

解析编译原理
编程语言及工具
描述
学过编译原理课程的同学应该有体会,各种文法、各种词法语法分析算法,非常消磨人的耐心和兴致;中间代码生成和优化,其实在很多应用场景下并不重要(当然这一块对于“编译原理”很重要);语义分析要处理很多很多细节,特别对于比较复杂的语言;最后的指令生成,可能需要读各种手册,也比较枯燥。
我觉得对普通的程序员来说,编译原理里面有实际用途的,是parser和codegen,但是因为这两个领域,到了2016年都没什么好研究的了,而且也被搞PLT的人所鄙视,所以你们看到的那些经典的教材,都没有好好讲。
一、 编译程序
1、 编译器是一种翻译程序,它用于将源语言(即用某种程序设计语言写成的)程序翻译为目标语言(即用二进制数表示的伪机器代码写成的)程序。后者在windows操作系统平台下,其文件的扩展名通常为.obj。该文件通常还要经过进一步的连接,生成可执行文件(机器代码写成的程序,文件扩展名为.exe)。通常有两种方式进行这种翻译,一种是编译,另一种是解释。后者并不生成可执行文件,只是翻译一条语句、执行一条语句。这两种方式相编译比解释运行的速度要快得多。
2、 编译过程的5个阶段:词法分析;语法分析;语义分析与中间代码产生;优化;目标代码生成。
3、 在这五个阶段中,词法分析的任务是识别源程序中的单词是否有误,编译程序中实现这种功能的部分一般称为词法分析器。在编译器中,词法分析器通常仅作为语法分析程序的一个子程序以便在它需要单词符号时调用。在这一编译阶段中发现的源程序错误,称为词法错误。
4、 语法分析阶段的目的是识别出源程序的语法结构(即语句或句子)是否错误,所以有时又常为句子分析。编译程序中负责这一功能的程序称为语法分析器或语法分析程序。在这一阶段中发现的错误称为语法错误。
5、 C语言的(源)程序必须经过编译才能生成目标代码,再经过链接才能运行。PASCAL语言、FORTRAN语言的源程序也要经过这样的过程。通常将C、PASCAL、FORTRAN这样的语言统称为高级语言。而将最终的可执行程序称为机器语言程序。
6、 在编译C语言程序的过程中,发现源程序中的一个标识符过长,超过了编译程序允许的范围,这个错误应在词法分析阶段发现,这种错误通常被称作词法错误。
6.1. 词法分析器的任务是以词法规则为依据对输入的源程序进行单词及其属性的识别,识别出一个个单词符号。
6.2. 词法分析的输入是源程序,输出是一个个单词的特殊符号,称为Token(标记或符号)。
6.3.语法分析器的类型有:自下而上、自上而下。常用的语法分析器有:递归下降分析方法是一种自上而下分析方法, 算符优先分析法属于自下而上分析方法,LR分析法属于自下而上分析方法等等。
6.4.通常用正规文法或正规式来描述程序设计语言的词法规则,而使用上下文无关文法来描述程序设计语言的语法规则。
6.5.语法分析阶段中,处理的输入数据是来自词法分析阶段的单词符号。它们是词法分析阶段的终结符。
7、 编译程序总框
8、 在计算机发展的早期阶段,内存较小的不能一次完成程序的编译。这时通常将编译过程分成若干遍来完成。每一遍完成一部分功能,称为多遍编译。
与采用高级程序设计语言写的词法分析器相比,用汇编语言写的词法分析通常分析速度要快些。
二。 词法与语法
1、 程序语言主要由语法和语义两个方面来定义。
2、 任何语言的程序都可看成是某字符集上的一个长字符串。
3、 语言的语法:是指这样的一组规则(即产生式),用它可以生成和产生一个良定的程序。这些规则的一部分称为词法规则,另一部分称为语法规则。
4、 词法规则:单词符号的形成规则;语法规则:语法单位(句子)的形成规则。语义规则:定义程序句子的意义。
5、 一个程序语言的基本功能是描述数据和对数据的运算。
6、 高级语言的分类:强制式语言;应用式语言;基于规则的语言;面向对象的语言。
7、 一个语言的字母表为{a,b},则字符串ab的前缀有a、ε,其中ε不是真前缀。
8、 字符串的连接运算一般不满足交换率。
9、 文法G是一个四元组,或者说由四个元素构成,即非终结符集合VN、非终结符号集合VT 、开始符号S、产生式集合P,它可以形式化地表示成G =(VN,VT,S,P)。
按照文法的定义,这4个元素中终结符号集合是这个文法所规定的语言的字母表,产生式集合代表文法所规定的语言语法实体的集合。对上下文无关文法,通常我们只需要写出这个文法的产生式集合就可以确定这个文法的其他所有元素。其中,第一条产生式的左部符号为开始符号,而所有产生式的左部符号构成的集合就是该文法的非终结符集合。
文法的例子:
设文法G=(VN,VT, S,P),其中P为产生式集合,它的每个元素的形式为产生式。
10、如果文法G的一个句子存在两棵不同的最左语法分析树,则这个文法是无二义的。
11、如果文法G的一个句子存在两棵不同的最右语法分析树,则这个文法是无二义的。
12、如果文法G的一个句子存在两棵不同的语法分析树,则这个文法是无法判断是否是二义的。
13、A为非终结符,如果文法存在产生式 ,则称 可以推导出 ;反之,称 可归约为 。
14、乔姆斯基(Chomsky)将文法分为四类,即0型文法、1文法、2文法、3文法。
按照乔姆斯基对方法的分类,上下文无关文法是2型文法,2型文法的描述能力最强,3型文法又称为正规文法。
15、产生式S→Sa | a产生的语言为L(G) = {an | n ≥ 1}。
16、确定有限自动机DFA是非确定有限自动机NFA的特例;对任一非确定有限自动机能找到一个与之等价的确定有限自动机。
17、DFA和NFA的主要区别有三点:一、DFA初态唯一,NFA初态不唯一;二、DFA弧标记为Σ上的元素,NFA弧标记为Σ*上的元素;三、DFA的函数为单射,NFA函数不是单射。
18、有限自动机中两个状态S1和S2是等价的是指,无论是从S1还是S2出发,停于终态时,所识别的输入字的集合相同。
19、自下而上的分析方法,是一个不断归约的过程。
20、递归下降分析器:当一个文法满足LL(1)条件时,我们就可以为它构造一个不带回溯的自上而下分析程序。这个分析程序是由一组递归过程组成的,每个过程对应文法的一个非终结符。
这个产生式中含有的左递归是直接左递归。递归下降分析法中,必须要消除所有的左递归。递归下降分析法中的试探分析法之所以要不断用一个产生式的多个候选式进行逐个试探,最根本的原因是这些候选式有公共左因子。
21、算符优先分析法是一种自下而上的分析方法,它适合分析各种程序设计语中的表达式,并宜于手工实现。目前最广泛的无回溯的“移进—归约”方法是自下而上分析方法。
22、在表驱动预测分析器中,
1)读入一个终结符a,若该终结符与栈项的终结符相同,并且不是结束标志$,则此时栈顶符号出栈;
2)若此时栈项符号是终结符并且是,并且读入的终结符不是,说明源程序有语法错误;
3)若此时栈顶符号为,并且读入的终结符也是,则分析成功。
23、算符优先分析方法不存在使用形如 这样的产生式进行的归约,即只要求终结符的位置与产生式结构一致,从而使得分析速度比LR分析法更快。
24、LR(0)的例子:
产生式E→ E+T对应的LR(0)项目中,待归约的项目是E→ E+∙T,移进项目是E→ E∙+T,还有两个项目为E→ ∙E+T和E→ E+T∙。
当一个LR(0)项目集中含有两个归约项目时,称这个项目集中含有归约-归约冲突。
25、LL(1)文法的产生式中一定没有公共左因子,即LL(1)文法中一定没有左递归。为了避免回溯,在LL(1)文法的预测分析表中,一个表项中至多只有一个产生式。
预测分析方法(即LL(1)方法),由一个栈,一个总控程序和一个预测分析表组成。其中构造出预测分析表是该分析方法的关键。
26、LR(0)与SLR(1)两种分析方法相比,SLR(1)的能力更强。
27、静态语义检查一般包括以下四个部分,即类型检查、控制流检查、名字匹配检查、一致性检查。
C语言编译过程中下述常见的错误都属于检查的范围:
a) 将字符型指针的值赋给结构体类型的指针变量:类型检查。
b)switch语句中,有两个case语句中出现了相同的常量:一致性检查。
c)break语句在既不是循环体内、又不是break语句出现的地方出现:控制流检查。
d)goto语句中的标号在程序的函数中没有找到:一致性检查。
e)同一个枚举常量出现在两个枚举类型的定义当中:相关名字检查。
28、循环优化中代码外提是指对循环中的有些代码,如果它产生的结果在循环过程中是不变的,就把它提到循环体外来;而强度削弱是指把程序中执行时间较长的运算替换为执行时间较短的运算。
解析编译原理主要过程
第一个编译器由机器语言开发 然后就有了后来的各种语言写出来的编译器
1 编译过程包括如下图所示:。
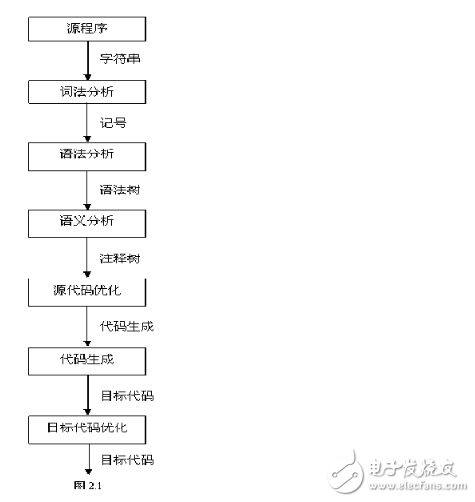
2 词法分析作用:找出单词 。如int a=b+c; 结果为: int,a,=,b,+,c和;
3语法分析作用:找出表达式,程序段,语句等。如int a=b=c;的语法分析结果为int a=b+c这条语句。
4语义分析作用:查看类型是否匹配等。
5注意点:词法分析器实现步骤:正规式-》NFA-》简化后的DFA-》对应程序;语法分析要用到语法树;语义分析要用到语法制导。
编译原理一般分为词法分析,语法分析,语义分析和代码优化及目标代码生成等一系列过程。下面我们结合来了解一下:
本程序可以同时在BC和Visual C++下运行。我测试过了的。下面先将代码贴给大家。其中如果你只想先了解词法分析部分,你可以将其余的注释就可以。我建议大家学习时一步一步来,从词法分析学,然后学语法分析。其他的就类似了。
如果你在DOS下运行,由于使用了汉字,请将其自行换成英文方便您的识别。
程序中的解释就是编译的基本原理。如果还不清楚建议大家看孙悦红的编译原理及实现清华的。
#include 《stdio.h》
#include 《ctype.h》
#include 《conio.h》
#include “stdio.h”
//下面定义保留,为简化程序,使用字符指针数组保存所有保留字。
//如果想增加保留字,可继续添加,并修改保留字数目
#define keywordSum 8
#define maxvartablep 500//定义符号表的容量
char *keyword[keywordSum]={ “if”,“else”,“for”,“while”,“do”,“int”,“read”,“write”};
//下面定义纯单分界符,如需要可添加
char singleword[50]=“+-*(){};,:”;
//下面定义双分界符的首字符
char doubleword[10]=“》《=!”;
//函数调用
int TESTparse();
int program();
int compound_stat();
int statement();
int expression_stat();
int expression();
int bool_expr();
int additive_expr();
int term();
int factor();
int if_stat();
int while_stat();
int for_stat();
int write_stat();
int read_stat();
int declaration_stat();
int declaration_list();
int statement_list();
int compound_stat();
int name_def(char *name);
char token[20],token1[40];//token保存单词符号,token1保存单词值
char Scanout[300],Codeout[300]; //保存词法分析输出文件名
FILE *fp,*fout; //用于指向输入输出文件的指针
struct{//定义符号表结构
char name[8];
int address;
}vartable[maxvartablep];//改符号表最多容纳maxvartablep个记录
int vartablep=0,labelp=0,datap=0;
int TESTscan();
char Scanin[300],Errorfile[300]; //用于接收输入输出以及错误文件名
FILE *fin; //用于指向输入输出文件的指针
int TESTscan()//词法分析函数
{
char ch,token[40]; //ch为每次读入的字符,token用于保存识别出的单词
int es=0,j,n; //es错误代码,0表示没有错误。j,n为临时变量,控制组合单词时的下标等
printf(“请输入源程序文件名(包括路径):”);
scanf(“%s”,Scanin);
printf(“请输入词法分析输出文件名(包括路径):”);
scanf(“%s”,Scanout);
if ((fin=fopen(Scanin,“r”))==NULL) //判断输入文件名是否正确
{
printf(“/n打开词法分析输入文件出错!/n”);
return(1);//输入文件出错返回错误代码1
}
if ((fout=fopen(Scanout,“w”))==NULL) //判断输出文件名是否正确
{
printf(“/n创建词法分析输出文件出错!/n”);
return(2); //输出文件出错返回错误代码2
}
ch=getc(fin);
while(ch!=EOF)
{
while (ch==‘ ’||ch==‘/n’||ch==‘/t’) ch=getc(fin);
if (ch==EOF) break;
if (isalpha(ch)) //如果是字母,则进行标识符处理
{
token[0]=ch; j=1;
ch=getc(fin);
while(isalnum(ch)) //如果是字母数字则组合标识符;如果不是则标识符组合结束
{
token[j++]=ch; //组合的标识符保存在token中
ch=getc(fin); //读下一个字符
}
token[j]=‘/0’; //标识符组合结束
//查保留字
n=0;
while ((n《keywordSum) && strcmp(token,keyword[n])) n++;
if (n》=keywordSum) //不是保留字,输出标识符
fprintf(fout,“%s/t%s/n”,“ID”,token); //输出标识符符号
else//是保留字,输出保留字
fprintf(fout,“%s/t%s/n”,token,token); //输出保留字符号
} else if (isdigit(ch))//数字处理
{
token[0]=ch; j=1;
ch=getc(fin); //读下一个字符
while (isdigit(ch)) //如果是数字则组合整数;如果不是则整数组合结束
{
token[j++]=ch; //组合整数保存在token中
ch=getc(fin); //读下一个字符
}
token[j]=‘/0’; //整数组合结束
fprintf(fout,“%s/t%s/n”,“NUM”,token); //输出整数符号
} else if (strchr(singleword,ch)》0) //单分符处理
{
token[0]=ch; token[1]=‘/0’;
ch=getc(fin);//读下一个符号以便识别下一个单词
fprintf(fout,“%s/t%s/n”,token,token); //输出单分界符符号
}else if (strchr(doubleword,ch)》0) //双分界符处理
{
token[0]=ch;
ch=getc(fin); //读下一个字符判断是否为双分界符
if (ch==‘=’) //如果是=,组合双分界符
{
token[1]=ch;token[2]=‘/0’; //组合双分界符结束
ch=getc(fin); //读下一个符号以便识别下一个单词
} else//不是=则为单分界符
token[1]=‘/0’;
fprintf(fout,“%s/t%s/n”,token,token); //输出单或双分界符符号
} else if (ch==‘/’) //注释处理
{
ch=getc(fin); //读下一个字符
if (ch==‘*’) //如果是*,则开始处理注释
{ char ch1;
ch1=getc(fin); //读下一个字符
do
{ ch=ch1;ch1=getc(fin);} //删除注释
while ((ch!=‘*’ || ch1!=‘/’)&&ch1!=EOF); //直到遇到注释结束符*/或文件尾
ch=getc(fin);//读下一个符号以便识别下一个单词
} else //不是*则处理单分界符/
{
token[0]=‘/’; token[1]=‘/0’;
fprintf(fout,“%s/t%s/n”,token,token); //输出单分界符/
}
} else//错误处理
{
token[0]=ch;token[1]=‘/0’;
ch=getc(fin); //读下一个符号以便识别下一个单词
es=3; //设置错误代码
fprintf(fout,“%s/t%s/n”,“ERROR”,token); //输出错误符号
}
}
fclose(fin);//关闭输入输出文件
fclose(fout);
return(es); //返回主程序
}
//语法、语义分析及代码生成
//插入符号表动作@name-def↓n, t的程序如下:
int name_def(char *name)
{
int i,es=0;
if (vartablep》=maxvartablep) return(21);
for(i=vartablep-1;i==0;i--)//查符号表
{
if (strcmp(vartable[i].name,name)==0)
{
es=22;//22表示变量重复声明
break;
}
}
if (es》0) return(es);
strcpy(vartable[vartablep].name,name);
vartable[vartablep].address=datap;
datap++;//分配一个单元,数据区指针加1
vartablep++;
return(es);
}
//查询符号表返回地址
int lookup(char *name,int *paddress)
{
int i,es=0;
for(i=0;i《vartablep;i++)
{
if (strcmp(vartable[i].name,name)==0)
{
*paddress=vartable[i].address;
return(es);
}
}
es=23;//变量没有声明
return(es);
}
//语法、语义分析及代码生成程序
int TESTparse()
{
int es=0;
if((fp=fopen(Scanout,“r”))==NULL)
{
printf(“/n打开%s错误!/n”,Scanout);
es=10;
return(es);
}
printf(“请输入目标文件名(包括路径):”);
scanf(“%s”,Codeout);
if((fout=fopen(Codeout,“w”))==NULL)
{
printf(“/n创建%s错误!/n”,Codeout);
es=10;
return(es);
}
if (es==0) es=program();
printf(“==语法、语义分析及代码生成程序结果==/n”);
switch(es)
{
case 0: printf(“语法、语义分析成功并抽象机汇编生成代码!/n”);break;
case 10: printf(“打开文件 %s失败!/n”,Scanout);break;
case 1: printf(“缺少{!/n”);break;
case 2: printf(“缺少}!/n”);break;
case 3: printf(“缺少标识符!/n”);break;
case 4: printf(“少分号!/n”);break;
case 5: printf(“缺少(!/n”);break;
case 6: printf(“缺少)!/n”);break;
case 7: printf(“缺少操作数!/n”);break;
case 21: printf(“符号表溢出!/n”);break;
case 22: printf(“变量重复定义!/n”);break;
case 23: printf(“变量未声明!/n”);break;
}
fclose(fp);
fclose(fout);
return(es);
}
//program::={《declaration_list》《statement_list》}
int program()
{
int es=0,i;
fscanf(fp,“%s %s/n”,token,token1);
printf(“%s %s/n”,token,token1);
if(strcmp(token,“{”))//判断是否‘{’
{
es=1;
return(es);
}
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=declaration_list();
if (es》0) return(es);
printf(“ 符号表/n”);
printf(“ 名字 地址/n”);
for(i=0;i《vartablep;i++)
printf(“ %s %d/n”,vartable[i].name,vartable[i].address);
es=statement_list();
if (es》0) return(es);
if(strcmp(token,“}”))//判断是否‘}’
{
es=2;
return(es);
}
fprintf(fout,“ STOP/n”);//产生停止指令
return(es);
}
//《declaration_list》::=
//《declaration_list》《declaration_stat》|《declaration_stat》
//改成《declaration_list》::={《declaration_stat》}
int declaration_list()
{
int es=0;
while (strcmp(token,“int”)==0)
{
es=declaration_stat();
if (es》0) return(es);
}
return(es);
}
//《declaration_stat》↓vartablep,datap,codep -》int ID↑n@name-def↓n,t;
int declaration_stat()
{
int es=0;
fscanf(fp,“%s %s/n”,&token,&token1);printf(“%s %s/n”,token,token1);
if (strcmp(token,“ID”)) return(es=3); //不是标识符
es=name_def(token1);//插入符号表
if (es》0) return(es);
fscanf(fp,“%s %s/n”,&token,&token1);printf(“%s %s/n”,token,token1);
if (strcmp(token,“;”) ) return(es=4);
fscanf(fp,“%s %s/n”,&token,&token1);printf(“%s %s/n”,token,token1);
return(es);
}
//《statement_list》::=《statement_list》《statement》|《statement》
//改成《statement_list》::={《statement》}
int statement_list()
{
int es=0;
while (strcmp(token,“}”))
{
es=statement();
if (es》0) return(es);
}
return(es);
}
//《statement》::= 《if_stat》|《while_stat》|《for_stat》
// |《compound_stat》 |《expression_stat》
int statement()
{
int es=0;
if (es==0 && strcmp(token,“if”)==0) es=if_stat();//《IF语句》
if (es==0 && strcmp(token,“while”)==0) es=while_stat();//《while语句》
if (es==0 && strcmp(token,“for”)==0) es=for_stat();//《for语句》
//可在此处添加do语句调用
if (es==0 && strcmp(token,“read”)==0) es=read_stat();//《read语句》
if (es==0 && strcmp(token,“write”)==0) es=write_stat();//《write语句》
if (es==0 && strcmp(token,“{”)==0) es=compound_stat();//《复合语句》
if (es==0 && (strcmp(token,“ID”)==0||strcmp(token,“NUM”)==0||strcmp(token,“(”)==0)) es=expression_stat();//《表达式语句》
return(es);
}
//《IF_stat》::= if (《expr》) 《statement 》 [else 《 statement 》]
/*
if (《expression》)@BRF↑label1 《statement 》 @BR↑label2 @SETlabel↓label1
[ else 《 statement 》] @SETlabel↓label2
其中动作符号的含义如下
@BRF↑label1 :输出 BRF label1,
@BR↑label2:输出 BR label2,
@SETlabel↓label1:设置标号label1
@SETlabel↓label2:设置标号label2
*/
int if_stat(){
int es=0,label1,label2; //if
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
if (strcmp(token,“(”)) return(es=5); //少左括号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=expression();
if (es》0) return(es);
if (strcmp(token,“)”)) return(es=6); //少右括号
label1=labelp++;//用label1记住条件为假时要转向的标号
fprintf(fout,“ BRF LABEL%d/n”,label1);//输出假转移指令
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=statement();
if (es》0) return(es);
label2=labelp++;//用label2记住要转向的标号
fprintf(fout,“ BR LABEL%d/n”,label2);//输出无条件转移指令
fprintf(fout,“LABEL%d:/n”,label1);//设置label1记住的标号
if (strcmp(token,“else”)==0)//else部分处理
{
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=statement();
if (es》0) return(es);
}
fprintf(fout,“LABEL%d:/n”,label2);//设置label2记住的标号
return(es);
}
//《while_stat》::= while (《expr 》) 《 statement 》
//《while_stat》::=while @SET↑labellabel1(《expression》) @BRF↑label2
// 《statement 》@BR↑label1 @SETlabel↓label2
//动作解释如下:
//@SETlabel↑label1:设置标号label1
//@BRF↑label2 :输出 BRF label2,
//@BR↑label1:输出 BR label1,
//@SETlabel↓label2:设置标号label2
int while_stat()
{
int es=0,label1,label2;
label1=labelp++;
fprintf(fout,“LABEL%d:/n”,label1);//设置label1标号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
if (strcmp(token,“(”)) return(es=5); //少左括号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=expression();
if (es》0) return(es);
if (strcmp(token,“)”)) return(es=6); //少右括号
label2=labelp++;
fprintf(fout,“ BRF LABEL%d/n”,label2);//输出假转移指令
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=statement();
if (es》0) return(es);
fprintf(fout,“ BR LABEL%d/n”,label1);//输出无条件转移指令
fprintf(fout,“LABEL%d:/n”,label2);//设置label2标号
return(es);
}
//《for_stat》::= for(《expr》,《expr》,《expr》)《statement》
/*
《for_stat》::=for (《expression》;
@SETlabel↓label1《 expression 》@BRF↑label2@BR↑label3;
@SETlabel↓label4 《 expression 》@BR↑label1)
@SETlabel↓label3 《语句 》@BR↑label4@SETlabel↓label2
动作解释:
1. @SETlabel↓label1:设置标号label1
2. @BRF↑label2 :输出 BRF label2,
3. @BR↑label3:输出 BR label3,
4. @SETlabel↓label4:设置标号label4
5. @BR↑label1:输出 BR label1,
6. @SETlabel↓label3:设置标号label3
7. @BR↑label4:输出 BR label4,
8. @SETlabel↓label2:设置标号label2
*/
int for_stat()
{
int es=0,label1,label2,label3,label4;
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
if (strcmp(token,“(”)) return(es=5); //少左括号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=expression();
if (es》0) return(es);
if (strcmp(token,“;”)) return(es=4); //少分号
label1=labelp++;
fprintf(fout,“LABEL%d:/n”,label1);//设置label1标号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=expression();
if (es》0) return(es);
label2=labelp++;
fprintf(fout,“ BRF LABEL%d/n”,label2);//输出假条件转移指令
label3=labelp++;
fprintf(fout,“ BR LABEL%d/n”,label3);//输出无条件转移指令
if (strcmp(token,“;”)) return(es=4); //少分号
label4=labelp++;
fprintf(fout,“LABEL%d:/n”,label4);//设置label4标号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=expression();
if (es》0) return(es);
fprintf(fout,“ BR LABEL%d/n”,label1);//输出无条件转移指令
if (strcmp(token,“)”)) return(es=6); //少右括号
fprintf(fout,“LABEL%d:/n”,label3);//设置label3标号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=statement();
if (es》0) return(es);
fprintf(fout,“ BR LABEL%d/n”,label4);//输出无条件转移指令
fprintf(fout,“LABEL%d:/n”,label2);//设置label2标号
return(es);
}
//《write_stat》::=write 《expression》;
//《write_stat》::=write 《expression》@OUT;
//动作解释:
//@ OUT:输出 OUT
int write_stat()
{
int es=0;
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=expression();
if (es》0)return(es);
if (strcmp(token,“;”)) return(es=4); //少分号
fprintf(fout,“ OUT/n”);//输出指令
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
return(es);
}
//《read_stat》::=read ID;
//《read_stat》::=read ID↑n LOOK↓n↑d @IN@STI↓d;
//动作解释:
//@LOOK↓n↑d:查符号表n,给出变量地址d; 没有,变量没定义
//@IN:输出IN
//@STI↓d:输出指令代码STI d
int read_stat()
{
int es=0,address;
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
if (strcmp(token,“ID”)) return(es=3); //少标识符
es=lookup(token1,&address);
if (es》0) return(es);
fprintf(fout,“ IN /n”);//输入指令
fprintf(fout,“ STI %d/n”,address);//指令
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
if (strcmp(token,“;”)) return(es=4); //少分号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
return(es);
}
//《compound_stat》::={《statement_list》}
int compound_stat(){ //复合语句函数
int es=0;
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=statement_list();
return(es);
}
//《expression_stat》::=《expression》;|;
int expression_stat()
{
int es=0;
if (strcmp(token,“;”)==0)
{
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
return(es);
}
es=expression();
if (es》0) return(es);
if (strcmp(token,“;”)==0)
{
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
return(es);
} else
{
es=4;
return(es);//少分号
}
}
//《expression》::=ID↑n@LOOK↓n↑d@ASSIGN=《bool_expr》@STO↓d |《bool_expr》
int expression()
{
int es=0,fileadd;
char token2[20],token3[40];
if (strcmp(token,“ID”)==0)
{
fileadd=ftell(fp); //@ASSIGN记住当前文件位置
fscanf(fp,“%s %s/n”, &token2,&token3);
printf(“%s %s/n”,token2,token3);
if (strcmp(token2,“=”)==0) //‘=’
{
int address;
es=lookup(token1,&address);
if (es》0) return(es);
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=bool_expr();
if (es》0) return(es);
fprintf(fout,“ STO %d/n”,address);
} else
{
fseek(fp,fileadd,0); //若非‘=’则文件指针回到‘=’前的标识符
printf(“%s %s/n”,token,token1);
es=bool_expr();
if (es》0) return(es);
}
} else es=bool_expr();
return(es);
}
//《bool_expr》::=《additive_expr》
// |《 additive_expr 》(》|《|》=|《=|==|!=)《 additive_expr 》
/*
《bool_expr》::=《additive_expr》
|《 additive_expr 》》《additive_expr》@GT
|《 additive_expr 》《《additive_expr》@LES
|《 additive_expr 》》=《additive_expr 》@GE
|《 additive_expr 》《=《 additive_expr 》@LE
|《 additive_expr 》==《 additive_expr 》@EQ
|《 additive_expr 》!=《 additive_expr 》@NOTEQ
*/
int bool_expr()
{
int es=0;
es=additive_expr();
if(es》0) return(es);
if ( strcmp(token,“》”)==0 || strcmp(token,“》=”)==0
||strcmp(token,“《”)==0 || strcmp(token,“《=”)==0
||strcmp(token,“==”)==0|| strcmp(token,“!=”)==0)
{
char token2[20];
strcpy(token2,token);//保存运算符
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=additive_expr();
if(es》0) return(es);
if ( strcmp(token2,“》”)==0 ) fprintf(fout,“ GT/n”);
if ( strcmp(token2,“》=”)==0 ) fprintf(fout,“ GE/n”);
if ( strcmp(token2,“《”)==0 ) fprintf(fout,“ LES/n”);
if ( strcmp(token2,“《=”)==0 ) fprintf(fout,“ LE/n”);
if ( strcmp(token2,“==”)==0 ) fprintf(fout,“ EQ/n”);
if ( strcmp(token2,“!=”)==0 ) fprintf(fout,“ NOTEQ/n”);
}
return(es);
}
//《additive_expr》::=《term》{(+|-)《 term 》}
//《 additive_expr》::=《term》{(+《 term 》@ADD |-《项》@SUB)}
int additive_expr()
{
int es=0;
es=term();
if(es》0) return(es);
while (strcmp(token,“+”)==0 || strcmp(token,“-”)==0)
{
char token2[20];
strcpy(token2,token);
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=term();
if(es》0) return(es);
if ( strcmp(token2,“+”)==0 ) fprintf(fout,“ ADD/n”);
if ( strcmp(token2,“-”)==0 ) fprintf(fout,“ SUB/n”);
}
return(es);
}
//《 term 》::=《factor》{(*| /)《 factor 》}
//《 term 》::=《factor》{(*《 factor 》@MULT | /《 factor 》@DIV)}
int term()
{
int es=0;
es=factor();
if(es》0) return(es);
while (strcmp(token,“*”)==0 || strcmp(token,“/”)==0)
{
char token2[20];
strcpy(token2,token);
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=factor();
if(es》0) return(es);
if ( strcmp(token2,“*”)==0 ) fprintf(fout,“ MULT/n”);
if ( strcmp(token2,“/”)==0 ) fprintf(fout,“ DIV/n”);
}
return(es);
}
//《 factor 》::=(《additive_expr》)| ID|NUM
//《 factor 》::=(《 expression 》)| ID↑n@LOOK↓n↑d@LOAD↓d |NUM↑i@LOADI↓i
int factor()
{
int es=0;
if (strcmp(token,“(”)==0)
{
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
es=expression();
if (es》0) return(es);
if (strcmp(token,“)”)) return(es=6); //少右括号
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
} else
{
if (strcmp(token,“ID”)==0)
{
int address;
es=lookup(token1,&address);//查符号表,获取变量地址
if (es》0) return(es);//变量没声明
fprintf(fout,“ LOAD %d/n”,address);
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
return(es);
}
if (strcmp(token,“NUM”)==0)
{
fprintf(fout,“ LOADI %s/n”,token1);
fscanf(fp,“%s %s/n”,&token,&token1);
printf(“%s %s/n”,token,token1);
return(es);
}else
{
es=7;//缺少操作数
return(es);
}
}
return(es);
}
//主程序
void main(){
int es=0;
es=TESTscan();//调词法分析
if (es》0) printf(“词法分析有错,编译停止!”);
else printf(“词法分析成功!/n”);
if (es==0)
{
es=TESTparse(); //调语法、语义分析并生成代码
if (es==0) printf(“语法、语义分析并生成代码成功!/n”);
else printf(“语法、语义分析并生成代码错误!/n”);
}
}
下面我们可以进行测试:如下我挑了几个典型的。大家可以看看。
下面就是一个从高级语言到低级语言的转变过程:
Lexical.txt:
{
int a;
int bb;
/*this is a test*/
a=20;
bb=10*a;
}
Grammar.txt:
{ {
int int
ID a
; ;
int int
ID bb
; ;
ID a
= =
NUM 20
; ;
ID bb
= =
NUM 10
* *
ID a
; ;
} }

Translation.txt:
LOADI 20
STO 0
LOADI 10
LOAD 0
MULT
STO 1
STOP
从前面的图中我们可以看到a对应的内存地址单元为0,b为1。LOADI 20 读入20这个立即数, STO 0将20存入内存地址为0的 单元,LOADI 10 读入10这个立即数。读出内存地址为0的单元内容,MULT 进行乘法运算,STO 1 存入内存地址为1的单元。STOP 程序运行结束。
下面是程序部分在VC内的内存存储:
- code 0x0012a028
+ [0] 0x0012a028 “LOADI”
+ [1] 0x0012a03c “20”
+ [2] 0x0012a050 “STO”
+ [3] 0x0012a064 “0”
+ [4] 0x0012a078 “LOADI”
+ [5] 0x0012a08c “10”
+ [6] 0x0012a0a0 “LOAD”
+ [7] 0x0012a0b4 “0”
+ [8] 0x0012a0c8 “MULT”
+ [9] 0x0012a0dc “STO”
+ [10] 0x0012a0f0 “1”
+ [11] 0x0012a104 “STOP”
+ [12] 0x0012a118 “*****”
- [0] 0x0012a028 “LOADI”
[0] 0x4c ‘L’
[1] 0x4f ‘O’
[2] 0x41 ‘A’
[3] 0x44 ‘D’
[4] 0x49 ‘I’
[5] 0x00 ‘’
[6] 0xcc ‘?
[7] 0xcc ’?
[8] 0xcc ‘?
[9] 0xcc ’?
[10] 0xcc ‘?
[11] 0xcc ’?
[12] 0xcc ‘?
[13] 0xcc ’?
[14] 0xcc ‘?
[15] 0xcc ’?
[16] 0xcc ‘?
[17] 0xcc ’?
[18] 0xcc ‘?
[19] 0xcc ’?
+ [1] 0x0012a03c “20”
//《for_stat》::= for(《expr》,《expr》,《expr》)《statement》
/*
《for_stat》::=for (《expression》;
@SETlabel↓label1《 expression 》@BRF↑label2@BR↑label3;
@SETlabel↓label4 《 expression 》@BR↑label1)
@SETlabel↓label3 《语句 》@BR↑label4@SETlabel↓label2
动作解释:
1. @SETlabel↓label1:设置标号label1
2. @BRF↑label2 :输出 BRF label2,
3. @BR↑label3:输出 BR label3,
4. @SETlabel↓label4:设置标号label4
5. @BR↑label1:输出 BR label1,
6. @SETlabel↓label3:设置标号label3
7. @BR↑label4:输出 BR label4,
8. @SETlabel↓label2:设置标号label2
*/
{
int a;
int b;
a=0;
b=0;
for(a=0;a《=10;a=a+1)
{
b=b+a;
}
}
词法分析
{ {
int int
ID a
; ;
int int
ID b
; ;
ID a
= =
NUM 0
; ;
ID b
= =
NUM 0
; ;
for for
( (
ID a
= =
NUM 0
; ;
ID a
《= 《=
NUM 10
; ;
ID a
= =
ID a
+ +
NUM 1
) )
{ {
ID b
= =
ID b
+ +
ID a
; ;
} }
} }
语义分析:
LOADI 0
STO 0
LOADI 0
STO 1
LOADI 0
STO 0
LABEL0:
LOAD 0
LOADI 10
LE
BRF LABEL1
BR LABEL2
LABEL3:
LOAD 0
LOADI 1
ADD
STO 0
BR LABEL0
LABEL2:
LOAD 1
LOAD 0
ADD
STO 1
BR LABEL3
LABEL1:
STOP
//《IF_stat》::= if (《expr》) 《statement 》 [else 《 statement 》]
/*
if (《expression》)@BRF↑label1 《statement 》 @BR↑label2 @SETlabel↓label1
[ else 《 statement 》] @SETlabel↓label2
其中动作符号的含义如下
@BRF↑label1 :输出 BRF label1,
@BR↑label2:输出 BR label2,
@SETlabel↓label1:设置标号label1
@SETlabel↓label2:设置标号label2
*/
IF
If.txt
{
int a;
a=3;
if(a!=1)
{
a=1;
}
}
Ifp.txt
{ {
int int
ID a
; ;
ID a
= =
NUM 3
; ;
if if
( (
ID a
!= !=
NUM 1
) )
{ {
ID a
= =
NUM 1
; ;
} }
} }
Ift.txt
LOADI 3
STO 0
LOAD 0
LOADI 1
NOTEQ
BRF LABEL0
LOADI 1
STO 0
BR LABEL1
LABEL0:
LABEL1:
STOP
While
//《while_stat》::= while (《expr 》) 《 statement 》
//《while_stat》::=while @SET↑labellabel1(《expression》) @BRF↑label2
// 《statement 》@BR↑label1 @SETlabel↓label2
//动作解释如下:
//@SETlabel↑label1:设置标号label1
//@BRF↑label2 :输出 BRF label2,
//@BR↑label1:输出 BR label1,
//@SETlabel↓label2:设置标号label2
While.txt
{
int a;
a=0;
while(a《5)
{
a=a+1;
}
}
Whilep.txt
{ {
int int
ID a
; ;
ID a
= =
NUM 0
; ;
while while
( (
ID a
《 《
NUM 5
) )
{ {
ID a
= =
ID a
+ +
NUM 1
; ;
} }
} }
Whilet.txt
LOADI 0
STO 0
LABEL0:
LOAD 0
LOADI 5
LES
BRF LABEL1
LOAD 0
LOADI 1
ADD
STO 0
BR LABEL0
LABEL1:
STOP
Wirte
{
int a;
a=10;
write a;
}
//语义
LOADI 10
STO 0
LOAD 0
OUT
STOP
Read
{
int a;
a=1;
read a;
}
LOADI 1
STO 0
IN
STI 0
STOP
在如上的分析后,我们就看到其已经转换为类似汇编语言格式的语言。结合前面的精简计算机系统,这样我们就可以明白了它是怎么在计算机中运行的了。在孙悦红的书中还有Test语言的模拟机。大家可以看看,其实程序的基本运行原理也是类似。
Lexical.txt:
{
int a;
int bb;
/*this is a test*/
a=20;
bb=10*a;
}
Grammar.txt:
{ {
int int
ID a
; ;
int int
ID bb
; ;
ID a
= =
NUM 20
; ;
ID bb
= =
NUM 10
* *
ID a
; ;
} }
Lexical.txt:
{
int a;
int bb;
/*this is a test*/
a=20;
bb=10*a;
}
Grammar.txt:
{ {
int int
ID a
; ;
int int
ID bb
; ;
ID a
= =
NUM 20
; ;
ID bb
= =
NUM 10
* *
ID a
; ;
} }
Lexical.txt:
{
int a;
int bb;
/*this is a test*/
a=20;
bb=10*a;
}
Grammar.txt:
{ {
int int
ID a
; ;
int int
ID bb
; ;
ID a
= =
NUM 20
; ;
ID bb
= =
NUM 10
* *
ID a
; ;
} }
最后,我们来看看前面的for循环在BC下的编译结果如下:
从#1#8开始:

这样,我们就大概明白和了解了编译的基本原理了。
从上面的翻译看来和我们前面的翻译有点区别,这就是实际的使用了。
编译原理语法分析总结:
语法分析是编译原理的核心部分。语法分析的作用是识别由词法分析给出的单词符号序列是否是给定文法的正确句子,目前语法分析常用的方法有自顶向下分析和自底向上分析两大类。自顶向下分析包括确定分析和不确定分析,自底向上分析又包括算符优先分析法和LR分析,这些分析方法各有优缺点。下面分别就自顶向下语法分析方法和自底向上语法分析方法展开描述:
A. 自顶向下语法分析方法
自顶向下分析法也称面向目标的分析方法,也就是从文法的开始符号出发企图推导出与输入的单词串完全相匹配的句子,若输入串是给定文法的句子,则必能推出,反之必然出错。自顶向下的确定分析方法需对文法有一定的限制,但由于实现方法简答、直观,便于手工构造或自动生成语法分析器,因而仍是目前常用的方法之一。而自顶向下的不确定分析方法是带回溯的分析方法,这种方法实际上是一种穷举的试探方法,因此效率低,代价高,因而极少使用。
LL(1)分析
自顶向下的确定分析方法,是从文法的开始符号出发,考虑如何根据当前的输入符号(单词符号)唯一地确定选用哪个产生式替换相应非终结符以往下推导,或如何构造一棵相应的语法树。当我们需要选用自顶向下的确定分析技术时,首先必须判别所给文法是否是LL(1)文法。因而对所给文法需计算FIRST、FOLLOW、SELECT集合,进而判别文法是否为LL(1)文法。LL(1)文法表示了自顶向下方法能够处理的一类文法。LL(1)第一个“L”表示从左向右扫描输入,第二个“L”表示产生最左推导,而“1”则表示每一步中只需要向前看一个输入符号来决定语法分析动作。类似也可以有LL(k)文法,也就是需向前查看k个符号才可以确定选用哪个产生式。通常采用k=1,个别情况采用k=2。LL(1)文法已经足以描述大多数程序设计语言构造,虽然在为源语言设计适当的文法时需要多加小心。比如,左递归的文法和二义性的文法都不可能是LL(1)的。一个文法G是LL(1)的,当且仅当G的任意两个不同的产生式A-》α|β满足下面的条件:
1) 不存在终结符号a使得α和β都能够推导出以a开头的串。
2) α和β中最多只有一个可以推导出空串。
3) 如果βÞ*ε,那么α不能推导出任何以FOLLOW(A)中某个终结符号开头的串。类似地,如果αÞ*ε,那么β不能推导出任何以FOLLOW(A)中某个终结符号开头的串。
我们知道当文法不满足LL(1)时,则不能用确定的自顶向下分析,但在这种情况下可用不确定的自顶向下分析,也就是带回溯的自顶向下分析。引起回溯的原因是在文法中当关于某个非终结符的产生式有多个候选时,而面临当前的输入符无法确定选用唯一的产生式,从而引起回溯。引起回溯的情况大致有3种:
1) 由于相同的左部的产生式的右部FIRST集交集不为空而引起回溯;
2) 由于相同左部非终结符的右部存在能Þ*ε的产生式,且该非终结符的FOLLOW集中含有其他产生式右部FIRST集的元素;
3) 由于文法含有左递归而引起回溯。
B. 自底向上语法分析方法
自底向上分析,也称移近-归约分析,粗略地说它的实现思想是对输入符号串自左向右进行扫描,并将输入符逐个移入一个后进先出栈中,边移入边分析,一旦栈顶符号串形成某个句型的句柄或可归约串时(该句柄或可归约串对应某产生式的右部),就用该产生式的左部非终结符代替相应右部的文法符号串,这称为一步归约。重复这一过程直到归约到栈中只剩文法的开始符号时则为分析成功,也就确认输入串是文法的句子。
目前最流行的自底向上语法分析器都基于所谓的LR(k)语法分析的概念。其中,“L”表示对输入进行从左到右的扫描,“R”表示反向构造出一个最右推导序列,而k表示在做出语法分析决定时向前看k个输入符号。
LR语法分析技术优点:
1. 对于几乎所有的程序设计语言构造,只要能够写出该构造的上下文无关文法,就能够构造出识别该构造的LR语法分析器。确实存在非LR的上下文无关文法,但一般来说,常见的程序设计语言构造都可以避免使用这样的文法。
2. LR语法分析方法是已知的最通用的无回溯移入-归约分析技术,并且它的实现可以和其他更原始的移入-归约方法一样高效。
3. 一个LR语法分析器可以在对输入进行从左到右扫描时尽可能早地检测到错误。
4. 可以使用LR方法进行语法分析的文法类是可以使用预测方法或LL方法进行语法分析的文法类的真超集。一个文法是LR(k)的条件是当我们在一个最右句型中看到某个产生式的右部时,我们再向前看k个符号就可以决定是否使用这个产生式进行归约。这个要求比LL(k)文法的要求宽松很多。对于LL(k)文法,我们在决定是否使用某个产生式时,只能向前看该产生式右部推导出的串的前k个符号。因此,LR文法能够比LL文法描述更多的语言就一点也不奇怪了。
LR方法的主要缺点是为了一个典型的程序设计语言文法手工构造LR分析器的工作量非常大,k愈大构造愈复杂,实现比较困难。常见的LR方法有LR(0)、SLR(1)、LALR(1)和LR(1),其中SLR(1)和LALR(1)分别是LR(0)和LR(1)的一种改进。下面主要介绍这四种LR分析方法:
1. LR(0)分析
LR(0)分析器是在分析过程中不需向右查看输入符号,因而它对文法的限制较大,对绝大多数高级语言的语法分析器是不能适用的,然而,它是构造其他LR类分析器的基础。LR(0)分析表构造的思想和方法是构造其他LR分析表的基础,它是LR(0)分析器的重要组成部分,它是总控程序分析动作的依据。对于不同的文法,LR(0)分析表不同,它可以用一个二维数组表示,行标为状态号,列标为文法符号和“#”号,分析表的内容可由两部分组成,一部分为动作(ACTION)表,它表示当前状态下所面临输入符应做的动作是移近、归约、接受或出错,动作表的行标只包含终结符和“#”,另一部分为转换(GOTO)表,它表示在当前状态下面临文法符号时应转向的下一个状态,相当于识别活前缀的有限自动机DFA 的状态转换矩阵。我们知道LR(0)对文法的限制较大,它要求对一个文法的LR(0)项目集规范族不存在移近-归约,或归约-归约冲突。所谓移近-归约冲突也就是在一个项目集中移近和归约项目同时存在,而归约-归约冲突是在一个项目集中归约和归约项目同时存在。
2. SLR(1)分析
由于大多数实用的程序设计语言的文法不能满足LR(0)文法的条件,经过改进后得到了一种新的SLR(1)文法,其思想是基于容许LR(0)规范族中有冲突的项目集(状态)用向前查看一个符号的办法来进行处理,已解决冲突。因为只有对有冲突的状态才向前查看一个符号,以确定做哪种动作,所以称这种分析方法为简单的LR(1)分析法,用SLR(1)表示。通常对于LR(0)规范族的一个项目集I可能含有多个项目和多个归约项目,假设项目集I中有m个移近项目:A1-》α1 •α1β1,A2-》α2 •α2β2,… , Am-》αm •αmβm;同时含有n个归约项目为:B1-》γ1• ,B1-》γ1• , … ,Bn-》γn• 只要集合{α1 ,α2 ,… ,αm}和FOLLOW(B1),FOLLOW(B2),… ,FOLLOW(Bn)两两交集都为空,那么我们可以考察当前输入符号决定动作,解决冲突。尽管采用SLR(1)方法能够对某些LR(0)项目集规范族中存在动作冲突的项目集,通过用向前查看一个符号的办法来解决冲突,但是仍有很多文法构造的LR(0)项目集规范族存在的动作冲突不能用SLR(1)方法解决。当集合{α1 ,α2 ,… ,αm}和FOLLOW(B1),FOLLOW(B2),… ,FOLLOW(Bn)之间存在交集不为空的情况,则不能根据当前输入符号决定动作,存在动作冲突。
3. LR(1)分析
可以看出SLR(1)方法虽然相对LR(0)有所改进,但仍然存在着多余归约,也说明SLR(1)方法向前查看一个符号的方法仍不够确切,LR(1)方法恰好是要解决SLR(1)方法在某些情况下存在的无效归约问题。LR(1)对比SLR(1)而言,多了向前搜索符这个概念。根据项目集构造原则有:若[A-》α•Bβ] ∈项目集I时。则[B-》•γ]也∈I(B-》γ为一产生式)。由此不妨考虑,把FIRST(β)作为用产生式B-》γ归约的搜索符,称为向前搜索符,作为归约时查看的符号集合用以代替SLR(1)分析中的FOLLOW集,把此搜索符号的集合也放在相应项目的后面,这种处理方法即为LR(1)方法。在多数情况下,对LR(1)的归约项目不存在任何无效归约,但同一个文法的LR(1)项目集的个数比LR(0)项目集的个数多,甚至可能多好几倍。这是由于同一个LR(0)项目集的搜索符集合不同,多个搜索符集合则对应着多个LR(1)项目集。这可以看成是LR(1)项目集的构造使某些同心集进行了分裂,因而项目集的个数增多了。如果一个文法的LR(1)分析表不含多重入口时,(即任何一个LR(1)项目集中无移近-归约冲突或归约-归约冲突),则称该文法为LR(1)文法。LR(1)文法已能满足当前绝大多数高级语言编译程序的需要。
4. LALR(1)分析
LR(1)分析表的构造对搜索符的计算方法比较确切,对文法放宽了要求,也就是适应的文法类广,可以解决SLR(1)方法解决不了的问题,但是,由于它的构造对某些同心集的分裂可能对状态数目引起剧烈的增长,从而导致存储容量的急剧增长,也使应用受到了一定的限制,为了克服LR(1)的这种缺点,我们可以采用对LR(1)项目集规范族合并同心集的方法,若合并同心集后不产生新的冲突,则为LALR(1)项目集。它的状态个数与LR(0)、SLR(1)的相同。关于合并同心集有几个问题需要说明:1)同心集是指心相同的项目集合并在一起,因此同心集合并后心仍然相同,只是超前搜索符集合为各同心集超前搜索符集合的合集;2)对于合并同心集后的项目集经转换函数所达仍为同心集;3)若文法是LR(1)文法,合并同心集后若有冲突也只可能是归约-归约冲突,而不可能产生移近-归约冲突;4)合并同心集后对某些错误发现的时间会产生推迟现象,但错误的出现位置仍是准确的。这意味着LALR(1)分析表比LR(1)分析表对同一输入串的分析可能会有多余归约。
-
ROC-RK3308主板CC固件编译的知识点解析,绝对实用2022-03-09 0
-
keil编译错误解析2013-09-17 0
-
LLVM编译器编译过程2019-04-28 0
-
编译器生成的map和htm文件解析2021-08-03 0
-
怎样去解析编译器生成的map和htm文件2021-09-30 0
-
C语言入门教程-C程序编译过程解析2009-07-29 874
-
C++的G代码解析算法研究2016-07-21 1937
-
嵌入式交叉编译环境的搭建解析2017-10-18 836
-
arm-linux的交叉编译环境解析2017-10-31 755
-
基于FPGA处理器的C编译指令2017-11-18 2459
-
Linux下如何编译C程序?2020-09-20 4176
-
解析C语言编译过程中所做的工作2021-06-27 2885
-
四个方面全面解析Linux 下 C++ 编译&链接2021-08-27 5259
-
一文走进SQL编译-语义解析2023-06-18 488
-
更快的tsv解析代码分享2023-12-29 195
全部0条评论

快来发表一下你的评论吧 !
