

基于FPGA处理器的C编译指令
FPGA/ASIC技术
描述
通常基于传统处理器的C是串行执行,本文介绍Xilinx Vivado-HLS基于FPGA与传统处理器对C编译比较,差别。对传统软件工程师看来C是串行执行,本文将有助于软件工程师理解Vviado-HLS基于Xilinx FPGA对C的解析,综合原理。
1. Vivado-HLS FPGA并行与处理器架构
与处理器架构相比,FPGA结构具有更高的并行。Vivado-HLS对软件C程序编译时与处理器编译是不一样的执行机制。
2. Vivado-HLS FPGA与处理器程序指令执行
对于处理器, 程序执行以顺序指令, 如GCC,它将C/C++算法转换成assembly语言。
如
c = a + b
处理器将其转换成assembly代码如下:
LD a, $R1
LD b, $R2
ADD $R1, $R2, $R3
ST $R3 c
由此可见,对处理器简单的加法运算,都将需多个assembly指令集来完成。如下图所示分别是基于处理器的单一,及多指令执行单元。
上述c = a + b运算处理latency受限于数据a,b所存放的位置,如DDR,还是hard drive。
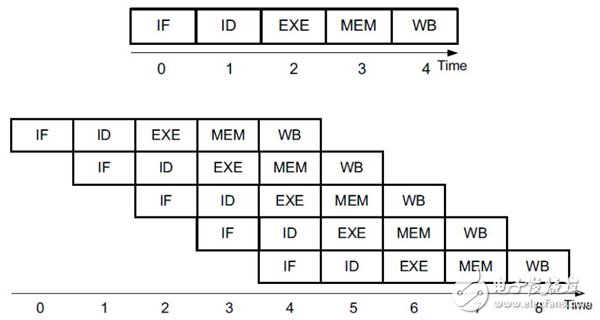
Vivado-HLS编译器是被用于将软件C/C++转换成RTL,由于FPGA是完全并行处理,转换不受限于指令的cache及内存空间。
如上例c = a + b, Vivado-HLS将其综合成一些LUT来实现。
Vivado-HLS面向FPGA编译指令处理如下图所示,为完全并行。

下面看多个运算的例子:
A[i] = B[i] * C[i];
D[i] = B[i] * E[i];
F[i] = A[i] * D[i];
对处理器将使用如下纯串行执行。因为数组 A, B, C, D, E, F被存在一个单一存储空间,所以每次只能操作一个数据。
然而,对Vivao-HLS检测到这些存储并且对每个数组生成了独立的memory bank, 从而使得对数组B, C的操作可以同时并行进行。
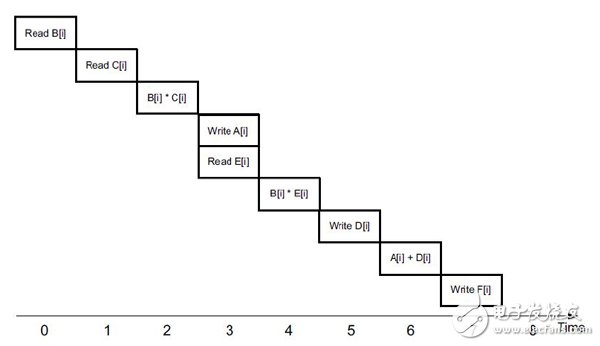
对Vivado-HLS FPGA将默认使用如下方式执行
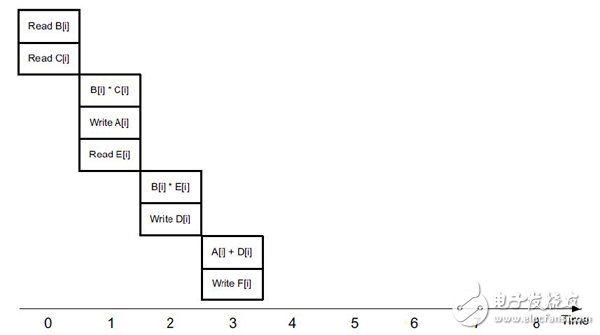
下面再看对loop运算。
for (i=0; i<10; i++)
{
A = A + B[i] * C[i];
}
处理器对loop iteration的scheduling如下图所示。 串行实现,第一次loop iteration结束才开始第二次loop iteration。
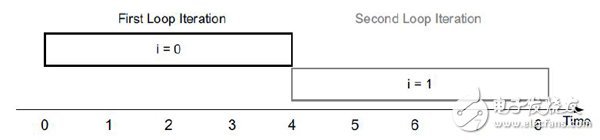
Vivado-HLS基于FPGA对loop iteration的scheduling如下图所示。 不受限于第一次loop iteration结束才开始第二次loop iteration。从而可以并行实现II=1。在第一次loop的运算结束后就可以开始第二次loop的运算。
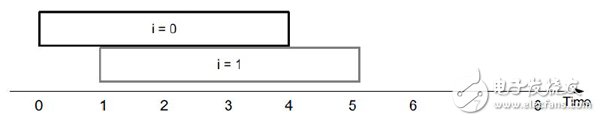
当然有时为了更小的FPGA资源,Vivado-HLS也可以综合成与处理器类似的串行实现结构。总结如下表所示。

-
FPGA协处理器的优势2011-09-29 0
-
FPGA实现高速FFT处理器的设计2012-08-12 0
-
【FPGA干货分享六】基于FPGA协处理器的算法加速的实现2015-02-02 0
-
μC/OS-II操作系统在各种处理器上的移植2017-08-14 0
-
Hexagon处理器的指令和指令包的二进制编码2018-09-20 0
-
s3c2410协处理器指令的意思是什么?2019-02-25 0
-
什么是DSP,DSP处理器有什么特点?2020-09-04 0
-
求一种基于FPGA的微处理器的IP的设计方法2021-04-29 0
-
ARM微处理器指令系统实验2021-12-14 0
-
ARM微处理器的指令系统2021-12-20 0
-
ARM微处理器指令系统资料介绍2022-04-26 0
-
微处理器指令集设计2008-10-29 670
-
协处理器的三大类数据传送指令2018-01-09 2002
-
嵌入式C预处理器的基本概念和常用指令2023-04-13 678
-
处理器架构与指令集2023-04-26 2997
全部0条评论

快来发表一下你的评论吧 !
