

基于FPGA的16位堆栈处理器的设计
FPGA/ASIC技术
描述
摘 要:设计了一款面向嵌入式控制领域的16位堆栈处理器,该处理器包含两个堆栈:执行数学表达式的数据堆栈和支持子程序调用的返回堆栈,其指令集含35条堆栈指令.详细给出了该堆栈处理器的体系结构及设计方法;不仅采用简单有效的指令编码方式缩小了代码体积,同时给出了单周期操作多个堆栈元素的解决方法.该处理器采用FPGA实现,在XC5VLX110T芯片上的运行时钟频率最高达到146.7MHz。最后给出了设计的软件仿真与硬件综合结果。
1 引言
Forth是由Charles H.Moore在1960年代发明的一种基于堆栈、可扩展、具有简单哲学思想的计算机编程语言[1],特别适合于软件代码在千行数量级的中规模嵌入式系统中应用,并且已经被国外广泛应用于天文、军事、航空航天、工业自动化、图形、仪器仪表等领域。
Forth语言既可以被看作汇编语言又可以被看作高级语言,它与传统语言最大的区别在于它是基于堆栈的和可扩展性。Forth语言本质上定义了一种双堆栈体系结构。这种体系结构的主要思想是基于两个不同的堆栈,一个是用来执行数学表达式的数据堆栈,另一个是用来支持子程序调用的,即保存子程序返回地址的返回堆栈,指令的所有操作都是针对这两个堆栈的一个或者几个栈顶元素[2]。
Forth语言定义的这种双堆栈体系结构清晰明了,复杂度低,并且其主要面向的是嵌入式控制领域。在这种背景下,结合FPGA的灵活性,本文设计并实现了一种基于FPGA 的16位堆栈处理器,相比基于RISC体系结构的嵌入式处理器,具有以下几点优势:
① 很大程度上避免了处理器进行上下文切换带来的开销,因为处理器的运行不依赖于大量的通用寄存器;
② 处理器的寻址方式非常简单,几乎所有指令都是0操作数指令.这样不仅系统复杂度显著降低,速度得到提升,代码体积也大大减小;
③ 处理器在运行具有深度嵌套特征的程序时有更加明显的优势,因为具有专门的硬件堆栈来执行子程序调用与返回。
2 设计与实现
2.1 堆栈处理器体系结构概览
处理器的结构如图1所示,为了能够清晰地展示其结构,部分信号并未显示或直接连接.处理器包含的主要模块见表1。
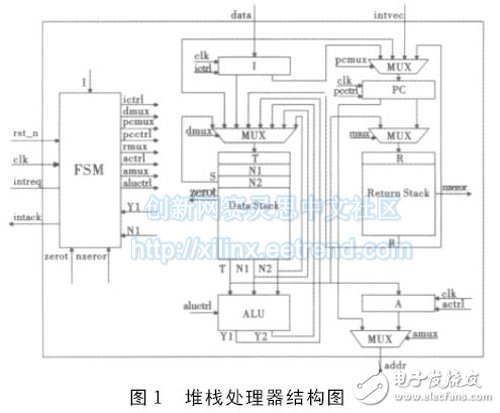

需要说明的是,表中的数据堆栈由栈顶寄存器T、次栈顶寄存器N1、第三栈顶寄存器N2以及深度为32的堆栈存储器构成;返回堆栈由栈顶寄存器R以及深度为32的堆栈存储器构成。
2.2 指令集
2.2.1 指令集设计
处理器实现了四种类型共35条指令,具体如下表2所示。

表中大部分指令遵从了Forth语言的原语命名规则与功能.比如,其中的‘>r’表示将数据堆栈栈顶寄存器T的内容弹出到返回堆栈栈顶寄存器R,‘r>’则表示相反的功能.另外,‘@’表示从存储器读数据到数据堆栈,而‘!’表示将数据堆栈的内容存储到存储器中.下面分别简述各种类型指令的功能。
① 堆栈操作:主要是对数据堆栈或者返回堆栈的一个或者多个栈顶元素的操作.例如,swap指令交换T与N1的内容;one和zero指令分别将T的所有bit位置1和0;drop指令弹出T中内容并抛弃.所有的堆栈操作类型指令都在一个周期内完成。
② 数学运算:数学运算指令的操作数均为T和N1中内容.逻辑运算指令包括or、xor和and;移位指令包括asr、lsr和lsl;1plus和1min分别将数据堆栈栈顶元素加1和减1.所有数学运算类型指令都在一个周期内完成。
为了节省硬件资源,堆栈处理器没有实现硬件支持的乘法器[3]和除法器[4],因此没有直接的乘法和除法指令,取而代之的是mpp和shld指令.这两条指令分别完成了乘法器和除法器在一个时钟周期中完成的操作.mpp指令执行时需要同时操作寄存器T、N1和N2.N1与N2中分别存放初始的乘数与被乘数,T的初始值为0;最终乘积结果的高低16位分别存放于T与N1.mpp指令的执行分成两步.第一步判断N1最低位是否为1:如果为1,将N2与T中内容相加;否则不做操作.第二步将T做高位、N1做低位,对其内容进行逻辑右移.这样连续执行完16条mpp指令后,T与N1中存放的分别为乘积的高低16位.这16条mpp指令再配合其他几条指令便可以完成正常的乘法操作,完整的乘法操作耗费19个时钟周期.除法的实现与乘法类似,完整的除法操作耗费21个时钟周期.下面给出了乘法操作的程序示例,其详细解释将在3.1节的仿真分析中给出:
litc 0 ∥将0压入堆栈
mpp ∥第1条mpp指令
…
mpp ∥第16条mpp指令
rot ∥乘法结束后,清理掉
drop ∥位于N2的被乘数
③ 访存:堆栈处理器支持按字节和按字两种访存方式.指令集中的litc、c@和c!指令为字节访存指令;而lit、@和!为按字访存指令.这里简要说明按字访存指令的功能,按字节访存与之类似.lit将一个字常量压入数据堆栈;@将T的内容弹出送入地址寄存器A,按A中地址访存取得数据后压入数据堆栈;!指令将T中的内容弹出送入地址寄存器A,再将当前栈顶T的数据弹出存入A 中地址.除litc指令的其他指令需要两个周期执行,litc指令在设计时被优化为不需要访存,因此只需要一个周期执行。
④ 程序转移:call为子程序调用指令,它将当前PC寄存器值压入返回堆栈,同时将子程序地址送入PC寄存器;ret为子程序返回指令,它将返回堆栈的栈顶值弹出,送入PC寄存器;jmp为无条件跳转指令;jz和jc为有条件跳转指令,跳转条件分别是数据堆栈栈顶T的内容是否为0和ALU进位标志位是否为0;drjne将返回堆栈栈顶R的内容减1,然后判断R中内容是否为0,如果不为0则跳转.除call与ret以外的其他指令都需要先访存取得16位跳转地址,然后压入堆栈,因此需要两个周期执行;ret与call指令只需要一个周期执行。
2.2.2 指令集编码优化
存储器是嵌入式控制系统中的一种稀缺资源,因此在设计堆栈处理器时,采用了一种简单但是有效的编码方式进行指令编码,不仅大大减小了代码体积,还在一定程度上可以降低系统的复杂度,提高系统效率。
在堆栈处理器上执行的程序一般都通过大量子程序调用进行模块化设计以减小代码尺寸,这样才能充分利用硬件支持的返回堆栈.因此,在典型的堆栈处理器程序中25%的时间花费在子程序调用上[5],这就要求在实现堆栈处理器时必须高效地实现call指令.一方面,如果call指令占用的bit位较少,便能减小代码体积;另外一方面,如果call指令的执行能在一个周期完成,将大大加快程序的执行速度.因此指令集采用了两种不同的编码方式实现。
对于除call以外的其他指令,每条指令占8位且最高位均为0.处理器每次访存取出的16位数据中,高低8位各为一条指令.采用这种设计方案后,一方面,每次访存可以取出两条指令.这在处理器和存储器之间形成了一个处理器速度两倍于存储器速度的缓冲,可以在一定程度上避免Cache的引入,降低嵌入式系统的复杂度;另一方面,每条指令占用8位而不是16位可以大大减小代码体积。
all指令采用了另外一种实现方式,如果访存取出的16位数据中最高位为1,那么这16位不再被解释为两条指令,最高位被解释为call指令,剩下的15位经逻辑左移1位后作为子程序地址.相对于采用与其他类型指令相同的8位实现方式,这种实现方式使得call指令仅占1位,可以进一步减小代码体积。
另外,call指令执行时的子程序地址不需要通过访存取得,因此其执行将只耗费一个周期.当然,这样的方案会让call指令只能调用位于偶地址的子程序,但是好的设计来源于适当的折中,这种损失相对于获得的效率和性能提升是值得的。
2.3 控制模块
控制器本质上是如图2所示的一个五状态的有限状态机。InstrF为其初始状态,即取指令状态。Slot0和Slot1为执行状态,Slot0_M 和Slot1_M 为访存状态。Slot0与Slot0_M 对应于低8位指令地执行与访存,Slot1与Slot1_M 对应于高8位指令地执行与访存。
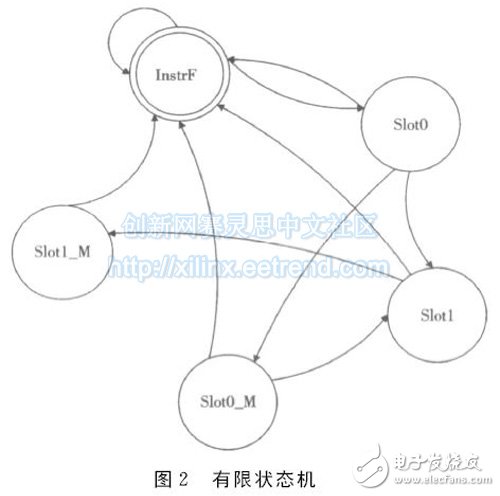
处理器在InstrF状态访存取出16位数据后进入Slot0状态,先判断数据的最高位是否为1:若为1,则最高位被解释为call指令,低15位经逻辑左移1位后作为子程序地址,执行子程序调用后下一状态进入InstrF;若为0,则执行低8位指令.如果低8位指令为单周期指令,下一状态进入Slot1执行高8位指令;如果低8位指令为双周期指令,下一状态进入Slot0_M 进行访存,访存结束后下一状态进入Slot1执行高8位指令。
处理器在进入Slot1状态后,执行高8指令.如果高8位指令为单周期指令,下一状态进入InstrF继续取指令;如果高8位为双周期指令,下一状态进入Slot1_M 访存,访存结束后下一状态进入InstrF继续取指令。
在InstrF状态可以响应外部中断.如果此时检测到中断请求信号intreq为高电平,则给出中断响应信号intack,并且将中断向量intvec送入PC,下一状态依然为InstrF状态。
2.4 堆栈实现
本文设计的堆栈处理器包含两个硬件支持的堆栈:数据堆栈和返回堆栈.由于所有指令都是对这两个堆栈的操作,因此堆栈的实现方式对于堆栈处理器的效率和性能是至关重要的.堆栈的实现不仅要最大程度上避免溢出,还要保证在访问时能够非常高效。
2.4.1 堆栈溢出问题
关于硬件堆栈溢出问题存在多种解决方法,主要有:请求式单元素堆栈管理器、页式堆栈管理以及
联合Cache等.其实Charles H.Moore曾经做过统计,在典型的堆栈程序执行过程中,当堆栈深度超过32时,几乎所有的程序都不会发生堆栈溢出问题。因此堆栈处理器WISC和EP32直接将堆栈深度设置为256,以求完全避免堆栈溢出问题。
相对于采用其他硬件方式来避免溢出问题,直接增加堆栈深度更加简单有效,因此本文论述的处理器直接将堆栈存储器深度设置为32(不包括栈顶寄存器在内).这对于一般的应用已经足够,由于是采用FPGA实现,在需要的情况下可以很方便地将堆栈深度增加。
2.4.2 指令的单周期堆栈操作
指令集中的很多指令,如swap和rot指令,需要同时操作堆栈的两个甚至三个栈顶元素.如果采用普通的堆栈存储器,想同时访问栈顶的多个元素,就需要访问堆栈多次,这样那些需要操作多个栈顶元素的指令在执行时需要耗费多个周期.这对于堆栈处理器将是极大的性能损失。
因此,为了保证所有指令的堆栈操作都能够在单周期内完成,在堆栈设计上采用了图1中所示的栈顶寄存器加堆栈存储器的方式.对于数据堆栈,由于在最多的情况下(rot指令的执行)需要同时访问栈顶的三个元素,因此设置了三个栈顶寄存器T、N1和N2.这样数据堆栈的真正栈顶元素就是T,而不是堆栈存储器的栈顶元素.返回堆栈的设计与此类似,设置了一个栈顶寄存器R。
3 仿真与综合
本文设计采用Verilog进行RTL级描述,仿真软件为ModelSimSE6.5C,综合软件为SynplifyPro9.6.1,目标芯片为Xilinx公司的Virtex-5 XC5VLX110T。
3.1 仿真分析
图3中给出了2.2.1节中的乘法程序的仿真波形图,图中state与nextstate信号给出了有限状态机的状态转移情况;instr_exec表示当前正在执行的指令;I与PC则分别为指令寄存器与程序计数器;T、N1和N2为数据堆栈的三个栈顶寄存器;result表示ALU的运算结果。

从图中可以看出,在70~110ns,执行了两条lit指令(指令编码为40H),这两条指令将乘数与被乘数003H与0011H压入数据堆栈.在这之后开始执行2.2.1节中给出的乘法运算程序.在120~130ns,执行了一条litc(指令编码为50H)指令,将00H扩展为0000H 压入数据堆栈.此时,可以查看堆栈寄存器T、N1和N2里的内容分别为0000H、0011H和0003H.在140~370ns期间连续执行了16条mpp完成在mpp指令操作后的一些堆栈清理操作.最后,在第400ns时查看数据堆栈的栈顶寄存器T与N1,发现内容分别为0000H 与0033H,其中0000H 为乘法结果的高16位,而0033H 则为低16位,与预期结果一致。
3.2 综合分析
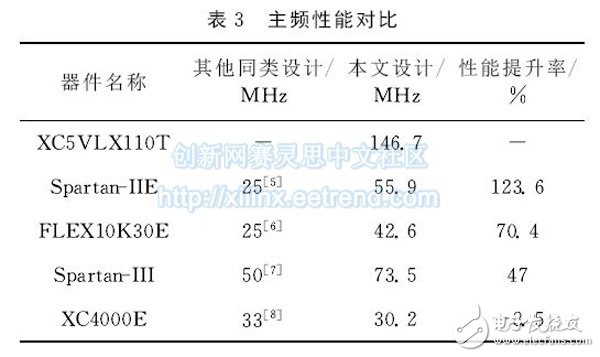
使用Xilinx公司的XC5VLX110T作为目标芯片时,片上资源利用率不超过3%,堆栈处理器的最高频率可以达到146.7MHz.表3中给出了本设计在不同芯片上与不同文献中同类设计进行的主频性能对比.从表中数据可以看出,本设计在主频性能上与前三种同类设计相比有较明显的提升.值得注意的是,与文献[8]中的MSL16处理器相比较而言,本文处理器主频略有下降,这是因为MSL16处理器在设计中应用了两级流水线技术.本文则侧重于运用较简单的设计、较少的硬件资源以获得较高的性能:一方面,流水线技术在堆栈处理器中的应用无疑会大幅增加堆栈处理器的复杂度,这与本文的设计初衷不相符;另一方面,从性能提升率上看,流水线技术的应用所带来的频率增加并非异常显著。
4 结束语
本文以双堆栈体系结构为基础,设计了一种不同于RISC体系结构的嵌入式堆栈处理器.该处理器结构紧凑,系统复杂度低,代码体积小.在Xilinx公司的XUPV5-LX110T开发板上实现后,其主频达到了146.7MHz,片内资源使用率不超过3%.仿真与综合结果证明了设计的正确性,与同类设计相比较,主频性能有较为明显的提升.堆栈处理器较高的主频与较低的资源使用率为后期以该处理器为核心构建一个SoPC提供了基础。
-
你怎么看8位、16位、32位及64位嵌入式处理器?2019-07-05 0
-
STM32堆栈增长方向问题2020-04-20 0
-
哪位大神可以详细介绍ATtiny13堆栈指针?2020-11-10 0
-
C语言单片机栈、堆、堆栈的区别是什么?2021-10-13 0
-
怎样去设置STM32堆栈空间的大小呢2021-10-21 0
-
STM32堆栈的地址是怎么得出来的?2021-11-26 0
-
STM32堆栈区划分2022-01-20 0
-
atmega128堆栈的特点是什么?2022-01-24 0
-
16位和32位微处理器的相关资料推荐2022-01-25 0
-
STM32堆栈溢出检测相关资料下载2022-02-21 0
-
怎样去解决STM32堆栈空间不足的问题呢2022-02-21 0
-
软件中的堆栈,堆和栈是不同的东西吗?2023-10-10 0
全部0条评论

快来发表一下你的评论吧 !
