 2.0)
# init correction matrix
self.input_correction = make_matrix(self.input_n, self.hidden_n)
self.output_correction = make_matrix(self.hidden_n, self.output_n)
定义predict方法进行一次前馈, 并返回输出:
def predict(self, inputs):
# activate input layer
for i in range(self.input_n - 1):
self.input_cells[i] = inputs[i]
# activate hidden layer
for j in range(self.hidden_n):
total = 0.0
for i in range(self.input_n):
total += self.input_cells[i] * self.input_weights[i][j]
self.hidden_cells[j] = sigmoid(total)
# activate output layer
for k in range(self.output_n):
total = 0.0
for j in range(self.hidden_n):
total += self.hidden_cells[j] * self.output_weights[j][k]
self.output_cells[k] = sigmoid(total)
return self.output_cells[:]
定义back_propagate方法定义一次反向传播和更新权值的过程, 并返回最终预测误差:
def back_propagate(self, case, label, learn, correct):
# feed forward
self.predict(case)
# get output layer error
output_deltas = [0.0] * self.output_n
for o in range(self.output_n):
error = label[o] - self.output_cells[o]
output_deltas[o] = sigmod_derivate(self.output_cells[o]) * error
# get hidden layer error
hidden_deltas = [0.0] * self.hidden_n
for h in range(self.hidden_n):
error = 0.0
for o in range(self.output_n):
error += output_deltas[o] * self.output_weights[h][o]
hidden_deltas[h] = sigmod_derivate(self.hidden_cells[h]) * error
# update output weights
for h in range(self.hidden_n):
for o in range(self.output_n):
change = output_deltas[o] * self.hidden_cells[h]
self.output_weights[h][o] += learn * change + correct * self.output_correction[h][o]
self.output_correction[h][o] = change
# update input weights
for i in range(self.input_n):
for h in range(self.hidden_n):
change = hidden_deltas[h] * self.input_cells[i]
self.input_weights[i][h] += learn * change + correct * self.input_correction[i][h]
self.input_correction[i][h] = change
# get global error
error = 0.0
for o in range(len(label)):
error += 0.5 * (label[o] - self.output_cells[o]) ** 2
return error
定义train方法控制迭代, 该方法可以修改最大迭代次数, 学习率λ, 矫正率μ三个参数。
def train(self, cases, labels, limit=10000, learn=0.05, correct=0.1):
for i in range(limit):
error = 0.0
for i in range(len(cases)):
label = labels[i]
case = cases[i]
error += self.back_propagate(case, label, learn, correct)
编写test方法,演示如何使用神经网络学习异或逻辑:
def test(self):
cases = [
[0, 0],
[0, 1],
[1, 0],
[1, 1],
]
labels = [[0], [1], [1], [0]]
self.setup(2, 5, 1)
self.train(cases, labels, 10000, 0.05, 0.1)
for case in cases:
print(self.predict(case))
-
神经网络教程(李亚非)2012-03-20 0
-
求利用LABVIEW 实现bp神经网络的程序2012-11-26 0
-
神经网络50例2012-11-28 0
-
关于BP神经网络预测模型的确定!!2014-02-08 0
-
用labview框图编写的BP神经网络程序vi2015-05-28 0
-
labview BP神经网络的实现2017-02-22 0
-
基于BP神经网络的辨识2018-01-04 0
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 0
-
如何设计BP神经网络图像压缩算法?2019-08-08 0
-
BP神经网络PID控制电机模型仿真2020-02-22 0
-
BP神经网络的基础数学知识分享2020-06-16 0
-
基于BP神经网络的PID控制2021-09-07 0
-
基于BP神经网络的农业气象产量预报系统2010-02-23 497
-
BP神经网络概述2018-06-19 43187
-
BP神经网络原理及应用2021-04-27 838
全部0条评论

快来发表一下你的评论吧 !
