

使FPGA进军ASIC级设计领域的方法步骤
FPGA/ASIC技术
描述
不久前发生在ASIC上的问题现又在FPGA上重演。到底是什么问题?那就是布线延迟对于设计性能的主导作用。多年以来,登纳德缩放比例定律(Dennard scaling)增加了晶体管速度,同时摩尔定律的扩展增加了每平方毫米的晶体管密度。糟糕的是对于互联来说其效果正好相反。电线因摩尔定律扩展而变得更细更扁,但速度却变得更慢。最终,晶体管延迟降低到无足轻重的程度,而布线延迟却成为主导。随着FPGA密度的增加以及赛灵思UltraScale™ All Programmable器件进军ASIC级设计领域,相同的问题又出现了。UltraScale器件经过重新设计后能够克服这种问题,但解决方案却并不方便简单。以下来介绍一下解决方案的各个步骤。
步骤1:压缩模块,以使信号无需传送太远。
听起来很明确是不是?必要性是新发明的原动力,是时候在UltraScale密度方面采取行动了。UltraScale架构中的CLB已经过重新设计,这样Vivado®设计套件就能更高效地将逻辑排列到CLB中。逻辑模块设计使排列变得更加紧密,因此CLB间的布线资源需求量就会变得更少。布线路径也变得更短。UltraScale架构中CLB的变化包括:为CLB中的每个触发器增加专用输入与输出(这样触发器就能单独使用从而实现更高利用率);添加更多触发器时钟使能;为CLB的移位寄存器和分布式RAM组件添加独立时钟。从概念上讲,改进后的CLB使用和排列情况如图1中的框图所示。
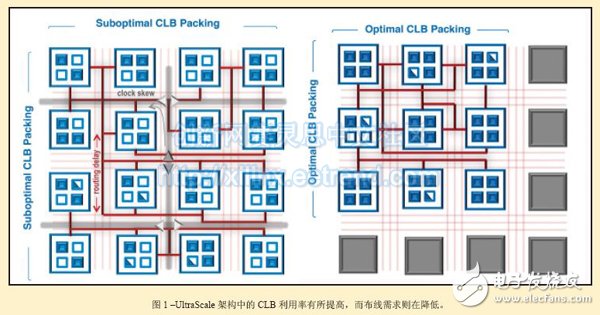
该实例显示,之前采用16个CLB的电路模块现在用9个改进后的UltraScale CLB即可实现。图中蓝色小方块和三角形的分布情况表明CLB的利用率已提高,红线的减少说明对布线数量的需求也在降低。
步骤2:添加更多布线资源。
这种情况下的收效会快速递减,除非采取措施解决该问题。对于UltraScale架构来说,解决方案涉及添加更多的本地布线资源,从而使可布线性能够随CLB密度的增加更快速地提高。图2显示了该结果。
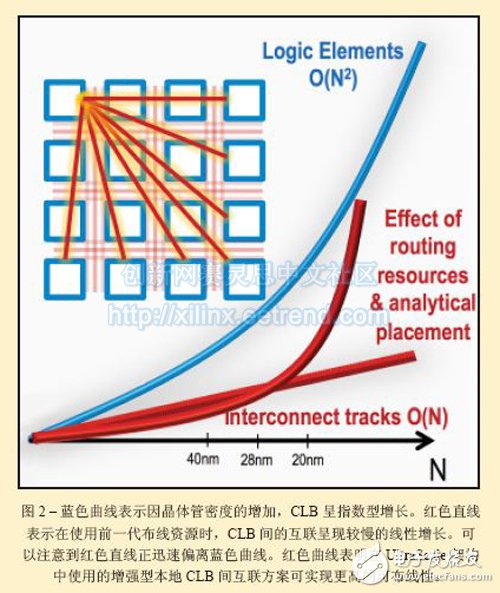
但是,仅仅增加硬件布线资源是不够的。您还必须加强设计工具的布局布线算法,以便其能够利用这些新资源。赛灵思Vivado设计套件已相应地进行了升级。
步骤3:处理不断增加的时钟歪斜。
您可能不知道,过去的FPGA时钟分配过于简单了。早期几代的FPGA依靠一个由IC几何中心成扇形散开的中央时钟分配中枢为所有片上逻辑提供时钟。这种全局时钟方案在诸如Virtex UltraScale和Kintex UltraScale All Programmable器件系列的ASIC级FPGA中行不通。不断提高的CLB密度和持续增加的时钟速率不允许这样做。因此,UltraScale器件采用了一种经过彻底改进的时钟方案,如图3所示。
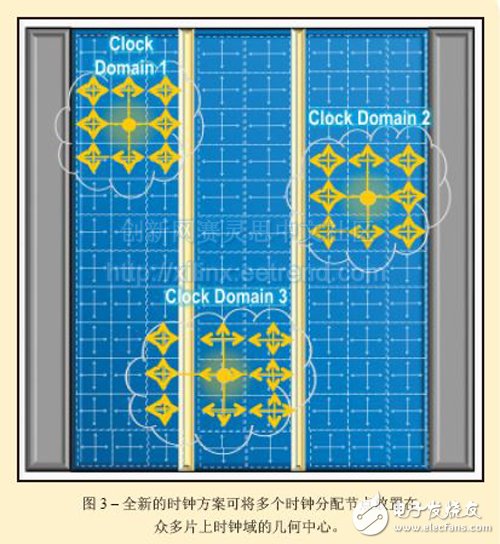
UltraScale架构的时钟分配网络包含一个区域化的分段时钟基础架构(segmented clocking infrastructure),该结构可将多个时钟分配节点放在众多片上时钟域的几何中心。再由独立的时钟分配节点驱动从适当大小的基础架构分段(infrastructure segment)中构建的独立时钟树。这种方案至少有三个主要优势:
1. 时钟歪斜快速减小;
2. 可用的时钟资源显著增多;
3. 时序收敛立刻变得更加简单。
然而,这样不足以改善时钟基础架构,除非设计工具也能支持新的时钟方案。为此,Vivado设计套件相应地进行了升级,因为该套件针对的是步骤2中讨论的改良型CLB间布线。
赛灵思必须针对以上三大步骤的每个步骤进行硬件架构和设计工具方面的重大更改。这就是赛灵思所指的可对UltraScale架构和Vivado设计套件进行协同优化。这需要做出很大的努力,并且也绝对是实现ASIC级All Programmable器件组合必须要做的工作。
-
到底什么是ASIC和FPGA?2024-01-23 0
-
cogoask讲解fpga和ASIC是什么意思2012-02-27 0
-
FPGA vs ASIC 你看好谁?2017-09-02 0
-
ASIC和FPGA的区别2019-07-19 0
-
ASIC设计领域大不如前2019-07-19 0
-
软件无线电设计中选择ASIC、FPGA和DSP需要考虑哪些因素?2019-08-16 0
-
软件无线电设计中ASIC、FPGA和DSP该怎么选择?2019-09-02 0
-
如何实现ASIC RAM替换为FPGA RAM?2020-04-24 0
-
ASIC设计转FPGA时的注意事项2010-09-10 995
-
FPGA、ASIC将在机器学习领域崛起2018-01-06 4835
-
FPGA设计方法比ASIC好在哪里2019-09-14 2328
-
在FPGA中配置PLL的步骤及使用方法2021-05-28 795
-
FPGA_ASIC-DSP和FPGA共用FLASH进行配置的方法2021-07-30 683
-
FPGA和ASIC的区别与联系2023-08-14 1795
-
为你的AI芯片从FPGA走向ASIC?2023-11-23 205
全部0条评论

快来发表一下你的评论吧 !
