

基于嵌入式系统设计中查找内存丢失的策略方
嵌入式操作系统
描述
在嵌入式系统设计过程中,许多软件工程师受困于动态内存管理。本文介绍一种将堆栈中的内存碎片降至最少的解决方案,其中讲到了内存碎片和内存丢失的区别,以及一种在编程中有利于检测并消除内存丢失的策略。
标准C库函数malloc()和free()可在任意的时间段中,为应用分配任意大小的内存块。随着内存块的使用和释放,在整个内存区域中,分配给堆栈的存储区将混杂着许多正在使用或已经释放的存储块,而未被使用的任何小块内存区将变得无法使用。例如,某个应用要求堆栈分配30字节,如果堆栈中只有20个长度为3字节的小存储块(总共为60字节),那么堆栈仍然无法为该应用分配内存,因为所需的30字节必须是连续的。
在执行时间较长的程序中,内存碎片可能导致系统的内存枯竭,尽管分配的内存总量并未超出总的可用内存总数。内存碎片的数量取决于堆栈的实现策略。大多数程序员均采用由编译器提供的malloc()和free()函数创建的堆栈,因此内存碎片就不受程序员的控制。
内存丢失是应用程序的缺陷,更具体地,内存丢失是一块已经分配但永远不会被释放的内存区。如果所有指向内存块的指针超出界限或者指向其他的区域,那么应用程序将永远不能释放那块内存区。对于将会在某时刻退出的桌面应用程序,较小的内存丢失还可以承受,因为退出进程将把占用的所有内存返还给操作系统。但对于长时间运行的嵌入式系统,则通常需要确保绝对没有内存丢失。
避免内存丢失不是轻而易举的,为了确保所有分配的内存都在随后释放,必须建立一套明确的规则,以确定哪个应用占用了内存。为跟踪内存,可采用类、指针数组或链表。由于在动态内存分配中,程序员无法预先知道在给定时间内需要分配多少数据块,因此通常需要采用链表结构。
在嵌入式系统设计过程中,要利用数组保存内存分配的每一个块记录,在内存块释放的同时,也将该记录从数组中删除。在主循环的每次迭代之后,分配的内存块的总数目将打印出来。理想情况下,要按类型对这些内存块排序,但指向malloc()和free()的调用则不包含任何类型信息。内存分配的大小是最好的标识,因此成为设计工程师需要记录的信息。此外,还需要存储分配的内存块地址信息,这样,当调用释放函数时,就可以方便地定位或删除块记录。

在添加和删除块记录时,还需要跟踪每种大小的内存块数目,程序的列表1给出了实现上述功能的代码。
随着内存块的分配和释放,数组:
=======================
typedef struct
{
void * address;
size_t size;
} BlockEntry;
======================
跟踪当前存在的所有内存块。另一数组则跟踪当前存在的每种大小的内存块总数:
======================
typedef struct
{
int count;
size_t size;
} Counter;
======================
函数mDisplayTable()允许我们在每次主循环结束时输出结果。如果printf()不可用,则可利用调试器中断系统并检验数组的内容。
上述代码还必须使NUM_SIZES 和 NUM_BLOCKS足够大,以处理系统中的大量内存分配;但也不能太大,从而导致在系统运行之前就已耗尽所有的RAM。
输出
快速地浏览代码,可以注意到结构类型Sensor的长度定义如下:
=======================
typedef struct
{
int offset;
int gain;
char name[10];
} Sensor;
======================
假定int为32位数据,那么Sensor的长度将为18(4+4+10),但在测试中,结果表明为20。编译器可以在存储结构的数据成员之间自由地添加填充,以将对齐强制设定为一个字边界。特殊情况下,每个字段开始于一个已存在的字边界,那么为什么还需要填充呢?填充添加在存储结构的最末端,如果声明了一个数组Sensor,那么该数组的所有成员(而不仅仅是第一个成员)将会进行字对齐。根据处理器的不同,字对齐的速度将有所差异,有时这些编译器将提供可根据速度选择字对齐长度的切换开关。在任何情形下,最好不要根据源代码的定义对存储结构的长度作任何假设。
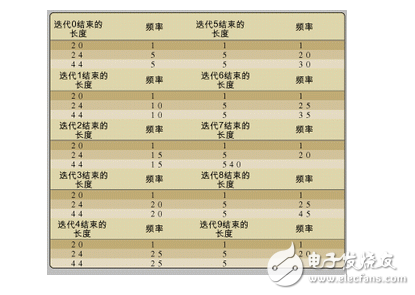

下面考察当使用这些函数时,将得到何种类型的输出。程序清单2给出了一个显示存储动态内存方式的示例。程序清单2将通常作为主外部循环的迭代了10次,并在每次迭代的末尾,调用函数mDisplay-Table()输出分配的内存块情况。
许多内存块均在初始化阶段进行分配,但我们对这些内存块并不感兴趣,因为这段代码将不会重复,因此不会产生内存丢失。由于我们并不希望这些内存分配导致分配表混乱,因此在启动感兴趣的迭代之前需要将该分配表清空。为了清空分配表,需要调用函数mClearTable()。
主循环调用的三个不同的函数
函数replacer():指示了一个用来分配内存块并且直到出现循环迭代才释放的指针。如果检验主循环中的迭代,可以发现分配的内存块并未释放。通过监控总数为20的内存块,从表1可以看出,每次迭代之后的内存块总数都为1,因此没有出现内存丢失。
函数growAndShrink():管理长度为24个结构体的链表,该链表的长度将随时间发生变化,但我们并不希望链表无限增长。通过检验总数为24的内存块,我们可以发现,虽然任意时间内存块的数目都可能发生变化,但决不会超过25个。
函数growForever():处理内存块长度为44的情形。这里我们可以非常清晰地看到,分配的内存块数目在持续增长。当首次观察该表时,可能无法找到表的源头。我们首先只能快速而粗略对mMalloc()上的条件断点进行检验,该断点只有当长度参数达到44时才触发。当到达该断点时,可以检验堆栈,以确定进行内存分配的地方。工程师完全能够多次执行这样的操作,因为这种长度的内存块可在多处进行分配。
严格地说,在函数growForever()中分配的内存不是丢失,因为所有分配的内存块均带有引用,因此理论上可以在后来释放。如果特定应用这样做,那么结果就非常明显。
长度是关键因素
当不同类型的对象共享相同长度的内存时,上述技术就不那么有效了。实际中碰到这样的情形并不多,但即便可能引发问题,仍然还有很多别的选择。
更为先进的方法则是为每个记录存储类型信息。这并不困难,但我却不愿采用这种方法,因为该方法要求为函数mMalloc()的标记添加一些新东西。我们可以定义一个列出所有可能分配的类型的枚举类型。在每次调用函数mMalloc()时,将传递一个附加的参数,并且该参数为枚举类型中的一个元素。如果在表中该参数连同地址一起被存储,那么总能识别出这类对象。
这也使得我们可以将分配长度不同,但类型相关(如可变长度的字符数组)的内存块链接起来。
C++通过使我们重载或删除按类基(per-class basis)而使得这种方法更加简便易行。尽管这是一种有效的方法,但这里我仍然不会采用这种方法,因为我更倾向采用适合C语言环境的技术。
分配位置
有时,位置信息比类型信息更为有效。幸而我们能够灵活地使用宏定义,从而无须更换标记即可选择这些信息。
==========================
#define mMalloc(size_t size)
mMallocLineNo(size, __LINE__,
__FILE__)
=========================
mMallocLineNo()函数是程序清单1中函数mMalloc()的变异。现在我们期望像程序清单3那样存储行号和文件名信息,为保持额外信息,结构BlockEntry将具有如下形式:
=========================
typedef struct
{
void * addr;
size_t size;
int line;
char * file;
} BlockEntry;
==========================
通过为每个内存块存储行号和文件名,就能精确地定位任何分配的内存块。可以为所有特定长度的表项设计一个输出行号和文件名为mDisplayLocation()的函数,这样就能轻易地识别出长度可疑的内存块的来源。
再次回到表1,可能我们会担心长度为44的内存块。为了更多地了解这些内存的来源,可以在函数main()的末尾添加如下代码:
========================
mDisplayLocation(44);
=======================
这能将行44输出50遍。
=======================
line = 162, file = listing2.c
=======================
这清晰地表明内存块在函数growForever()中分配。
可变的长度
某些内存分配的长度可以发生急剧变化,例如:
==========================
char *p = malloc(strlen(name)+1);
==========================
是分配一块足以存储字符串名和字符串截止符的内存的通用方法。在嵌入式系统中,不会经常对字符串和文件进行操作;数据结构的分配则不是这样,例如:
==========================
Motor *m = malloc(sizeof(Motor));
==========================
如果假定Motor为存储结构,那么上述分配将总是得到相同长度的内存块,在上面描述的函数中,将在输出中更简便地识别出这些内存块。
在分配可变长度内存块时,可以行号和文件名的组合为核心计算内存分配的计数。示例中,我们存储了行号和文件名,但打印的总数则取决于长度。通过行号和文件名的聚合分配将有助于在相同的位置将所有的分配组合起来,而不管分配的长度如何。某些情况下,即便可变的长度不成问题,这样的分析仍然能带给我们更多的启发。
内存表
任何含有内存丢失的代码都将导致这里给出的内存表不断增大,而且并非所有的丢失都能像growForever()示例那样清晰无误地进行识别。即便采用其它技术进行丢失检测和消除,这些输出表仍将有助于确定丢失是否已被消除。
这里给出的循环并不处理可变的输入数据。在实际项目中,通常插入一些调用(如仿真键盘敲击序列的调用)以模拟输入。在实际系统中,还必须创建一些适当的输入。除非自己希望改变代码,否则完全无须访问导致内存丢失的代码段。因此,这里的示例或许向大家提供了一个良好的开端,但任何内存丢失仍然需要进行一些检测。
内存使用率的测量
如果需要修改malloc(),理想情况下应当采用不同的名称取代所有的malloc()调用。我将其取名为mmalloc(),意即“measured malloc”。这样我们就能编写一个执行一些额外工作并调用常规malloc()的函数,这也可以通过其他途径实现,如采用#define取代malloc(),或在编译库中利用链接程序重命名malloc()函数。
这种方法的一个缺陷在于,不能对从我无法更改或重新编译的库函数中调用的malloc()进行监控。例如,标准库包含一个依次调用malloc()的函数strdup(),我们无法用malloc()调用加以取代,除非我们拥有正在使用的库的源代码。
测量使用率的第一步是简单地添加需要分配的内存并减去任何已经释放的内存。对于malloc(),这当然微不足道。假定定义了一个静态值G_inUse,那么下面的代码就能跟踪内存的分配:
==========================
void *mmalloc(size_t size){
G_inUse += size;
return malloc(size);
}
==========================
mfree()略微复杂一些,因为free()并不传递表示内存大小的变量。函数free()传递指向内存块的指针。通常表示释放内存大小的量隐藏在指针所指向数据块之前的数据头中,所以可以得到下面的函数:
==========================
void mfree(void *p)
{
size_t *sizePtr=((size_t *) p)-1;
G_inUse -= *sizePtr;
free(p);
}
==========================
因为在释放过程中或许不会使用这种转换,或者需要在略微不同的偏移位置存储表示释放内存大小的量,因此这种方法是无法移植的。
释放的内存大小或许并不与分配的内存匹配,malloc()的某些实现方法向上舍入为最接近的一个值。例如,如果要求分配11字节,而实际上却接收到了12字节。在这种情况下,12将存储在数据头中。因此分配和释放的数据块就能通过使用G_inUse-1实现平衡。
-
嵌入式系统内存管理2016-09-17 0
-
射频嵌入式系统中的噪声来源如何查找2019-06-10 0
-
【案例分享】FreeRTOS的嵌入式实时操作系统的实现2019-07-23 0
-
嵌入式系统的常规电源设计策略2019-07-26 0
-
什么是嵌入式操作系统内存管理技术?2019-07-30 0
-
嵌入式C语言程序软件中的缺陷怎么查找?2019-11-04 0
-
怎么利用混合域示波器查找出无线嵌入式系统中的噪声来源?2021-04-15 0
-
怎样才能找到导致内存丢失的代码段?2021-04-27 0
-
嵌入式操作系统中的抢占式调度策略是什么2021-04-28 0
-
嵌入式Web访问时的内存丢失的问题怎么解决?2021-04-28 0
-
嵌入式系统接口测试2021-10-27 0
-
嵌入式系统内存优化使用2021-11-04 0
-
什么是嵌入式系统?深嵌入式系统又是什么2021-12-21 0
-
嵌入式系统全程喂狗策略及实现方法2021-12-27 0
-
嵌入式Web访问时的内存丢失问题2009-11-20 515
全部0条评论

快来发表一下你的评论吧 !
