

超参数优化方法PBT的原理和功效解读
电子说
描述
近日,DeepMind在论文Population Based Training of Neural Networks中提出了一种超参数优化方法,在沿用传统随机搜索的并行训练的同时,从GA算法中获得灵感引入了从其他个体复制参数更新迭代的做法,效果显著。据官方称,使用这种名为PBT的方法可大幅提高计算机资源利用效率,训练更稳定,模型性能也更好。
从围棋到雅达利游戏到图像识别和语言翻译,神经网络在各领域都取得了极大的成功。但经常被忽视的一点是,神经网络在特定应用中的成功往往取决于研究开始时做出的一系列选择,包括使用何种类型的网络、训练数据和训练方法。目前,这些选择(超参数)的选取主要基于经验、随机搜索和计算机密集搜索。
在DeepMind新近发表的一篇论文中,团队提出了一种训练神经网络的新方法——Population Based Training (PBT,暂译为基于群体的训练),通过同时训练和优化一系列网络,它能帮开发者迅速选择最佳超参数和模型。
该方法其实是两种最常用的超参数优化方法的整合:随机搜索(random search)和手动调试(hand-tuning)。如果单纯使用随机搜索,神经网络群体并行训练,并在训练结束时选择性能最好的模型。一般来说,这意味着只有一小部分群体能接受良好的超参数训练,而剩下的大部分训练质量不佳,基本上只是在浪费计算机资源。
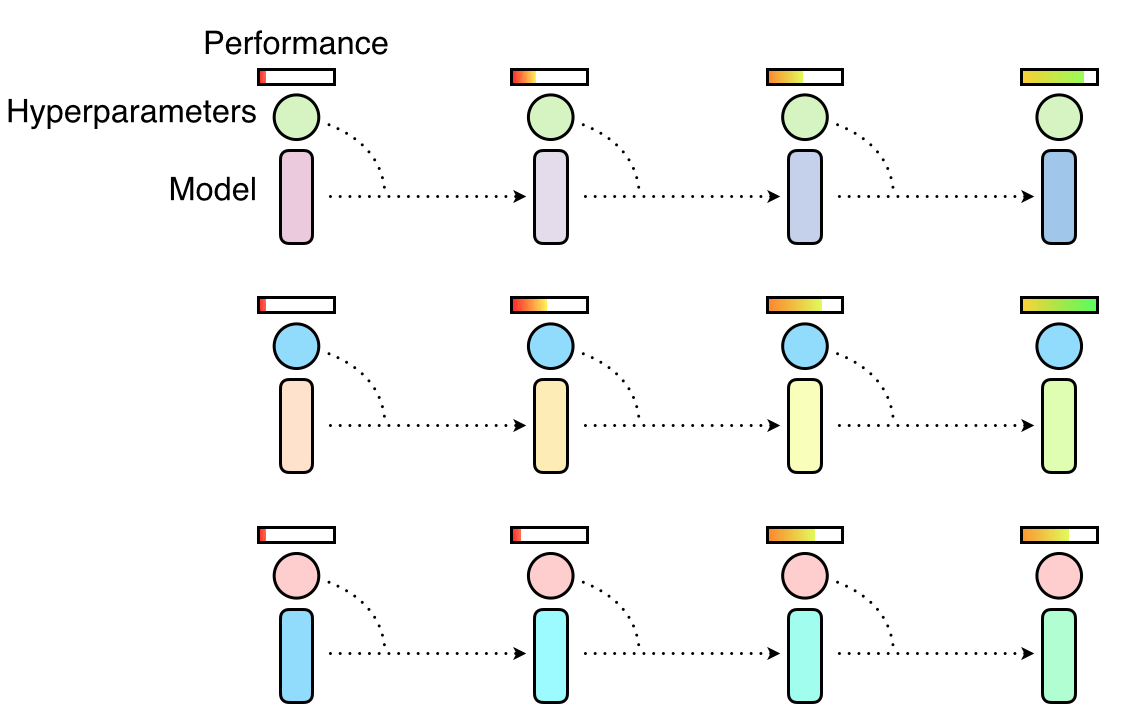
随机搜索选取超参数,超参数并行训练而又各自独立。一些超参数可能有助于建立更好的模型,但其他的不会
而如果使用的是手动调试,研究人员必须首先推测哪种超参数最合适,然后把它应用到模型中,再评估性能,如此循环往复,直到他对模型的性能感到满意为止。虽然这样做可以实现更好的模型性能,但缺点同样很突出,就是耗时太久,有时需要数周甚至数月才能完成优化。
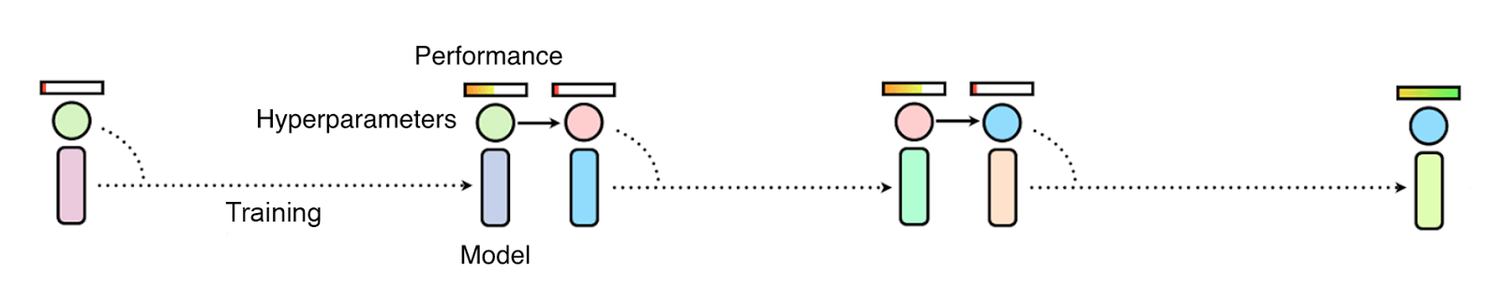
如果使用手动调试或贝叶斯优化等方法通过依次观察训练效果选取超参数,整体进度会异常缓慢
PBT结合两种方法的优势。和随机搜索一样,它首先会训练大量神经网络供随机超参数实验,但不同的是,这些网络不是独立训练的,它们会不断整合其他超参数群体的信息来进行自我完善,同时将计算资源集中给最有潜力的模型。这个灵感来自遗传算法(GA),在GA中,每个个体(候选解)能通过利用其他个体的参数信息进行迭代,如,一个个体能从另一个性能较优的个体中复制参数模型。同理,PBT鼓励每个超参数通过随机更改当前值来探索形成新的超参数。
随着对神经网络训练的不断深入,这个开发和探索的过程是定期进行的,以确保所有超参数都有一个良好的基础性能,同时,新超参数也在不断形成。这意味着PBT可以迅速选取优质超参数,并把更多的训练时间投入到最有潜力的模型中,最关键的是,它还允许在训练过程中调整超参数值,从而自动学习最佳配置。
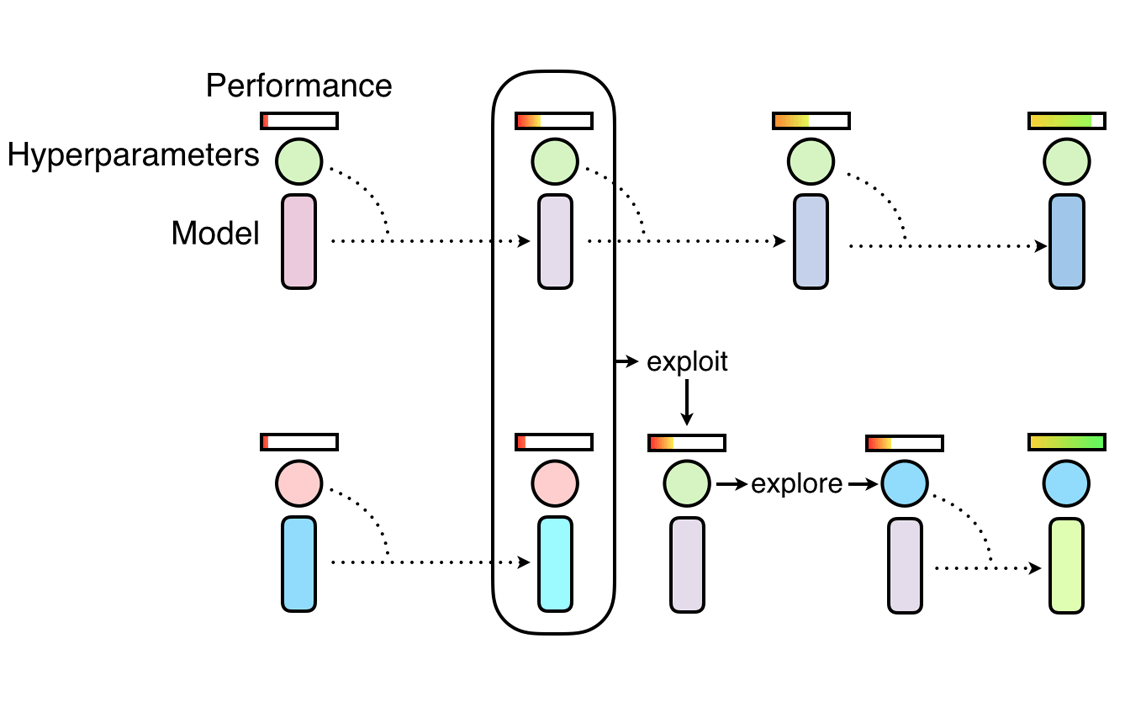
PBT的神经网络训练从随机搜索开始,但允许个体利用其他个体的部分结果,并随着训练的进行探索形成新超参数
为了测试PBT的效果,DeepMind做了一些实验。如研究人员在DeepMind Lab、雅达利和星际2三个游戏平台上用最先进的方法测试了一套具有相当挑战性的强化学习问题。实验证明,在所有情况下,PBT都训练稳定,并且迅速找到了最佳超参数,提供了超出最新基线的结果。
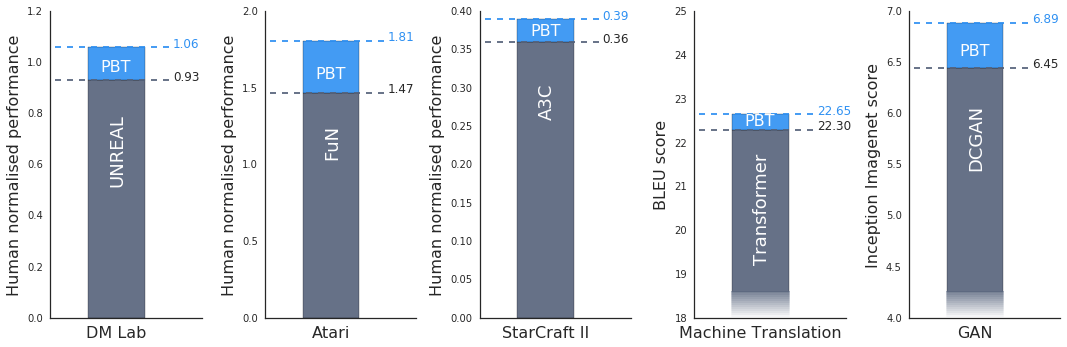
他们还发现PBT同样适用于生成对抗网络(GAN)。一般来说,GAN的超参数很难调试,但在一次实验中,DeepMind的PBT框架使模型的Inception Score(图像保真度分数)达到了新高,从6.45跃升至6.89(如上图最后一幅图所示)。
PBT也在Google的机器翻译神经网络上进行了实验。作为谷歌最先进的机翻工具,这些神经网络使用的超参数优化方法是手动调试,这意味着在投入使用前,它们需要按照研究人员精心设计的超参数时间表进行长达数月的训练。使用PBT,计算机自动建立了时间表,该训练计划所获得的模型性能和现用方法差不多,甚至更好,而且只需进行一次训练就可以获得满意的模型。
PBT在GAN和雅达利游戏“吃豆子女士”上的表现:粉色点为初代,蓝色点为末代,分支代表操作已执行(参数已复制),路径表示步骤的连续更新
DeepMind相信,这只是超参数优化方法创新的一个开始。综合论文可知,PBT对于训练引入新超参数的算法和神经网络结果特别有用,它为寻找和开发更复杂、更强大的神经网络模型提供了可能性。
- 相关推荐
- �
-
2006 年微控制器五大趋势-外围篇(微控制器基本功效解读)2009-09-24 0
-
参数模块和属性约简的应用服务器优化方法2010-04-24 0
-
微波通信天线的选择参数与优化方法综合分析2019-06-11 0
-
【免费直播】李增和大家一起学习S参数的相关知识及提取解读分析优化S参数的方法2019-11-28 0
-
改善深层神经网络--超参数优化、batch正则化和程序框架 学习总结2020-06-16 0
-
基于SMEC的PID控制器参数优化整定方法2009-03-15 512
-
蚁群算法参数优化2009-04-22 839
-
GSM系统—网络维护优化参数的提取2009-08-04 571
-
优化面向超低功耗设计的微控制器功效2010-01-06 868
-
PID调节器参数优化设计的改进方法2011-07-18 1901
-
PID调节器参数优化设计的一种改进方法2017-01-24 784
-
90度弯脚有住PBT USB-U202-ADS(铜壳)图纸2022-01-10 465
-
MEMS加速计的参数应用和解读2023-12-01 421
全部0条评论

快来发表一下你的评论吧 !
